











This study adopts a comprehending theory (CT) approach towards understanding machine learning (ML) for theory and practice within the finance sector. In building on prior research, the study explores the hidden meanings of ML phenomena and connects them to the underlying financial motivation behind the actions of financial firms to create greater intellectual insight for users in practice. At its most basic, the study explores why the meaning and conception of ML is confusing and ambivalent for users in the sector. Through a scoping review, only top-tier quartile one publications between the years of 2014 to 2024 were chosen for the review with 167 articles selected for analysis. In making a significant contribution to theory, a classification framework was developed to provide greater meaning and clarification of different ML criteria. The study matches relevant CT criteria with the opportunities and challenges of ML identifying significant differences between theory and practice. The study thus substantially contributes to broadening and extending existing knowledge related to ML in the financial sector by better explaining what these gaps look like and what to do about them for future research.
The aim of this study is to identify the gaps between artificial intelligence (AI) theory and practice with a second aim to explore the challenges and opportunities of using machine learning (ML) in the financial sector. AI has been defined by Langley (2011: p. 277), as a machine learning tool for understanding the meaning of natural language, with the capacity to engage in multi-step reasoning that generates innovative artefacts and novel plans towards some type of goal achievement. To achieve the first aim, a scoping review process is used to explore the extant literature. For the second aim, a comprehending theory (CT) approach (Putnam & Banghart, 2017; Sandberg & Alvesson, 2021), was used to help explain how ML phenomena could be better understood by broadening and extending current theoretical insights related to applying ML knowledge within financial institutions. CT has been defined in terms of meaning as constitutive of organizational phenomena (Sandberg & Alvesson, 2021: p.498), which suggests that humans cannot act without having increased insight about the meaning of phenomena. Here, we applied a critical reflexive approach of important central features of ML applications in the finance sector which to date have not always been transparent for practitioners. The potential of ML models in the finance sector is continuously growing, offering opportunities to improve efficiency, accuracy, and decision-making efficiency (Pattnaik et al., 2024), in areas such as risk assessment, fraud detection, customer service automation, and algorithmic trading (Rahmani et al., 2023). However, potential opportunities also give rise to potential challenges such as data privacy concerns, algorithmic biases, and regulatory compliance issues (Cao, 2022; Gupta et al., 2025), which is discussed in more detail later. At present, the meanings of AI as organizational phenomena within the finance sector are ambiguous, situation specific, multi-layered, and constantly evolving (Sandberg & Alvesson, 2021). We believe that consequently the sector will struggle to act and respond adequately to the benefits of ML unless practitioners are able to acquire increased insight about how to apply and better interpret different AI applications.
Machine learning encompasses wide-ranging concepts within the field of computer science entailing the development of models capable of executing tasks usually associated with human intelligence (Ali et al., 2023). For instance, ML models can comprehend language, acquire knowledge from data, identify images, and increase users’ decision-making ability (Agrawal et al., 2019; Yang et al. 2024; Al-Ahmad et al., 2024). While AI development has captured users’ attention (Furman & Seamans, 2019; Brynjolfsson et al., 2021), no studies have used a CT approach to explore the meaning of AI within the financial sector context. Moreover, the fundamental principles of AI in practice are not well known despite an increasing need to better understand the meaning of AI and how to interpret ML applications across contexts (Ali & Soar, 2016). A stronger focus on how AI can be interpreted in relation to its various themes and applications for the finance sector represents an important contribution of the current study. In recent years, AI has been widely adapted across the finance, healthcare, and manufacturing industries inter alia (Ali et al., 2023a; 2023b). Reliable communication protocols as well as AI's versatility in ML is one key factor driving widespread adoption (Biallas & O'Neill, 2020; Cao, 2022), across sectors. Research suggests that using ML in the finance sector provides many benefits pertaining to risk assessment, fraud detection, investment prediction, and in better customer service (Blake et al., 2022; Storey et al., 2025). Generative AI through models such as ChatGPT enhance decision-making in financial markets by generating actionable insights (Chen et al., 2023), that can be used to select customer investments (Sai et al., 2025).
Financial services are based on sophistical AI algorithms such as internet banking, peer-to-peer financing, automated investment platforms, and payments via mobile devices (Imerman & Fabozzi, 2020; David et al., 2025). Consumers greatly benefit from such services which are convenient, effective, and economical. Financial organizations however are not always aware of the benefits of AI and ML, the processes and systems involved, and how to structure and realign conventional legacy systems with new ML applications (Kalyanakrishnan et al., 2018). While there are benefits associated with AI implementation across the finance sector, institutions have yet to fully harness the available capabilities (Yi et al., 2023). A major concern for instance of customers is the possibility of discriminatory behavior because of data bias and inadequate user group representation (Ali et al., 2014; Ashta & Herrmann, 2021). Studies suggest that excessive reliance on third-party AI providers will only exacerbate the problem (Daníelsson et al., 2022). Our findings in the current study support this view that AI-based models are not transparent and not well understood. Indeed, gaps in user expectations in the finance industry need to be addressed and systematic studies that explore the role of AI is long overdue (Cooper et al., 2019). Moreover, regular assessments of AI in the sector are required to guarantee the correctness and fairness of AI algorithms and to address rising consumer issues (Chua et al., 2023).
According to Fabri et al. (2022), there is an increasing need to better comprehend and interpret the role of AI in the investment industry. Reputational damage and a reluctance to accept AI are a case in point. Stakeholders and other investors are demanding greater transparency and accountability. Inadequate comprehension of the advantages of AI disrupts financial institutional efforts to identify and correct decision errors or biases which often result in legal and financial implications (Lee & Shin, 2020; Quach et al., 2022). While AI has resulted in rapid development and implementation across various industries and in society more generally (Abbas Khan et al., 2024; Abulkassova et al., 2025), here we generate information about the functions of AI theory and AI implementation in the financial sector.
Theoretical background to AI financeProblematizing issues related to machine learningIssues related to supervised learning ML techniquesML consists of a mapping function from input to output that utilizes supervised learning techniques. This method involves constructing and training a model by supplying it with pairs of input-output data. Various supervised learning algorithms are employed, encompassing widely recognized techniques such as linear and logistic regressions. Other learning techniques are available through decision trees, random forests, neural networks, and support vector machines (SVMs). Decision trees are methods that are applied for classification and solving regression problems that are based on tree topologies. Derived from values related to input variables, decision trees divide the data into smaller subsets that subsequently derives choices from these subsets (Kaparthi & Bumblauskas, 2020). Random forests utilize a collection of learning approaches that enhance performance and mitigate overfitting by aggregating a set of decision trees (Sipper & Moore, 2021). Neural network decision trees are interconnected multi-layer nodes, each executing fundamental computations based on inputs. These ML functions are designed on the structure and functionality of the human brain, that can be used for both regression and classification problems (Ghorbanzadeh et al., 2019). Support vector machines (SVMs) embody classification techniques to identify the optimal hyperplane that effectively partition data into separate categories (Battineni et al., 2019). ML techniques thus have applications in a variety of fields and can predict financial outcomes (Krauss et al., 2017), the management of portfolios (Kvamme et al., 2018), the appraisal of credit (Thennakoon et al., 2019), and the identification of fraudulent activity (Zhong & Enke, 2019; Bao et al., 2019).
Supervised learning technologies in ML often encounters key challenges. One prominent issue is the reliance on labeled data which can be scarce and costly to obtain, particularly in domains where expert annotation is necessary. This can lead to biased models or ineffective generalization of new data (Krenzer et al., 2022). Overfitting poses a significant concern where ML models memorize the training data instead of learning underlying patterns, resulting in inferior performance for unseen examples (López et al., 2022). Balancing model complexity to mitigate overfitting while ensuring sufficient capacity to capture intricate relationships in the data is another ongoing challenge (López et al., 2022). The quality of labels can vary introducing noise and ambiguity that can degrade ML model performance (Karimi et al., 2020). Addressing these challenges requires robust techniques for data augmentation, regularization, and model evaluation, along with careful consideration of bias and fairness to build reliable and ethically sound ML systems (González-Sendino et al., 2024; Agu et al., 2024). The rapid development and integration of AI into various facets of modern life have created a complex interplay of opportunities and ethical challenges that demand careful consideration (Ayling & Chapman, 2021; Tadimalla & Maher, 2024), such as transparency, accountability, privacy, and data protection (Mazurek & Małagocka, 2019; Novelli et al., 2024; Chaudhary, 2024).
Issues related to unsupervised ML techniquesAccording to Sarker et al. (2020), unsupervised learning is a method that involves the investigation of hidden structures and patterns within data without the use of predetermined output variables. Identifying significant relationships or patterns within a given set of data inputs is the primary objective of unsupervised learning. Unsupervised learning plays a crucial role in anomaly identification as it is used in discovering data points that drastically deviate from the norm (Torshin & Rudakov, 2015). However, it is common for unsupervised learning to require more data and more complex algorithms than supervised learning, which is more computationally costly (Barbierato & Gatti, 2024). Due to the absence of the same level of guidance that is present in supervised learning, unsupervised learning is more prone to overfitting than supervised learning (Lohrer et al., 2024). Prominent ML models employed in unsupervised learning relate to principal component analysis (PCA), and generative models such as association rule mining and auto-encoders (Harshvardhan et al., 2020). Principal component analysis (PCA) for instance is a technique employed to diminish the dimensionality of data. It achieves this by transforming data from a high-dimensional space to a lower-dimensional one while preserving essential information (Jo et al., 2020). Generative models exemplified by generative adversarial networks (GANs) and variational auto-encoders (VAEs) belong to a category of ML models capable of producing novel data resembling the input data (Harshvardhan et al., 2020). These models are used to achieve various tasks, including anomaly detection and image denoising (Choi et al., 2019). A wide range of applications are associated with unsupervised learning, such as the identification of fraudulent activity (Bao et al., 2019), the segmentation of customers (Gomes et al., 2021), the optimization of portfolios (Kedia et al., 2018), the analysis of credit risk and the study of markets (Umuhoza et al., 2020).
Unsupervised learning methodologies in ML however faces significant challenges. One primary issue is the lack of explicit supervision making it inherently difficult to evaluate the quality and correctness of learned representations or clusters of data (Barbierato & Gatti, 2024). Without labeled data to guide the learning process, determining whether the discovered patterns or structures are meaningful or spurious becomes a critical concern (Akter et al., 2022). Additionally, unsupervised methods often struggle with scalability and interpretability, particularly when dealing with high-dimensional or complex data (Karim et al., 2021). Moreover, the presence of outliers in the data can significantly impact the performance and stability of unsupervised algorithms, requiring robust techniques for outlier detection and noise handling (Lohrer et al., 2024). Overcoming these challenges necessitates the development of novel algorithms for unsupervised learning along with comprehensive learning methodologies in ML for evaluating and validating the learned representations or structures (Taye, 2023; Abbas et al., 2023).
Issues related to natural language processing (NLP)Within the realm of AI, natural language processing (NLP) is a subfield that is dedicated to endowing computers with the ability to understand, decode, and produce human language (Mei, 2022; Ruffolo, 2022; Xu, 2022). There are many practical uses of NLP within financial services, the most notable of which is the improvement of the consumer experience through the implementation of chatbots. For instance, text pre-processing refers to the process of refining and preparing raw and uncategorized text data into a format that suits the chosen analysis, reducing the data volume required for subsequent processing (Yang et al., 2016). Sentiment analysis for example is used to evaluate emotions expressed within the text using a combination of supervised and unsupervised algorithms (Fang et al., 2014; Adamopoulos et al., 2018). Named entity recognition (NER) is a process that identifies and categorizes specific elements in unstructured text into predefined groups. This process employs a range of methods from rule-based techniques to ML models to accomplish this task (Sazali et al., 2016). Another ML technique called topic modelling identifies topics or themes in a collection of textual information (Sridhar & Getoor, 2019). Machine translation entails translating material from one language to another while ensuring the accurate preservation of sentence meaning, grammar, and tense (Khurana et al., 2023). Similarly, speech recognition enables the transcription of spoken language into written text which is commonly used in many situations including interviews and chats (Chrupala, 2014).
However, several challenges in NLP remain open and continue to drive research efforts. One such challenge is the issue of bias in language models where biases in training data can lead to unfair or discriminatory outputs (Navigli, 2023). Mitigating bias in NLP models remains a crucial area of research to ensure fairness and equity. Another unresolved issue is the lack of robustness and interpretability in NLP models, particularly in complex tasks such as question/ answer prompts and natural language understanding. Despite considerable progress, NLP systems often struggle with out-of-distribution inputs and adversarial attacks, highlighting the need for more robust and interpretable models (Yuan, 2024). Achieving deeper contextual understanding and common-sense reasoning in NLP systems remains a formidable challenge as existing models often lack comprehensive world knowledge and reasoning abilities (Yu, 2023). Addressing these open challenges in NLP is crucial for realizing the full potential of NLP and in building more reliable and trustworthy NLP applications.
Despite many impressive achievements across ML models, significant challenges remain. One key issue is the need to improve the alignment between language models and human values and intentions. While the latest version of GPT-3 (called Instruct GPT) has made progress in this area, more research is required to ensure that ML models behave in ways that are consistent with human preferences (Zhang, 2023; Weber-Wulff, 2023; Ouyang, 2022). Another challenge in NLP is the need to develop models that can understand the context and nuance of human language rather than simply relying on statistical patterns. This is a prominent issue as current language models can be fooled by subtle changes in phrasing or context, and struggle to accurately interpret the intended meaning of a given piece of text (Choudhury & Asan, 2020; Kreimeyer, 2017).
Issues related to robotics process automation (RPA)RPA is becoming more important in the financial services industry as a technology to automate repetitive, rule-based processes performed by humans. According to Driscoll (2018) and Gotthardt et al. (2020), RPAs lead to the reduction of operating expenses, the enhancement of efficiency and decreases in human error, as well as improvements in the entire customer experience. RPA has significant practical application within the financial services sector. For example, the procedures involved in establishing and terminating accounts aim to simplify tasks such as inputting data, verifying identities, and processing documents (Romao et al., 2019). RPA is also used for automating various operations such as data entry and verification, and validation within claims processing resulting in reduced time and costs (Oza et al., 2020). Similarly, RPA is deployed to identify and prevent fraudulent activities. It achieves this by consistently monitoring transactions, identifying irregularities, and promptly notifying relevant stakeholders (Thekkethil et al., 2021). Similarly, RPA is used to automate customer service operations and tasks such as responding to inquiries, handling complaints, and resolving issues.
Organizations however must also be aware of potential risks to optimize their RPA investments. One challenge is unrealistic goal setting (Lok, 2021). More often, businesses set overly ambitious expectations for RPA implementation, leading to disappointment when the technology fails to deliver the promised value. Additionally, organizations that use RPA solely to reduce headcount miss the potential for innovation and process improvement (Eikebrokk & Olsen, 2020). Lack of strategic intent or end-point design can hinder successful RPA projects. Another risk lies in stakeholder buy-in. Implementing RPA requires engagement from various levels within the enterprise, including executives, IT employees, and external stakeholders (Rutaganda, 2017). IT departments may view RPA skeptically considering it low-value and unstable technology. Employees might perceive RPA as a threat to their jobs, leading to resistance or delays in implementation. Ensuring active stakeholder involvement is crucial for successful RPA adoption. Increased operational risk arises when organizations deploy robots without a proper operating model (Bu, 2022). Blurred roles, inadequate training, and insufficient resources can jeopardize RPA initiatives (Wallace, 2021). To mitigate this risk, enterprises should implement a digitally augmented workforce and define clear roles for both humans and bots.
While previously discussed challenges can be mitigated with careful management of RPA projects, there are certain unsolved challenges RPA is still facing. One unresolved issue is the complexity of automating cognitive tasks that require human-like reasoning and decision-making abilities. While RPA excels in automating rule-based processes, tasks involving unstructured data interpretation and complex decision logic remain challenging (Lyukevich et al., 2023; Sharma, 2023). As automation proliferates across organizations, this will require more adherence to regulatory standards, data privacy policies, and ethical guidelines (Kakade, 2024). Additionally, the human-robot collaboration paradigm presents challenges in managing the transition and upskilling of human workers to work alongside software robots effectively (Gervasi et al., 2024; Robinson, 2023).
Taken together, issues related to problematizing ML led to the following research question.
Research Question 1: To what extent do AI opportunities overcome the issues of applying and using ML in financial practice?
Many of the challenges of AI have been poorly matched with the social system to which they are also designed to support (He et al., 2021; Kruse et al., 2021; X. Huang et al., 2023). While ML consists of a logical progression towards machines thinking like humans, ML techniques represent digital frontiers that are not easily understood. Although ML is based on modern algorithms that have the capacity to identify intricate patterns that subsequently generate predictions or decisions without explicit programming guidance (Sarker, 2021), a better understanding of these processes and systems will increase operational skills and know-how (Juneja, 2021). Here, ML is yet to achieve the same level of human reasoning and intelligence in the same way as human thinking (Ali et al., 2021).
Identifying gaps in AI theoryGiven these AI traditions plus considerable issues in applying ML in practice, a comprehending theory (CT) approach offers a qualified understanding of phenomena that are not easily understood (Alvesson & Willmott, 2002). While the scoping review in the current study offers a process for identifying key AI themes, we broaden current scholarly contributions to the AI literature by theorizing the emerging gaps between AI theory and practice. As we discuss below, a common shared perspective of AI should result in more transparent systems and processes that are linked to how people understand the phenomena in ways where human thinking is replicated through artificial means. However, as detailed in this review, this is not always the case. Many challenges exist to which existing AI theory cannot adequately explain. Drawing from Sandberg and Alvesson (2021), a CT approach to the AI phenomenon enables scholars and practitioners to better determine hidden meanings, to identify underlying forces behind people’s actions, and to create greater intellectual insight (Reed, 2011). AI in its current form is not easy for users to comprehend. Users who anticipate a certain outcome such as speed and efficiency may be disappointed when outcomes result in unanticipated consequences. Geertz (1973) and Reed (2011) note that CT extends the action-logics of different contexts by articulating a better meaning of the phenomena within the context to which it is applied. By seeking to clarify AI theory through typification, a “significant conceptualizing could mean that a new phenomenon is being created” (Sandberg & Alvesson, 2021: p. 499). In the current paper, we hope to enlighten users’ meaning-making and sensemaking through a CT approach notably: 1) The purpose should be clear in determining the phenomenon’s meaning, 2) greater intellectual insight might enable new meaning that changes the character and nature of the phenomenon, 3) through a CT approach, an original comprehension of the meaning of AI can be challenged, 4) AI processes should be conceptually ordered through discourses, narratives, metaphors and thick descriptions, and 5) the phenomenon of AI should be informed by several layers of meaning (Putnam & Banghart, 2017; Reed, 2011). Finally, CT should facilitate a boundary condition where groups share a mutual understanding such that the phenomenon becomes credible (Sandberg & Alvesson, 2021). For instance, given the range of issues in positioning ML as a device that approximates to human thinking, various AI boundary conditions are clearly not being met. Later in this study, we match relevant CT criteria with AI emerging opportunities and challenges to determine the extent to which the phenomenon is credible and/or understood. In this study, we problematize the idea that ML techniques provide clear guidelines and greater intellectual insight for users leading to the second research question.
Research Question 2: How does a comprehending theory approach provide greater intellectual insight of the AI phenomena to help close gaps between theory and practice?
A scoping review is a systematic method employed to comprehensively identify, evaluate, and interpret all existing research relevant to a specific topic, query, or phenomenon of interest. According to Ali et al. (2023a), a scoping review provides a succinct overview of the procedures involved in gathering, organizing, and assessing literature. Based on recognizing the need to pinpoint research gaps and offer recommendations for future research, a scoping review methodology was considered highly beneficial for the present research (Anderson et al., 2020). The current study uses evidence maps to uncover gaps in knowledge (Miake-Lye et al., 2016). The prominence of scoping reviews has been growing across all fields of knowledge and are particularly prevalent for studies in information technology and finance (Kamboj & Rahman, 2015). The current review approach was based on Aromataris and Munn (2020), and the JBI manual for evidence synthesis, as well as the PRISMA-ScR checklist and explanation (Tricco et al., 2018), related to planning, implementation, and summarizing (Fig. 1).
Planning phase
The planning phase involved identifying significant gaps and opportunities between theory and practice including developing the review procedure. Procedural protocols were followed to minimize researcher bias. The Ngai and Wat (2002) framework was used to subdivide distinct categories of opportunities and challenges. Every categorical theme consisted of sub-categories that emerged from the review papers and research criteria. Fig. 2 illustrates the relevant categories and subcategories in respect of opportunities and challenges.

Classification framework.
Adapted fromNgai and Wat (2002).
The review process of identifying the advantages and disadvantages of using AI led to a total of 167 articles for analysis. This was followed by the research inquiry and article selection process respectively (Dabić et al., 2020). An intensive automated search of online databases was conducted including a manual examination of publications. Well-known databases were selected included Science Direct, Scopus, ACM digital library, IEEE, and Emerald. Following McLean and Antony (2014), suitable filtering tools were used for each database to improve quality and limit the scope of accumulating unnecessary data. The researchers conducted a thorough examination of the titles and abstracts of all articles (Golder et al., 2014). This included studying full text papers and excluding those not relevant to the search terms (Ali et al., 2021). To better illustrate the development of AI-based ML over the past decade, the exclusion procedure did not include articles published before 2014 (Table 1).
Criteria of the inclusion and exclusion process.
A backward snowballing technique was used to locate articles not identified through the scoping process. This included a reference rundown to locate these articles (Ali et al., 2023b).
Implementation phaseDuring the implementation phase, specific search terms were extracted from selected articles in the relevant field of study (Hu & Bai, 2014; Ali et al., 2018). The following keywords were identified: artificial intelligence; machine learning; natural language processing; robotics process automation; opportunities; benefits and/or advantages; and finance or financial; and challenges or issues or barriers or obstacles consistent with filtering tools to increase quality yield (Zhang et al., 2014). Other filters related to the following criteria: publication year (in English), journal articles and conference papers as source criteria, and finance and information systems as the research area between the years 2014 to 2024. The titles and abstracts of the articles were examined manually to ensure they were related to the subject matter (Pucher, 2013; Ali et al., 2018).
Summarizing phaseTable 2 illustrates the total number of articles selected for inclusion. Initially, 1276 articles were identified through the initial keyword search. After applying filters, this number was reduced to 753 articles. Subsequently, a manual review eliminated articles not relevant to the study's focus with a priority towards empirical and conceptual articles related to the study's subject matter. Consequently, 437 articles were eliminated while 316 articles were retained. Following this process, a comprehensive review of the articles was conducted focusing on the research criteria including the presentation of the results, the methodology employed, the approach taken to analyze the data, and the objectives and research questions addressed. This resulted in an additional 138 articles that were eliminated leaving 178 articles for analysis. However, the reverse snowball technique led to including an additional fourteen articles. Overall, the summarizing phase resulted in selecting 192 articles from which a further twenty-five articles were excluded. This left a total of 167 articles available for analysis (Table 2).
Implementation processes and results.
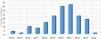
Allocation of Articles by Publication Year:Fig. 3 illustrates the distribution of selected articles based on their publication year. The year with the fewest number of articles (1) was in 2015 and 2024, while 2021 showed the greatest number of articles (36). Most articles were published between 2019 and 2022, reflecting more recent interest in AI.

Allocation of Articles in accordance with the Classification Framework: The research topic is categorized into two main groups: opportunities and challenges. This included seventy articles published within the opportunities category, while the challenges category comprised 102 articles. Integrated insights of AI theory and practice were supplied by both categories (Fig. 4).
Research classification framework
Table 3a and Table 3b present a detailed classification of research themes within the proposed framework. Table 3a categorizes studies based on their primary focus areas related to AI opportunities highlighting key domains, sub-categories, with example themes.
AI opportunities classification framework.
| Domain | Category | Sub-Category | Description | Examples | Sources |
|---|---|---|---|---|---|
| AI in the Finance Sector | AI Opportunities | Improving the Decision-Making Process | A process comprising a sequence of steps that must be undertaken to identify the optimal course of action. | • Process of credit assessment.• Process of lending.• Process of investment.• Process of credit risk assessment. | Wei et al. (2016); Gomber et al. (2017); Jarrahi (2018); Bazarbash (2019); Agarwal (2019); van Dijck and Alinejad (2020); Helberger et al. (2020); Shanmuganathan (2020); Awotunde et al. (2021); Ashta and Herrmann (2021); Chen and Ge (2021); Starnawska (2021); Ahmed et al. (2022); Königstorfer and Thalmann (2022); Galli et al. (2022). |
| Automating Key Business Processes | A system employed to minimize or eliminate human involvement, simplifying, expediting, and enhancing the accuracy of business workflows. | • Client assistance.• Financial advisory services.• Tax strategy counseling.• Establishment of a banking relationship.• Suggesting insurance coverage options.• Dispensing investment recommendations | Zeinalizadeh et al. (2015); Rehman et al. (2016); Kruse et al. (2019): Shanmuganathan (2020); Mckinsey (2020); Jha et al. (2021); Wittmann and Lutfiju (2021); Liao and Sundar (2021); Puntoni et al. (2021); Villar and Khan (2021); Jaiwani and Gopalkrishnan (2022). | ||
| Algorithmic Trading Improvement | A system that employs highly sophisticated mathematical models to make transaction decisions within financial markets. | • Equity trading.• Engaging in transactions within the foreign exchange market.• Stock trading.• Financial asset prices. | Geva and Zahavi (2014); Chen et al. (2016); Luo et al. (2019); Martinez et al. (2019); Liu et al. (2020); Milana and Ashta (2021); Cohen (2022). | ||
| Financial Forecasting Improvement | Concentrates on enhancing the prediction of a company's financial future by analyzing historical performance data. | • Consumer loan default.• Bankruptcies.• Loan defaults of SMEs.• Stock price fluctuations.• Stock market returns.• Credit risk forecasting. | Óskarsdóttir et al. (2018); Sigrist and Hirnschall (2019); Li and Mei (2020); Ruan et al. (2020); Königstorfer and Thalmann (2020); Marulanda and Sarabia (2021); Petrelli and Cesarini (2021); Ahmed et al. (2022); Doumpos et al. (2023). | ||
| Improving Compliance and Fraud Detection | Emphasizes enhancing measures for preventing and detecting fraud to mitigate risks and minimize financial losses. | • Real-time monitoring.• Financial regulatory reporting.• Unusual financial behavior.• Risk of financial irregularities.• Money laundering activities. | Böse et al. (2017); Kerkez (2020); Deshpande (2020); Canhoto (2020); Wyrobeck (2020); Polak et al. (2020); Kumar et al. (2021); Ashta and Herrmann (2021); Milana and Ashta (2021); Fabri et al. (2022); Yasir et al. (2022); Ahmed et al. (2022). | ||
| Reducing Operational Costs | Assists organizations in reducing operational costs, boosting profits, and facilitating organizational expansion. | • Reduce loan default rates.• Compliance.• Detecting financial fraud.• Labor costs.• Cost of transactions. | Patil and Kulkarni (2019); Salah et al. (2019); Barclays (2019); Königstorfer and Thalmann (2020); Kerkez (2020); Maček et al. (2020); Ashta and Herrmann (2021); Wittmann and Lutfiju (2021); Akter et al. (2022); Tiron-Tudor and Deliu (2022); Abdeljawad et al. (2022); Sundararajan (2022); Dasgupta (2023). | ||
| Strengthening Cybersecurity Resilience | Designed to enhance cyber resilience throughout the industry by establishing a reliable network of collaboration with a community of multiple stakeholders. | • Protection from social engineering.• Reduce phishing attempts.• Monitoring all emails. | Coventry and Branley (2018); Gutierrez et al. (2018); Alshamrani et al. (2019); Mashechkin et al. (2019); Ursachi (2019); Mansour (2020); Annarelli et al. (2020); Eigner et al. (2021); Mashtalyar et al. (2021); Basit et al. (2021); Saeed et al. (2023). |
AI challenges classification framework.
| Domain | Category | Sub-Category | Description | Examples | Sources |
|---|---|---|---|---|---|
| AI in the Finance Sector | AI Challenges | Poor accountability for AI Output | The outcomes generated by AI may stem from flawed training data or data that is biased and not fully representative of knowledge within the field. | • Inaccurate training data.• Biased data.• Unrepresentative data. | Syam and Sharma (2018); Canhoto and Clear (2020); Munoko et al. (2020); Toreini et al. (2020); Bonsón et al. (2021); Lee et al. (2021); Huang and Rust (2021); Reebadiya et al. (2021); Ashta and Herrmann (2021); Fabri et al. (2022); Kozodoi et al. (2022); Mhlanga (2022); Kochupillai et al. (2022). |
| Training Data Availability and Quality | An inadequate assessment of data quality may arise due to factors such as accuracy, comprehensiveness, coherence, reliability, and currency. | • Insufficient amounts of digitally available data.• Incomplete data.• Inaccurate data.• Biased data.• Inconsistent data.• Lack of various data privacy requirements. | Greenspan et al. (2016); Lee (2017); JingJing et al. (2018); Kruse et al. (2019); Arnold et al. (2019); Santosh (2020); Ashta and Herrmann (2021); Zhang and Lu (2021); Milana and Ashta (2021); Hagendorff (2021); Vetrò et al. (2021); Kernbach et al. (2022); Kolides et al. (2023); Sawhney et al. (2023); Whang et al. (2023); Kumar et al. (2023). | ||
| Lack of Appropriate Skills and Expertise | Lack of essential foundational skills and business acumen needed to fulfill requisite responsibilities in the workplace to achieve organizational objectives. | • Poor programming skills.• Poor data analytics skills.• Poor ML knowledge. | Dilsizian and Siegel (2014); Kruse et al. (2019); Polak et al. (2020); Stone et al. (2020); Humphreys et al. (2020); Janiesch et al. (2021); Juneja (2021); Tagde et al. (2021); Pai et al. (2021); He et al. (2021); Kruse et al. (2021); A.H. Huang et al. (2023). | ||
| Legacy Infrastructure | Outdated computing systems, hardware, or software that remain operational. Legacy systems encompass both computer hardware and software applications. | • Lack of processing power.• Lack of storage capacity.• Longer processing times.• Reduced accuracy.• Lack of integration. | Miloslavskaya and Tolstoy (2016); Wollschlaeger et al. (2017); Kalyanakrishnan et al. (2018); Zhou et al. (2019); Lee et al. (2019); Bohr and Memarzadeh (2020); Ryll et al. (2020); Etengu et al. (2020); Eriksson et al. (2020); von Solms (2021); Hradecky et al. (2022); Irani et al. (2023); Irani et al. (2023); Kar and Kushwaha (2023). | ||
| Data Privacy Challenges | The field of data security focuses on ensuring the appropriate management of data. In practical terms, concerns regarding data privacy often center on the manner in which data is shared with third parties. | • Losing control of the data.• Legal liabilities.• Damage to reputation. | Fire et al. (2014); Mehmood et al. (2016); Mathews (2016); Mittelstadt and Floridi (2016); Frenken and Schor (2017); Riikkinrn et al. (2018); Amiram et al. (2018); Kruse et al. (2019); Radu et al. (2020); Lee and Shin (2020)); Lukas et al. (2020); Davenport et al. (2020); Roszkowska (2021); G. Gong et al. (2021); Quach et al. (2022); Naz et al. (2022); Remeikienė and Gaspareniene (2023). | ||
| Selecting the Optimal ML Model | ML models are trained with a massive amount of data that may negatively affect model performance. | • Unsuitable algorithms.• Poor performance.• Inaccurate predictions.• Inability to solve the problem. | Zhuang et al. (2017); Lamberton et al. (2017); de Laat (2018); Cewe et al. (2018); Cooper et al. (2019); Kirchmer and Franz (2019); Yeoh (2019); Kelly et al. (2019); Lee and Shin (2020)); Zeng et al. (2022); Chua et al. (2023). | ||
| Poor Adaptability and Speed of Response | Organizations do not respond quickly enough to opportunities. | • Potential for data bias.• Issues related to security and privacy.• Complexity of AI models. | Vassakis et al. (2018); Kroll (2018); Gligor et al. (2019); Sheel and Nath (2019); Thowfeek et al. (2020); Wamba-Taguimdje et al. (2020); Holzinger et al. (2021); Rane and Narvel (2021); Enholm et al. (2022); Bhatti et al. (2022); Ishak et al. (2023); Upadhyay et al. (2023). | ||
| AI Model Development Challenges | The crucial issues that organizations might face in the process of developing AI models. | • Struggles to develop accurate models.• Struggle to develop a well-performing AI model.• Issues related to language interpretability. | Day and Lee (2016); Sohangir et al. (2018); Krommyda et al. (2020); Mishev et al. (2020); Stahl et al. (2021); Du and Xie (2021); J. Gong et al. (2021); Harsha et al. (2022); Zaman et al. (2023); Gupta et al. (2023). Osterrieder (2023); Khurana et al. (2023). |
Table 3b further refines the research classification framework by mapping the identified themes of AI challenges to their respective subcategories illustrating the depth and breadth of research coverage.
Discussion of emerging themesEmerging themes 1: opportunities of AIAI presents significant opportunities for the financial sector although successful adoption varies depending on institutional capabilities and resources (Königstorfer & Thalmann, 2022; Wittmann & Lutfiju, 2021; Kerkez, 2020). Emerging opportunities center around improving decision-making, automating processes, enhancing trading and forecasting, boosting compliance, reducing costs, and strengthening cybersecurity as illustrated in Table 3a.
Improved decision-makingIn the financial sector, AI adoption ability reflects an institutions capability to effectively understand and internalize AI's strategic potential to innovate in ways that reflect improved decision-making and operations to achieve better risk compliance and cybersecurity. Those institutions with lower capabilities to take advantage of AI will struggle however to move beyond basic implementation. Many opportunities relate to enhanced decision making across different financial instruments including credit assessment, lending decisions, and investments (Agarwal, 2019). Here, AI models are increasingly employed to automate and enhance decision-making procedures (Jarrahi, 2018), that lead to a more precise, expeditious, and well-informed decision-making framework. AI models are progressively employed for automated decision-making manifesting a substantial capacity to refine the credit risk assessment of loan applicants by leveraging diverse and often non-traditional datasets (Königstorfer & Thalmann, 2022). Robo-advisors for instance not only automate investment strategies but are also increasingly aligned with complex investment goals such as ESG principles (Shanmuganathan, 2020; Ahmed et al., 2022; Ashta & Herrmann, 2021).
Automating key business processesAs noted earlier, RPA and AI-based customer engagement systems are only successful when financial organizations grasp the broader strategic role of automation beyond simple cost-cutting. That is, AI should be extended to enhancing the customer experience and market expansion (Shanmuganathan, 2020; McKinsey, 2020). A CT approach suggests that a more thorough comprehension of AI in practice should lead firms to modernize their IT systems and strengthen real-time analytics (Huang & Kuo, 2020; Villar & Khan, 2021), rather than deploying isolated AI tools without system-wide integration This understanding extends the action-logics of financial contexts by articulating a better meaning of the phenomena within the context to which it is applied (Reed, 2011). In trading and forecasting, institutions that deeply understand AI’s capabilities for instance can better leverage ML and neural networks for strategic market advantage, minimizing emotional biases and optimizing long-term investment strategies (Milana & Ashta, 2021; Cohen, 2022; Doumpos et al., 2023).
Similarly, in compliance and fraud detection, AI can proactively predict and prevent financial crimes (Ashta & Herrmann, 2021; Canhoto, 2020; Kumar et al., 2021), with the transition from reactive to predictive capabilities marking a major evolution in strategic risk management. Operational cost reduction through AI (Königstorfer & Thalmann, 2020; Patil & Kulkarni, 2019; Salah et al., 2019) and cybersecurity improvements using AI-driven NLP tools (Annarelli et al., 2020; Saeed et al., 2023), illustrate moreover how financial institutions who better understand how AI can be implemented in practice will be more likely to transform operational models to sustain long-term innovation. Future AI adoption will increasingly depend not just on financial resources but on an institutions ability to comprehend and strategically integrate AI within their organizational frameworks (Saratchandra et al., 2022).
Shift from tool-based adoption to systemic transformationRather than viewing AI as a set of tools, successful institutions will increasingly treat AI adoption as a systemic transformation. A CT approach invokes greater intellectual insight that enables new meaning (Sandberg and Alvesson, 2021), that changes the character and nature of how institutions apply AI in practice from more isolated AI solutions towards AI-augmented organizational ecosystems (Huang & Kuo, 2020; Villar & Khan, 2021). Here, AI should be able to inform every level of decision-making and customer interaction. Financial institutions will need to invest in building internal cognitive capabilities such as cross-functional AI literacy, leadership vision for AI, and a culture of continuous learning (Saratchandra et al., 2022).
Dynamic capabilities as competitive differentiators/Use of non-traditional data sourcesInstitutions that continuously update their comprehension of AI trends especially in areas like generative AI, explainable AI, and ethical AI, will be better positioned to adapt to emerging challenges and opportunities. This invokes the boundary conditions within a CT approach resulting in greater shared understanding of AI in practice where in the future, constant re-learning and re-adaptation will help define future industry leaders. Future evolution will also see broader integration of non-traditional and real-time data sources (e.g., IoT data, social media sentiment, geospatial data), into AI models used in financial instruments expanding predictive capabilities and enhancing personalization (Königstorfer & Thalmann, 2020). As AI applications in finance become more powerful, regulatory and ethical challenges will multiply. Institutions with strong AI understanding not just of the technological aspects but also of ethical, legal, and societal implications, will need to lead the way in building trust and sustainable adoption.
Emerging themes 2: challenges of AIImproved technical and cognitive capabilityThrough the scoping process, significant challenges of using AI were noticeable. Applying a CT lens to these challenges indicates that successful technological adoption requires improved technical and cognitive capability. Poor accountability is often reflected in AI outputs. Insufficient human oversight for instance in credit scoring makes error tracking difficult and undermines trust (Bonsón et al., 2021; Mhlanga, 2022; Lee et al., 2021; Kozodoi et al., 2022). From a CT perspective, if stakeholders cannot understand how AI decisions are made, the ability to trust outputs is compromised and the gap between technological capability and cognitive acceptance is blurred (Munoko et al., 2020; Kochupillai et al., 2022). AI adoption will require institutions therefore to align technical outputs with human cognitive processes in ways that enhance transparency, traceability, and organizational trust.
High quality of input dataAI model accuracy depends on high-quality and unbiased input data (Santosh, 2020; Kolides et al., 2023; Sawhney et al., 2023), while digitization strategies and fragmented legacy systems limit useability (Zhang & Lu, 2021; Milana & Ashta, 2021). Because data quality issues may be particularly germane in deep learning applications (Vetrò et al., 2021; Kumar et al., 2023), financial institutions will require improvements in data stewardship and literacy programs to strengthen AI reliability. Skill gaps are also a challenge as employees lack expertise in programming, machine learning, and data analytics (Pai et al., 2021; He et al., 2021; Humphreys et al., 2020; Janiesch et al., 2021), necessitating continuous upskilling (Tagde et al., 2021; A.H. Huang et al., 2023). Without sufficient human interpretive capacity, the technological potential of AI cannot be fully realized. Organizations must therefore prioritize making long-term investments in employee education and foster cultures of continuous learning (Polak et al., 2020; Stone et al., 2020), so that the boundary conditions of AI discussed earlier can be satisfied.
InfrastructureInfrastructure limitations also pose serious challenges. If financial institutions rely on outdated and siloed systems, this will hinder large-scale data integration required for modern AI applications (Kalyanakrishnan et al., 2018; Etengu et al., 2020; Irani et al., 2023). From the CT perspective, fragmented infrastructure disrupts organizational sense-making processes by limiting coherent access to information. Future AI evolution will require not just infrastructure upgrades but comprehensive organizational restructuring to centralize data flows that support holistic, shared understanding (von Solms, 2021; Hradecky et al., 2022; Kar & Kushwaha, 2023).
Regulatory scrutiny and privacyIn an environment of heightened regulatory scrutiny, poor data collection practices and hidden consent agreements can erode consumer trust (Lee & Shin, 2020; Quach et al., 2022; Lukas et al., 2020; Naz et al., 2022). Financial institutions face potential financial, legal, and reputational damage in relation to privacy regulation non-compliance (Kruse et al., 2019; Roszkowska, 2021; Gong et al., 2021; Remeikienė & Gaspareniene, 2023). In addition, the extensive datasets needed for AI technologies to refine their algorithms and enhance performance may include sensitive personal information raising substantial privacy concerns (Korobenko et al., 2024). Financial institutions could consider using federated learning which involves collaborative model training across financial institutions to increase data privacy and security protocols (AI Kondaveeti et al. 2024; Cheng et al. 2020). Heightened security protocols would avoid identity theft, financial fraud, and reputational damage (Han et al., 2023). A CT process of analysis suggests financial institutions must enhance ethical strategies by prioritizing transparency, simplifying consent processes, and educating consumers and employees about AI-driven data usage.
AI model selectionA technical and strategic challenge is model selection. No single AI model fits all financial applications and poor model selection can produce inaccurate or misleading results (Kelly et al., 2019; Zeng et al., 2022). Poor alignment between model design and fit-for-purpose reflects poor contextual comprehension about how AI should be conceptually ordered through discourses, narratives, metaphors and thick descriptions that provide layers of meaning (Putnam & Banghart, 2017; Reed, 2011). Consequently, AI strategies must promote contextually sensitive model selection that accounts for data characteristics, regulatory requirements, and interpretability needs (Chua et al., 2023; Lee & Shin, 2020). Organizations also struggle with poor adaptability and slow response times. Rapidly changing environments characterized by evolving risks, increased regulations, and competitive dynamics demand agile operational frameworks (Gligor et al., 2019; Holzinger et al., 2021). A CT approach underscores the importance of evolutionary cognition or the ability of organizations to continuously adjust their interpretive frameworks in response to external shifts such that companies that successfully adapt to AI integration challenges can maintain competitive advantage (Wamba-Taguimdje et al., 2020; Sheel & Nath, 2019; Upadhyay et al., 2023).
Research discussionsThe aim of this study was to identify the gaps between AI theory and practice with a second aim to explore the challenges and opportunities of using ML in the financial sector. The study used a scoping review to explore the extant literature. We applied a CT approach (Putnam & Banghart, 2017; Sandberg & Alvesson, 2021), to help explain and typify how ML phenomena could be better understood and applied given the opportunities and challenges presented. The overarching aim of the current study was to broaden and extend current theoretical insights related to applying ML knowledge in practice. Next, we contribute to the ongoing relationship and debate between decision-makers and AI-driven processes. We do this by exploring the theoretical foundations that enable a deeper understanding of the ethical considerations of AI model transparency.
Earlier, we proposed two research questions. The first explored the extent to which AI opportunities overcome the challenges of applying and using ML in financial practice? An extensive analysis of articles through the planning, implementation, and summarizing stage led to the identification of seven opportunities offset by eight challenges (Tables 3a and 3b). However, while scholars had provided an extensive range of literature across different themes, applying AI in practice was not easily understood within and between financial institutions. One way of perceiving AI opportunities is that they cancel out challenges. To this end, the study makes two major contributions. First, the study used a CT approach as a basis to increase user understanding about the meaning of ML. Many challenges exist for users in financial firms to which existing AI theory cannot adequately explain. Earlier, we outlined how a CT methodology enables scholars and practitioners to explore the hidden meanings of phenomena in ways that users can better anticipate ML outcomes. For instance, when users can match the increase of speed and efficiency to their own technological requirements e.g., lending requirements, the action-logics of different contexts can be provided leading to greater meaning and sensemaking (Sandberg & Alvesson, 2021). Here, we suggested that the purpose of ML should be clear with greater intellectual insight manifested in practice. What we found however by reviewing hundreds of articles across themes was that the narratives and metaphors of ML were vague and not well understood. Moreover, our analysis established that many layers of meaning (Putnam & Banghart, 2017; Reed, 2011), were mostly embodied within complex technical jargon such that pre-existing AI models were not fit-for-purpose in meeting financial goals. Financial firms appear to be slow to match on-the-ground technical skills with the complexity of AI. While financial service firms will benefit from the development of AI technologies, both technical and social problems are associated with understanding and implementing AI in practice. Accordingly, the classification framework developed in this paper represents the first of our core theoretical contributions through an extensive review of AI-enabled finance sector challenges and opportunities. The framework provides a structured view of AI emerging themes for researchers and policymakers adding to scholarly understanding about which factors are important when using ML in practice. Moreover, the framework typifies richer descriptions, examples, and sources of ML problems and opportunities thus informing financial users about the potential pitfalls and desirable strategies in advance of action.
Our second theoretical contribution is commensurate with the second research question which asked how a comprehending theory approach provided greater intellectual insight of the AI phenomena to help close gaps between theory and practice? Here, this question requires greater explanation about the gaps between the theory and practice of AI and ML. To address this question, we matched relevant CT criteria based on Sandberg and Alvesson (2021), Putnam and Banghart (2017), and Feldman and March (1981), with example data of opportunities that matched CT criteria. Likewise, we repeated the process for AI challenges. We then contrasted example data for each of the opportunities and challenges by identifying a range of theoretical and practical gaps. Our analysis is illustrated in Table 4 with relevant numbered columns. Column 1 represents the research question, column 2 relevant CT criteria. Columns 3 and 4 reflect example data matched to CT criteria for opportunities and challenges, respectively. Column 5 accordingly illustrates the theory and practice gaps observed from sample data obtained through this review study. While the purpose of AI is clear (column 2), theory and practice gaps exist between columns 3 and 4, as AI processes and functions have hidden meanings that are not clearly articulated. Although AI promises much, the potential of AI is not always realized in practice. Similarly, the AI phenomenon can be explained by user understanding and meaning, where models decipher language, recognize images, and make decisions (column 2). However, this is counterbalanced by users who only have a nuanced understanding of the strengths and limitations of algorithms (column 3), as noted earlier in respect of technical skill gaps. While the goal of AI in the 1950s was to make machines think like humans (Sheikh et al. 2023), AI models are programmed on training data. Currently, they are not yet sophisticated enough to think in emotional and sentimental ways (Ali et al., 2024).
Comprehending AI Theory and Practice.
| Research Questions(1) | CT Criteria(Sandberg & Alvesson, 2021; p 499–500); see also Corparsson et al. (2012).(2) | Example Article Data of Opportunities that match CT criteria.(3) | Example Article Data of Challenges that match CT criteria.(4) | Overview & example of theoretical Gaps required to create greater meaning theory and practice.(5) |
|---|---|---|---|---|
| To what extent can hidden AI meanings and functions be better articulated to create clearer intellectual insight into the AI phenomena? | PurposeA comprehensive comprehension of organizational phenomena involves discerning their significance. | • The adoption of AI owing to its capacity to effectively manage a diverse array of data, enables entities like Fintech to venture into hitherto unexplored domains (Awotunde et al., 2021).• The integration and utilization of RPA (robotic process automation) in this environment is imperative (Jha et al., 2021).• AI models exhibit proficiency in conveying superior trading signals to human counterparts, adeptly identifying unforeseen market trends within constrained temporal parameters (Liu et al., 2020). | • Poor comprehensive understanding relates to the capabilities of bots and their operational dynamics (Cooper et al., 2019).• The fast-paced development of AI technologies poses a challenge for workers to keep up with the latest trends and methods (Dilsizian & Siegel, 2014).• Cewe et al. (2018) argue that the implementation of RPA often deviates from its intended direction, leading to considerable expenses associated with automation that could have been utilized across various other processes. | Theoretical Gap:The purpose should indicate what the phenomenon, i.e., AI, is about, such as articulating a hidden meaning (Reed, 2011).Practice Gap:While AI promises a lot, its potential purpose is not matched by its realized purpose. For example, poor comprehension of AI, up-to-date skills, and automation costs. |
| PhenomenaDefined by user understanding and meaning, more or less given, existing before researchers attempt to theorize. | • AI is a broad concept for creating models that can understand language, recognize images, make decisions, and learn from data (Agrawal et al., 2019).• AI signifies progress in computing capabilities, data retention, and communication standards (Biallas & O'Neill, 2020). | • Users lack a detailed comprehension of the capabilities and constraints of algorithms (Chua et al., 2023).• A great majority of companies are not agile about the assimilation and integration of AI into operational frameworks (Sheel & Nath, 2019; Upadhyay et al., 2023). | Theoretical Gap:AI began in the mid-1950s with a goal to make machines think like humans (Sheikh et al., 2023).Practice Gap:AI is programmed on the training data supplied, and it does not think in sentimental and emotional terms (Ali et al. 2024). | |
| Conceptually OrderedSystematically organize the suggested theoretical interpretation of the phenomena by employing detailed descriptions, narratives, discussions, metaphors, or compelling rhetorical techniques to clarify the meaning of the phenomena thoroughly and distinctly. | • Supervised ML learning algorithms are applied, encompassing well-established linear and logistic regressions including decision trees (Kaparthi & Bumblauskas, 2020), random forests (Sipper & Moore, 2021) & neural networks (Ghorbanzadeh et al., 2019) (among others).• Unsupervised ML learning inter alia entails the exploration of latent patterns or structures within data such as PCA (Jo et al., 2020), and generative models (Harshvardhan et al., 2020). | • Many legacy IT architectures comprising outdated hardware and software systems now represent a challenge, complicating the integration of modern AI techniques (Kalyanakrishnan et al., 2018).• The effectiveness of data for training AI models is hindered due to the incomplete digitization of business processes by established financial service providers (Zhang & Lu, 2021) | Theoretical Gap:Meaning systems ought to offer thorough explanations that encompass what, how, and why of variables (Whetten, 1989).Practice Gap:AI-based ML processes are not clearly articulated, evidenced by low digitization of business processes. Legacy systems are often not compatible with AI. | |
| Relevance CriteriaIt is essential to offer a well-informed and innovative understanding of the characteristics, nature, or fundamental aspects of organizational phenomena. This understanding should delve into various layers of meaning. | • AI models are becoming more commonly utilized to automate and improve decision-making processes (Jarrahi, 2018).• Effective data collection creates the perception that AI interactions are comparable to human interactions (Ali et al., 2023a).• Robotic Process Automation (RPA) algorithms automate pivotal business processes (Wittmann & Lutfiju, 2021). | • The dynamic evolution of AI technologies presents a challenge for employees to stay abreast of the latest trends and techniques (Dilsizian & Siegel, 2014; Tagde et al., 2021).• Transferring data to shared data lakes is intricate, costly, and time-consuming (von Solms, 2021; Hradecky et al., 2022; Kar & Kushwaha, 2023). | Theoretical Gap:Multiple layers of meaning are not always readily apparent. The underlying structures, routines, and tacit assumptions are not immediately observable (Putnam and Banghart, 2017).Practice Gap:In financial firms’ experiences. Employees do not have equal experiences which might be common only to IT scientists and computer engineers. | |
| Boundary ConditionThe boundary conditions for CT refer to the group or groups that collectively hold a defined understanding of the phenomenon in question. These phenomena must be perceived as credible by the groups utilizing them. | • AI has been widely adopted in the finance, healthcare, and manufacturing industries (Ali et al., 2023b).• Advancements in computing power, data storage, and swift and dependable communication protocols promote shared understanding (Biallas & O'Neill, 2020).• The evolution of the sharing economy has empowered consumers such as the effective utilization of real-time analytics and messaging. | • Financial institutions must ensure that their data collection and processing procedures comply with relevant data protection regulations (Lee & Shin, 2020).• Concerns regarding data protection could potentially impede the adoption of AI technologies by diminishing customer trust and confidence in financial institutions (Lukas et al., 2020; Naz et al., 2022).• Banks need to modernize their IT architecture however and strengthen their analytical competencies to create accurate analysis of client data (Huang & Kuo, 2020; Villar & Khan, 2021). | Theoretical Gap:Groups ought to collectively possess a clear and articulated understanding of the phenomenon (Sandberg and Alvesson, 2021).Practice Gap:While AI appears to be credible in terms of its purpose, data protection concerns all groups across industries. While many benefits exist, consumer trust and confidence is waning since the credibility of AI is compromised. | |
| Intellectual InsightAdvance beyond the interpretations and perspectives of individuals in a manner that surpasses or expands upon their immediate understandings and ways of acting. | • Model features facilitate a more precise, expeditious, and well-informed process framework, manifesting a substantial capacity to refine the credit risk assessment of loan applicants by leveraging diverse and often non-traditional datasets (Königstorfer & Thalmann, 2022).• Fintech firms possess the capacity to provide innovative and user-friendly financial services, such as mobile payments, online banking, peer-to-peer lending, and automated investment platforms.• Customers can enjoy customized services, access to information, and entertainment, often at little to no cost (Liao & Sundar, 2021).• The integration of varied datasets within AI-based forecasting models contributes to the generation of more nuanced and comprehensive insights within constrained temporal parameters, by substantially reducing the time and cost associated with forecasting endeavors (Kingsthorpe & Thalmann, 2020). | • The selection of an algorithm necessitates a comprehensive understanding of the nature of a problem, the data characteristics required, and a nuanced appreciation of algorithms strengths and limitations (Chua et al., 2023).• Firms are encouraged to strategically manage costs and boost revenue opportunities by meticulously designing intelligent automation systems, considering the entirety of end-to-end processes (Sundararajan, 2022).• NLP models face difficulties in comprehending context (Khurana et al., 2023).• Likewise, human language frequently uses multiple words to express identical concepts, which presents obstacles in language processing and algorithm development (Krommyda et al., 2020; Khurana et al., 2023).• Financial organizations encounter challenges in developing accurate and high-performing AI models (Stahl et al., 2021; Zaman et al., 2023; Gupta et al., 2023). | Theoretical Gap:Managers seek to perceive information as both a valuable resource and a representation of intelligent and proficient conduct. Consequently, having ample information serves as a symbolic assurance that the appropriate attitudes toward decision-making are in place (Feldman and March 1981; p. 178).Practice Gaps:Financial firms struggle to develop end-to-end processes and understand algorithm design in choosing among AI decisions.Financial firms do not always understand the nature of algorithms. New insight from AI practices challenge what has come before e.g., the progression from NLP models to AI. |
Similarly, while CT criteria require clear conceptually ordered descriptions, narratives, and discourses illustrated by supervised and unsupervised processes (column 2 of Table 4), these are counterbalanced with legacy IT systems, outdated hardware and software systems, and incomplete digitization. While the systems of meaning should provide in-depth interpretation (Whetten, 1989), the processes of AI are not clearly articulated. Likewise, layers of meaning should be evident under the relevance criteria of AI however this assumes that employees have equal access and know-how of AI processes which might only be common to IT specialists and engineers. A CT approach suggests that AI structures, practices, and taken-for-granted assumptions are commonplace (Putnam & Banghart, 2017), yet employees do not have equal experiences of AI. A boundary condition for a CT approach should be evident by sharing knowledge across groups (Sandberg & Alvesson, 2021) such as likeminded financial firms in the stock market sharing an articulated meaning related to ML practices. However, currently data protection concerns all groups across boundary conditions and trust and consumer confidence is low. Finally, a CT approach should help scholars and practitioners to move behind and beyond the meanings of phenomena by creating greater intellectual insight. Managers want information to be an instrumental resource (Feldman & March 1981), however firms will struggle to develop end-to-end processes that can uniformly utilize AI systems suggesting that AI is not an instrumental resource with clear ends and means. While adopting AI features and processes better equip financial firms to deliver innovative outcomes such as user-friendly services, it is a stretch based on our review to suggest that many financial firms would be able to methodically design intelligent automation systems that achieve greater intellectual outcomes that in turn provide increased customer satisfaction. Table 4 illustrates the discussions.
Research limitations and future directionsBy better appraising the challenges of leveraging real-world AI applications in finance against the opportunities presented, future researchers and finance experts will be able to develop AI user guidelines that ensure responsible utilization, strategies for optimizing advanced AI models in trading scenarios, and frameworks aligning AI-driven interactions with ethical principles. Future research could use the conceptual framework developed in Table 4 from this review to inform which innovative solutions best meet financial goals. Moreover, future research might explore what type of innovative approaches are required to practically implement federated learning as a means to expand the boundary conditions of ML in practice. Further, providing practical tools for workforce education is crucial to bridging the skills gap. Strategies for overcoming data scarcity and privacy concerns along with initiatives for workforce education offer practical pathways to navigate the challenges of AI integration in the financial sector.
Expanding on the thematic revelations presented in this study, future research in the intersection of AI and the finance sector holds significant promise. The theoretical foundations presented here serve as a robust starting point to build a comprehensive financial AI model of governance and practice. Model guidelines moreover cut across disciplinary boundaries and enhance efficiency and effectiveness when implementing finance service applications within the sector. Also, future research might focus on comprehensively addressing strategies of accountability in AI outputs and ways to improve the quality of training data in the evolution of AI systems. This might include research that explores advanced AI models in trading scenarios responding dynamically to the evolving landscape of financial technologies.
ConclusionThis study included a scoping review of AI-based ML opportunities and threats. Our findings present integrative insights for building novel research in the finance industry that identifies what these insights look like in the ongoing evolution of AI in the financial domain. To this end, a classification framework typifies the relationships in a structured way to support both researchers and industry practitioners. Moreover, we applied a CT approach to explore the relationships between theory and practice based on available research. New opportunities exist for AI's transformative potential in reshaping the financial landscape, promising increased efficiency and novel approaches to addressing industry complexities. However, as discussed, gaps between theory and practice suggest that the AI phenomenon is not clearly understood such that AI benefits should not be taken-for-granted but carefully explored by financial institutions.
CRediT authorship contribution statementOmar Ali: Writing – review & editing, Writing – original draft, Project administration, Methodology, Data curation, Conceptualization. Peter A. Murray: Writing – review & editing, Writing – original draft, Validation, Investigation, Formal analysis, Conceptualization. Ahmad Al-Ahmad: Writing – review & editing, Visualization, Software, Resources, Formal analysis. Il Jeon: Writing – review & editing, Visualization, Software. Yogesh K. Dwivedi: Writing – review & editing, Visualization, Validation, Resources, Investigation.