



Hoy nos encontramos en medio de cambios profundos en nuestra economía y sociedad impulsados por el análisis de cantidades masivas de datos. La investigación y práctica clínica se encuentran prestas a ser revolucionadas por metodologías que extraen información útil de un gran volumen de registros clínicos y que puede no ser evidente al utilizar los métodos tradicionales de análisis. En los últimos años, la cantidad de artículos científicos que hacen uso de estos métodos en un contexto académico y que reportan resultados exitosos se ha incrementado. Junto con éstos, los artículos de prensa que advierten que médicos y radiólogos podrían ser reemplazados por estos métodos en el futuro se han incrementado. Sin embargo, ¿cómo evaluamos el impacto real de estas metodologías en la práctica? Este artículo presenta un marco conceptual que define las ideas principales tras Big Data y la Ciencia de Datos y permite identificar los criterios para evaluar el potencial impacto de estos métodos en la investigación y práctica clínica. Además, con este marco discutimos los resultados de algunos estudios importantes que han captado la atención en la prensa y finalizamos con los principales desafíos que presenta la adopción de estos métodos en medicina.
Today we find ourselves amidst profound changes in our economy and our society driven by the analysis of massive datasets. Clinical practice and research are poised to be revolutionized by methods that extract useful information from large volumes of medical records that might not be evident when using traditional medical analysis techniques. The number of scientific articles that report successful results when applying these methods of analysis, both in academic and clinical settings, has increased in recent years. Simultaneously, the number of articles in the media warning that medical doctors and radiologists might one day be replaced by these automated methods has also increased. However, how do we evaluate in practice the impact of these methods? This presents a conceptual framework that introduces the main ideas behind Big Data and Data Science and points out the main criteria to be used to assess the potential impact of these techniques in medical research and practice. In addition, we discuss within this framework the results of some of studies that have been reported in the media, and we end by laying out the main challenges that pose the adoption of these methods in practice.
En las últimas décadas nuestra capacidad de generar y almacenar datos se ha incrementado de manera exponencial1,2. Simultáneamente, nuestra capacidad de procesamiento a gran escala se ha incrementado, permitiendo analizar los datos generados por las actividades que realizamos día a día3. Si bien hasta hoy el análisis de datos ha sido una de las piedras angulares del avance científico, tecnológico y económico, es la cantidad de datos disponibles hoy la que ha abierto la puerta a nuevas oportunidades. Por ejemplo, existen patrones de comportamiento de consumidores imposibles de detectar con pocos datos, los cuales se hacen evidentes a gran escala; del mismo modo, los parámetros de ciertos modelos predictivos, que en ausencia de datos suficientes son escogidos gracias a la pericia de profesionales del área, pueden ser estimados de manera precisa cuando la cantidad de datos es masiva. Por lo tanto, es la combinación actual entre la capacidad de almacenar y procesar datos a escala masiva la que ha comenzado a revelar estructuras latentes en las actividades humanas que éstos reflejan.
Sin duda, la investigación clínica es una de las áreas en las que el análisis de datos a gran escala promete tener un mayor impacto4-7. Por ejemplo, revelar patrones en la expresión genética de pacientes permitiría elucidar los mecanismos a través de los cuales ciertas enfermedades actúan8. Determinar qué estructuras moleculares tienen correlaciones fuertes con efectos fisiológicos podría tener un gran impacto en el desarrollo de nuevos fármacos9. Y agrupar una cantidad masiva de casos y controles permitiría validar conclusiones clínicas obtenidas a partir de estudios con un número reducido de participantes10. Esta es una fracción ínfima de ejemplos: el número de artículos publicados que relacionan inteligencia artificial con diagnóstico clínico pasó de 110 artículos anuales en promedio, en la década de los 90, a más de 770 artículos el año 2017 de acuerdo a la base de datos Pubmed.
Como metodología, el análisis de datos a gran escala ha tenido un gran éxito comercial. Rápidamente podemos nombrar dos ejemplos emblemáticos: el desarrollo de perfiles de usuarios que Google y Facebook realizan a partir de datos, los cuales permiten distribuir avisos publicitarios dirigidos11,12; el otro es el desarrollo de sistemas de recomendación en Amazon y Netflix, los cuales permiten predecir las preferencias de un consumidor13-15. La empresa de marketing intelligence Tractiva proyecta que el mercado creado en torno a estas técnicas crecerá de USD $3 mil millones en 2016 a USD $60 mil millones en 202616. En efecto, en el área médica se proyecta un mercado de USD $19 mil millones en 202517.
El éxito comercial ha llevado a la diseminación y divulgación general de los conceptos de Big Data, Data Science y Machine Learning, entre otros. Estos conceptos dan forma a un marco que permite describir y discutir el funcionamiento, desempeño e impacto del análisis de datos a gran escala. En ocasiones, su uso se encuentra rodeado de sensacionalismo e hipérbole, lo que ofusca los desafíos, riesgos y compromisos involucrados. Estos aspectos deben ser parte central de la discusión, para la implementación responsable de esta metodología en un contexto clínico. Mientras que la hipérbole puede llevar a una decepción prematura frente a resultados modestos4,18, una cautela excesiva puede ralentizar la adopción de técnicas que objetivamente pueden mejorar el cuidado de pacientes y la práctica clínica. Por lo tanto, para que esta metodología pueda revolucionar la disciplina médica, es necesario disponer de un marco conceptual donde sea posible discutir de manera objetiva sus resultados.
Este artículo tiene tres objetivos. Primero, definir los conceptos esenciales que permitan dar perspectiva a la discusión del uso de estos métodos en aplicaciones clínicas. Segundo, discutir los principales desafíos técnicos y conceptuales del análisis de datos a gran escala. Tercero, discutir de manera crítica algunas aplicaciones clínicas relevantes, reportadas en artículos científicos y en la prensa donde el desempeño de estos métodos es prometedor.
La estructura del artículo es la siguiente. Primero discutiremos las ideas principales detrás del concepto de Big Data. Luego discutiremos los conceptos fundamentales detrás de las técnicas de análisis de datos e identificaremos los criterios que permiten evaluar en la práctica el desempeño de estas técnicas. Haciendo uso de estos conceptos, discutiremos algunas aplicaciones clínicas relevantes y finalizaremos con una breve discusión acerca de los desafíos que Big Data presenta y como abordarlos.
EL DILUVIO DE DATOSLa capacidad de generar y almacenar datos se ha incrementado de manera exponencial en las últimas décadas y la medicina no es una excepción a este fenómeno. Este hecho considera los medios tradicionales de adquisición de datos, como imágenes radiológicas, fichas médicas y exámenes de laboratorios, pero también proyecta la adopción de tecnologías vestibles19-21 que prometen adquirir señales fisiológicas, por ejemplo, cardíacas22, en tiempo real. Es decir, la tasa de adquisición de datos clínicos se incrementará de forma considerable en un futuro cercano.
Esta cantidad masiva de datos, coloquialmente referida como Big Data, es parte de la metodología discutida previamente; los datos son la materia prima a partir de la que deseamos extraer información útil. Sin embargo, definir Big Data exclusivamente en términos del volumen de los datos ofrece una visión parcial y limitada que no explica su potencial, ni evidencia los desafíos que presenta su manipulación. Por ello, es necesario considerar otras dimensiones al intentar caracterizar qué es Big Data. La velocidad y la variedad de los datos son dimensiones relevantes que complementan el volumen. La velocidad refiere tanto a la rapidez de generación de los datos, por ejemplo, señales fisiológicas adquiridas en tiempo real por sensores vestibles, como al tiempo en que el procesamiento de los datos debe ser realizado, por ejemplo, al correlacionar señales en tiempo real para determinar el riesgo de un paciente y así poder asignar recursos en una unidad de cuidado intensivo. La variedad refiere a la naturaleza diversa de los datos que se adquieren hoy en día, incluso de un mismo paciente, como por ejemplo imágenes radiológicas, pruebas de laboratorio, e información cualitativa presente en fichas médicas. En resumen, son el volumen, la velocidad y la variedad23 de los datos que dan en parte origen a Big Data y elucidan los desafíos tecnológicos que presenta su manipulación y administración.
Sin embargo, es necesario complementar estas dimensiones para indicar aspectos de Big Data que van más allá de lo técnico. Usualmente se considera la veracidad de los datos como una dimensión de Big Data, que caracteriza en qué grado los datos reflejan una realidad objetiva, evitando errores sistemáticos o sesgos debido a factores humanos o técnicos. Las dimensiones de volumen, velocidad, variedad y veracidad dan origen a “las cuatro Vs de Big Data” propuestas por IBM24 y proveen una heurística para determinar cuándo un régimen de generación y adquisición de datos constituye Big Data. Es necesario enfatizar que se trata de una heurística y no de una definición. Si bien el volumen, velocidad y variedad son dimensiones ampliamente aceptadas, también se han considerado como dimensiones adicionales el valor, esto es, la relevancia de la información que proveen los datos en el contexto en el que se generan, y la variabilidad, esto es, si los datos caducan y deben ser removidos o actualizados. Por lo tanto, los atributos denominados “las 6 Vs de Big Data”25 son volumen, velocidad y variedad, que se refieren a la manipulación y administración de los datos, y veracidad, variabilidad y valor, que se refieren a la relevancia de los datos en el contexto del análisis que se quiere realizar. Estas 6 dimensiones proveen una completa caracterización del régimen de adquisición de datos que caracteriza Big Data en el contexto clínico y son las que consideraremos en este artículo.
Estas dimensiones revelan los desafíos que Big Data presenta en el contexto clínico. Debido al volumen y la velocidad es necesario desarrollar una infraestructura computacional que permita almacenar y administrar los datos adquiridos de manera segura. Enfatizamos que esta infraestructura no sólo constituye un registro digital, sino que además debe garantizar el rápido acceso y procesamiento de los datos, permitiendo los múltiples análisis requeridos por la práctica e investigación clínica. Esto exige la creación de unidades informáticas asociadas a clínicas y hospitales, que velen por la mantención, organización y administración de estas bases de datos y diseñadas de acuerdo con los requerimientos específicos de variedad y variabilidad de los datos.
Además, es necesario velar por la privacidad de los pacientes y voluntarios involucrados. Este último punto es uno de los argumentos prevalentes en la discusión de los potenciales riesgos de Big Data en el contexto clínico. Un método de protección es anonimizar los datos, removiendo información que permita identificar individuos directamente; este es un método en uso hoy en día. Sin embargo, en el contexto de Big Data, el volumen y la variedad de datos de un mismo paciente podrían estar correlacionados con datos obtenidos de otras fuentes, como transacciones comerciales26, revelando su identidad y dejándolo desprotegido. Afortunadamente, con una infraestructura de Big Data apropiada es posible analizar datos y proporcionar resultados agregados sin que el analista tenga acceso directo a la información de cada paciente; sólo el algoritmo computacional que implementa dicho análisis manipula los datos.
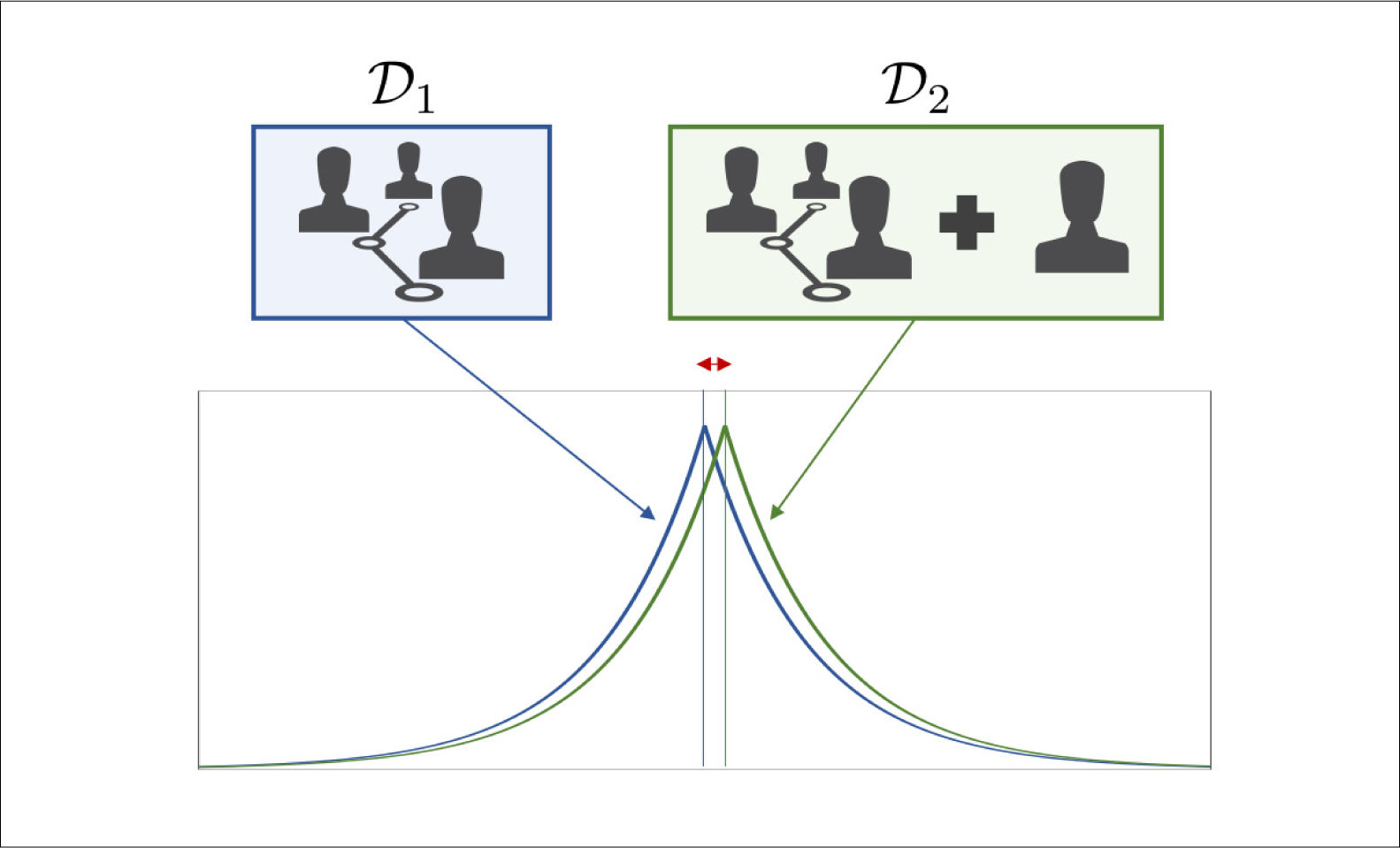
Aún en este caso, un individuo con intenciones nefastas, denominado adversario, podría tratar de inferir información personal a partir de múltiples análisis que entregan información agregada. La comunidad científica ha propuesto técnicas para evitar que esto ocurra: la privacidad diferencial27,28 y las bases de datos sintéticas29 son dos de ellas. Estos métodos utilizan técnicas matemáticas sofisticadas para reducir la probabilidad de éxito del adversario. La privacidad diferencial comprende el diseño de algoritmos en los que el efecto de los datos de sólo un individuo tiene un impacto pequeño; por tanto, nadie contribuye significativamente al resultado final, impidiendo al adversario inferir la identidad de un paciente dado (Figura 1). Las bases de datos sintéticas estiman la distribución estadística de los datos para reemplazar algunos de ellos por datos sintéticos o simulados; por tanto, el adversario es incapaz de distinguir si los datos son sintéticos o reales (Figura 2). Estas técnicas pertenecen a un área activa de investigación que, desafortunadamente, aún tienen una adopción limitada en comparación con técnicas tradicionales30,31.

Diagrama explicativo de la privacidad diferencial
En la ilustración se muestran dos bases de datos, denotadas D1 y D2, que se diferencian sólo por la presencia de los datos de un individuo adicional. El objetivo de la privacidad diferencial es diseñar de algoritmos cuyas conclusiones, representadas por las curvas en azul y verde, son similares en este caso. En otras palabras, la presencia del individuo en la base de datos D2 no tiene un mayor impacto en las conclusiones obtenidas, lo que se ilustra a través del pequeño desplazamiento en la curva verde relativa a la azul.

Diagrama explicativo de las bases de datos sintéticas
En una primera etapa, se dispone de una base de datos con registros de individuos. En una segunda etapa, se selecciona al azar un subconjunto de estos registros para estimar las características estadísticas de ellos. En una tercera etapa, se sustituyen datos a través de simulaciones que preservan la estadística de la base de datos original. Este proceso se puede repetir varias veces para disminuir la probabilidad de identificación de cualquier individuo cuyos datos reales están en la base de datos.
La protección de la privacidad de los pacientes ilustra un desafío importante, pero es sólo uno de los desafíos que Big Data presenta por sí mismo; como mencionamos, existen desafíos técnicos, relacionados con bases de datos, la ingeniería de software y la limpieza y mantención de datos, además de desafíos organizacionales y culturales32. Presentar una lista exhaustiva esta fuera del alcance del presente artículo. A pesar de esto, las dimensiones de Big Data entregan al lector un sólido punto de partida para entender y discutir estos desafíos.
APRENDIENDO A PARTIR DE DATOSSi Big Data es la materia prima, entonces su valor radica en la información y estructura que contiene. Las herramientas que permiten extraer esta información provienen de diversas disciplinas, tales como la Ciencia de la Computación, la Estadística y la Inteligencia Artificial, entre otras. La diversidad de fuentes de donde provienen estas herramientas ha dado origen a un nuevo campo científico interdisciplinario cuyo fin es desarrollar técnicas para extraer información a partir de datos. Esta disciplina, conocida como Ciencia de Datos (Data Science en inglés) es la segunda componente en la metodología de análisis de datos a gran escala.
Las dificultades encontradas al intentar definir Big Data persisten al intentar definir la Ciencia de Datos. Para efectos del presente artículo, nos bastará concebir la Ciencia de Datos como la disciplina del “estudio científico de la creación, validación y transformación de datos para crear significado”133. Para crear significado, lo más relevante es extraer información interpretable a partir de cantidades masivas de datos, por lo que nos enfocaremos en los métodos de análisis que usa la Ciencia de Datos, dejando de lado las dificultades, los desafíos, y las técnicas computacionales y algorítmicas asociadas a las tres primeras Vs de Big Data. La presentación y discusión tendrá un punto de vista estadístico, teniendo similitudes con la disciplina del Aprendizaje Estadístico de la que la Ciencia de Datos se nutre; ver, por ejemplo, (34-38) siendo referencias útiles para aprender más de esta disciplina34-40.
Los métodos de la Ciencia de Datos ya son utilizados en algunas aplicaciones clínicas, que discutiremos más adelante, y es probable que su uso se incremente sustancialmente en un futuro cercano. Debido al entusiasmo, y muchas veces hipérbole, en torno a Big Data y la Ciencia de Datos, es necesario ser capaz de evaluar el desempeño de estos métodos en casos prácticos y en un contexto adecuado. Además, es importante que en un comienzo estos métodos no sean adoptados como cajas negras que simplemente reemplazan etapas del flujo de trabajo usual, sino como una fuente de información adicional que asista la toma de decisiones en cada etapa de dicho flujo. En otras palabras, se espera que en una primera etapa estos métodos no tomen decisiones por sí mismos, sino que asistan la toma de decisiones al proporcionar información que puede no ser evidente a partir de los datos disponibles y los análisis tradicionales.
En consecuencia, es fundamental que los profesionales de salud puedan generar una discusión acerca del rol que estos métodos tendrán en el futuro, de acuerdo con su desempeño y basada en criterios objetivos. Para este fin, es necesario hacer uso de un marco conceptual que dé forma a la discusión y permita identificar criterios adecuados de evaluación.
Este marco conceptual será guiado por las preguntas:
- –
¿Cuál es el objetivo de analizar los datos?
- –
¿Qué características tienen los métodos que alcanzan este objetivo?
- –
¿Cómo evaluamos su desempeño?
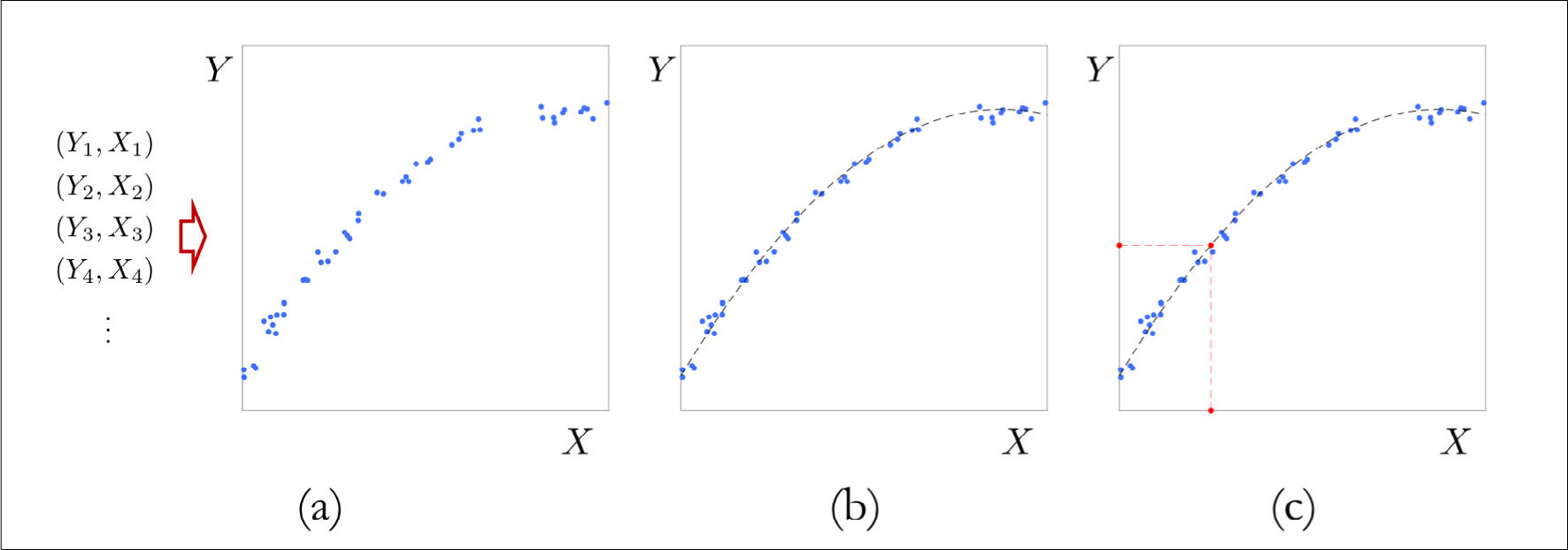
El objetivo de analizar los datos depende fuertemente del contexto en el que se origina la necesidad del análisis. Estos objetivos suelen pertenecer a dos categorías37. En la primera, llamada predicción, los datos corresponden a registros históricos acerca del valor de una variable de interés, conocida como variable de respuesta, y los valores de múltiples variables que pueden predecir dicha respuesta, denominadas variables predictoras. El objetivo de la predicción es determinar el valor de la variable de respuesta para una colección de nuevos valores de las variables predictoras, distintos de aquellos que conocemos (Figura 3). Este es el caso, por ejemplo, cuando se dispone de registros de la sobrevida y el historial médico de pacientes que han sido sometidos a una intervención. Con estos datos, ¿es posible predecir la sobrevida de un paciente que es intervenido hoy dado su historial médico? Ejemplos concretos de estudios que constituyen objetivos de predicción son estudios de diagnóstico clínico38, genómica39 y análisis de imágenes radiológicas40,41 entre otros.
. Uno dispone de registros de variables predictoras, indicadas como X, y su correspondiente variable de respuesta, indicada como Y. El gráfico representa los datos, donde cada punto corresponde a un par ordenado (X, Y). Los datos sugieren una estructura que explica la relación entre la variable predictora y la variable de respuesta. Panel (b). Un método predictivo aproxima la relación entre la variable predictora y la variable de respuesta a partir de los datos disponibles. La función f obtenida por un método hipotético se grafica con una línea segmentada negra. Vemos que efectivamente Y ≈ f(X). Panel (c). Una vez que el método estima la relación entre la variable de respuesta y la variable predictora, podemos realizar una predicción para un valor nuevo, ilustrado en rojo en la abscisa, al evaluar la función f estimada en este valor, lo que entrega el valor en rojo en la ordenada.")
Diagrama explicativo de una tarea de predicción
Panel (a). Uno dispone de registros de variables predictoras, indicadas como X, y su correspondiente variable de respuesta, indicada como Y. El gráfico representa los datos, donde cada punto corresponde a un par ordenado (X, Y). Los datos sugieren una estructura que explica la relación entre la variable predictora y la variable de respuesta. Panel (b). Un método predictivo aproxima la relación entre la variable predictora y la variable de respuesta a partir de los datos disponibles. La función f obtenida por un método hipotético se grafica con una línea segmentada negra. Vemos que efectivamente Y ≈ f(X). Panel (c). Una vez que el método estima la relación entre la variable de respuesta y la variable predictora, podemos realizar una predicción para un valor nuevo, ilustrado en rojo en la abscisa, al evaluar la función f estimada en este valor, lo que entrega el valor en rojo en la ordenada.
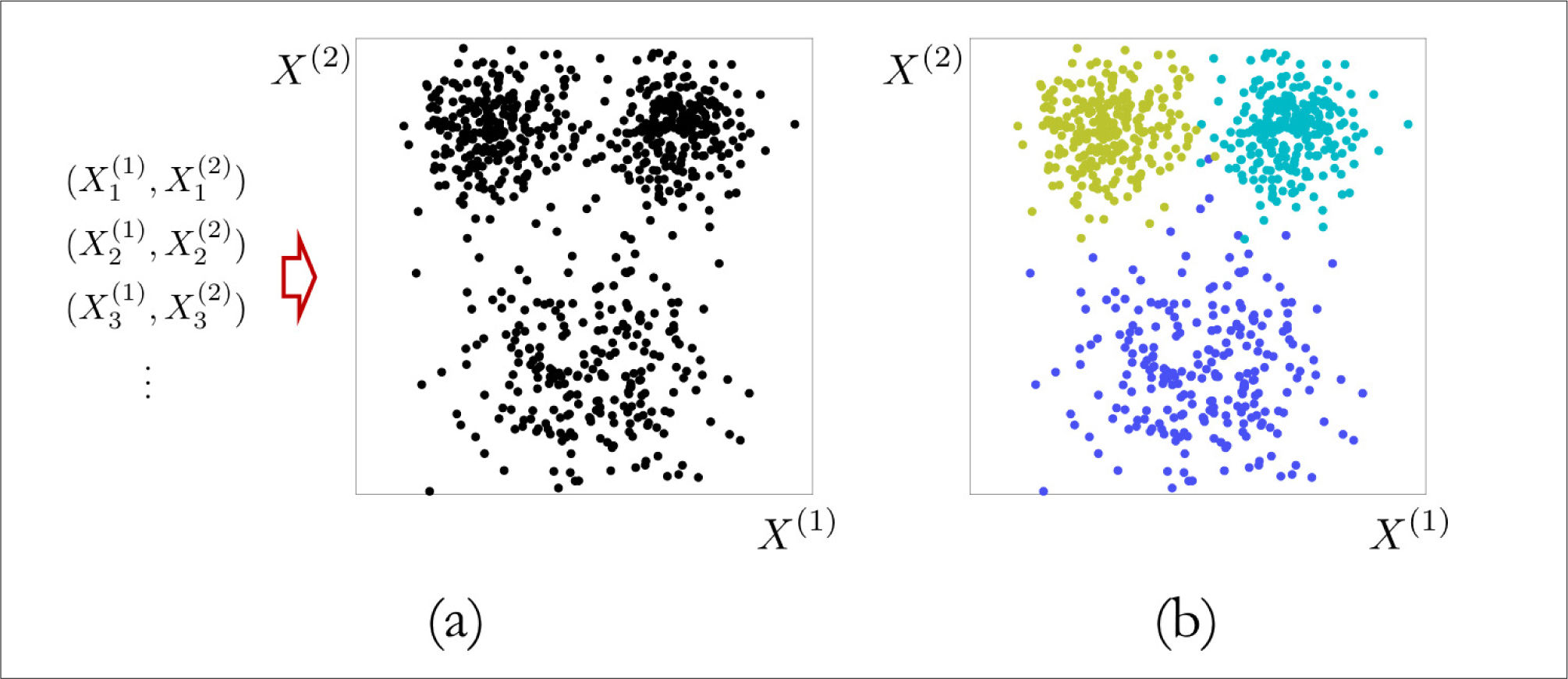
En la segunda categoría, llamada inferencia, los datos corresponden a registros históricos de múltiples variables de interés, y el objetivo es determinar la relación que existe entre estas variables (Figura 4). Este es el caso, por ejemplo, cuando se dispone de registros históricos de pacientes con una misma patología, y se desea determinar si existen agrupaciones naturales de pacientes de acuerdo con dichas variables de interés. En la práctica, estudios de esta índole buscan mejorar la certeza tanto en diagnósticos clínicos38,42,43 como radiológicos y de anatomía patológica40,44,45, avanzar hacia una medicina personalizada, identificar poblaciones de riesgo para incluirlas en tamizajes poblaciones e identificar potenciales intervenciones de alto impacto en salud pública46,47.
. Uno dispone de registros de variables predictoras, indicadas como X(1) y X(2). En este caso no hay variable de respuesta. El gráfico representa los datos, donde cada punto corresponde a un par ordenado (X(1), X(2)). En principio no pareciera haber una estructura evidente en los datos. Panel (b). Un método adecuado permite inferir que los datos se pueden agrupar en tres categorías, ilustradas con tres colores distintos. Notamos que en este caso no hay una predicción, el objetivo es simplemente extraer la estructura latente en los datos.")
Diagrama explicativo de una tarea de inferencia
Panel (a). Uno dispone de registros de variables predictoras, indicadas como X(1) y X(2). En este caso no hay variable de respuesta. El gráfico representa los datos, donde cada punto corresponde a un par ordenado (X(1), X(2)). En principio no pareciera haber una estructura evidente en los datos. Panel (b). Un método adecuado permite inferir que los datos se pueden agrupar en tres categorías, ilustradas con tres colores distintos. Notamos que en este caso no hay una predicción, el objetivo es simplemente extraer la estructura latente en los datos.
Estas categorías no son mutuamente excluyentes. Una vez propuesto un modelo predictivo para la sobrevida, es natural determinar qué variables del modelo tienen mayor poder predictivo, lo que constituye inferencia. De manera similar, luego de determinar grupos de pacientes con una cierta patología, puede ser de interés determinar modelos que predigan la progresión de ese paciente y a qué grupo pertenecería un paciente que ha sido diagnosticado hoy, lo que constituye predicción. Entonces, ¿por qué hacer una distinción?.
Los objetivos de predecir e inferir están íntimamente ligados con la efectividad y la interpretabilidad de un método. Existen métodos extremadamente efectivos para la predicción, como por ejemplo lo son las redes neuronales51,52 o los bosques aleatorios53. Sin embargo, estos métodos son difíciles de interpretar; es difícil determinar cuáles son las variables que impactan la predicción, por lo que es complejo inferir relaciones entre las variables predictoras y la respuesta, o entre las variables predictoras. Por el contrario, métodos tradicionales para realizar inferencia, como la regresión multivariada54,55, son fácilmente interpretables, pero suelen tener un peor desempeño que otras técnicas al realizar predicciones. Por tanto, determinar el objetivo como predicción o inferencia determina implícitamente el tipo de métodos que deseamos utilizar, y el compromiso entre desempeño e interpretabilidad que estamos dispuestos a asumir. Tener presente este efecto es fundamental al discutir lo idóneo de un método de la Ciencia de Datos aplicado al contexto clínico.
Aprendizaje supervisado y no supervisadoLa primera etapa para determinar el tipo de metodología a utilizar involucra identificar si el objetivo corresponde a la predicción, inferencia o una combinación de ambos. La siguiente etapa involucra directamente los datos disponibles y los métodos seleccionados, por lo que requiere la profunda comprensión de la operación de estos métodos.
En el caso del problema de predicción, si denotamos Y a la variable de respuesta (variable dependiente) y X a las variables predictoras (variables independientes), entonces el método cuyo fin es realizar predicciones busca modelar matemáticamente la información sistemática que X proporciona acerca del valor de Y. La relación entre la respuesta y los predictores puede ser descrita a través de una función f para la cual se tiene Y ≈ f(X); de esta forma, podemos realizar una predicción simplemente evaluando esta función para nuevos valores de las variables predictoras. Por lo tanto, el propósito de estos métodos es aprender a partir de los datos disponibles una buena aproximación de esta función f. Estos métodos se conocen como supervisados dado que los datos contienen tanto el valor de la respuesta como el valor de los predictores, y el proceso de aprendizaje se conoce también como entrenamiento56.
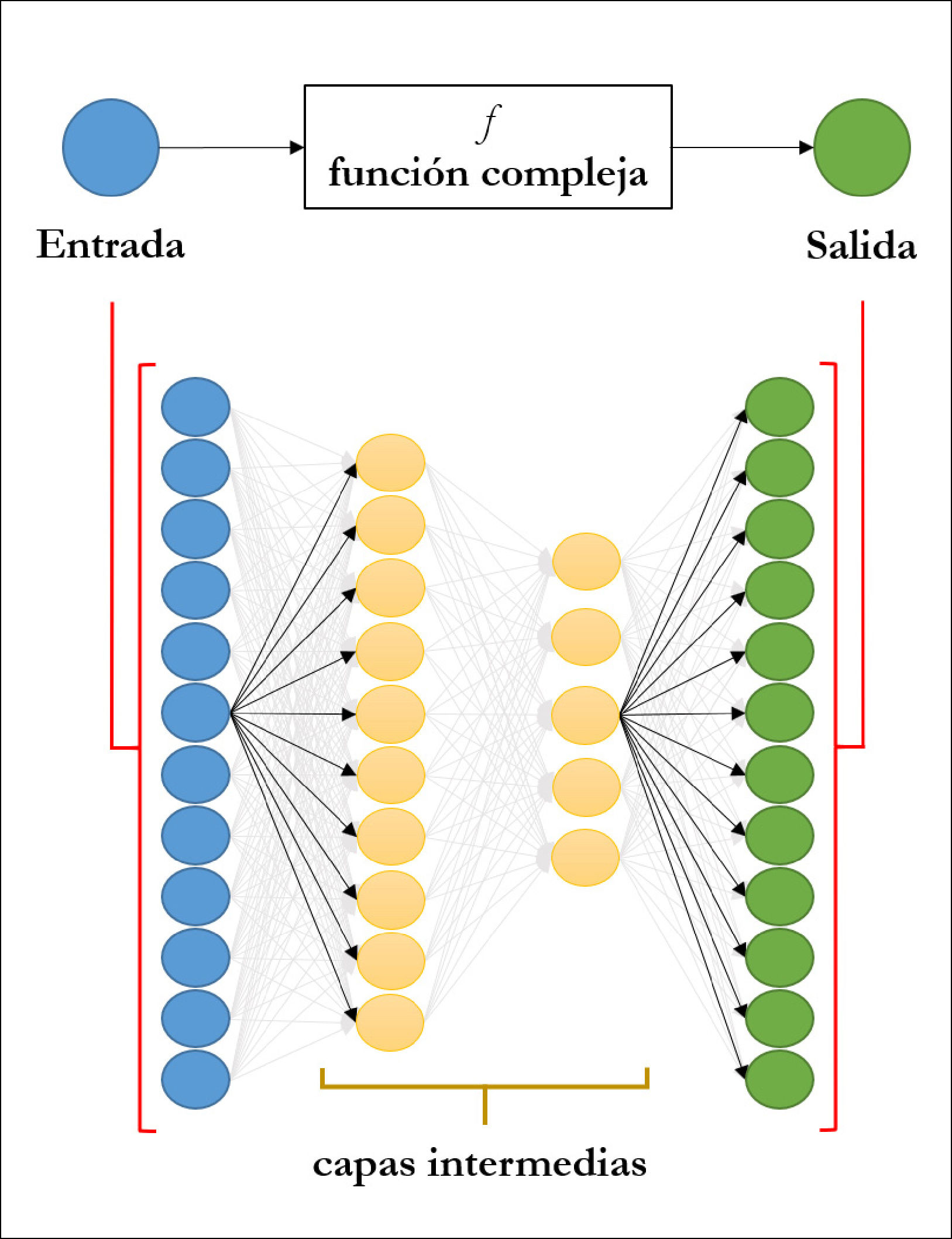
Un caso concreto es el diagnóstico de melanoma a partir de imágenes dermatoscópicas48. En este caso las variables predictoras corresponden a las imágenes ya adquiridas, mientras que la variable de respuesta corresponde al diagnóstico, por ejemplo, 1 si es melanoma o 0 si no lo es. Dado que el objetivo es predicción, un método factible podría ser una red neuronal (ver Figura 5), pues determina de forma aproximada la relación entre las imágenes y el diagnóstico haciendo uso de datos históricos. Cuando queremos predecir el diagnóstico de un nuevo paciente, conceptualmente estamos evaluando la función f en esta nueva imagen dermatoscópica para predecir la presencia o ausencia de esta patología. Por lo tanto, lo relevante para evaluar estos métodos es comprender cómo la estructura de los datos históricos refleja de una buena forma la estructura de la relación que deseamos aprender. Volveremos a este punto en más detalle en la siguiente sección.

Esquema de una red neuronal profunda
El objetivo es modelar la relación, que puede ser muy compleja, entre variables de entrada y de salida. Para ello, las componentes de la variable de entrada, que pueden ser las intensidades de los pixeles de una imagen, son utilizados como nodos de entrada. Cada nodo utiliza como entrada una combinación lineal del resto de los nodos de la capa anterior. La información se propaga a través de las capas intermedias hasta llegar a los nodos de salida. El número de capas y de nodos es determinado por el usuario. Los coeficientes de las combinaciones lineales son estimados a partir de datos.
En el caso del problema de inferencia, en general no se dispone de variables de respuesta: el propósito es determinar si existe estructura en las variables que registran los datos. La clase de métodos que son utilizados en este caso se denominan no supervisados58,59. Un ejemplo clásico es el agrupamiento (clustering en inglés) (ver sección 3 en (58) o sección 3 en (59))58,59, mediante el cual, dadas múltiples mediciones de variables continuas para múltiples pacientes, por ejemplo, la edad, el peso, y la presión arterial, se desea encontrar sugbrupos naturales de pacientes. Estos grupos pueden ser analizados posteriormente para verificar si coinciden, por ejemplo, con pacientes obesos o hipertensos, dándole así una interpretación clínica a posteriori a estos grupos. En general los métodos no supervisados son más complejos de analizar en la práctica, por lo que no los discutiremos con mayor detalle.
Muestreo, validación y errorLa metodología que ha sido el foco de nuestra discusión se basa en el análisis de registros de datos existentes; en otras palabras, en el resultado de analizar lo que hemos observado hasta el presente. Esto tiene implicaciones concretas al evaluar los resultados de un método. Si nuevamente nos enfocamos en predicción, ¿cómo aseguramos que un método efectivamente puede predecir una respuesta a una observación futura en vez de limitarse a modelar las relaciones que existen sólo en los datos existentes?.
La promesa de Big Data es que el volumen de datos es tal, que contiene la visión completa del fenómeno en consideración. Esta es una proposición ambiciosa y difícil de verificar. Una técnica comúnmente utilizada para verificar que la información extraída es generalizable, es la validación cruzada (ver sección 1 en (34))34 ésta también es útil para entender las limitaciones que existen al aprender a partir de datos. En la validación cruzada, los datos se separan en dos grupos al azar. El primero, llamado entrenamiento, se utiliza para aprender la relación que existe entre respuestas y predictores. Para verificar que es posible generalizar esta relación, se utiliza el segundo grupo de datos, llamado prueba, como un sustituto de los datos que observaremos en el futuro. De este modo, podemos determinar si la información extraída a partir del grupo de entrenamiento es generalizable al contrastarla con el grupo de prueba, proporcionando una métrica cuantitativa para evaluar el resultado del método propuesto.
Un ejemplo en el cual la adopción general de un modelo predictivo puede conducir a errores de predicción es el caso del estimador del peak estacional de influenza. En el año 2013 un equipo de investigadores de Google demostró que es posible predecir el peak estacional de influenza mediante el análisis de la frecuencia con que ciertos términos claves son buscados por los usuarios en la web49. El interés en el hallazgo reportado en esta publicación fue inmediato, pues los países destinan importantes recursos en centros centinelas con el objeto de predecir el peak estacional de influenza, de manera de asignar los recursos físicos y humanos a tiempo para dar respuesta a este peak. Sin embargo, el uso regular de este modelo en varios estados de EE.UU. y Europa ha demostrado que el modelo no es suficientemente preciso en su predicción50. Este “fracaso” ha abierto el debate respecto de la capacidad de generalizar modelos predictivos, el rol de la validación de estos modelos y la necesidad de calibrarlos continuamente para incluir nuevas fuentes de información.
Recapitulando, al evaluar si un método efectivamente extrae información generalizable a nuevos casos, es necesario ser cuidadoso al seleccionar e implementar técnicas de análisis adecuadas cuyos resultados hayan sido validados usando metodologías estadísticamente robustas. Cabe destacar que el resultado obtenido por estos métodos es siempre un reflejo de la cantidad y la calidad de la información que pudo ser extraída de los datos.
APLICACIONESEl marco conceptual presentado nos permite poner casos prácticos en perspectiva, y analizar de manera crítica algunos de los usos de Big Data y la Ciencia de Datos que han mostrado ser efectivos en aplicaciones clínicas.
Uno de los ejemplos que recientemente ha recibido atención, es el uso de una Red Neuronal Convolucional (RNC)61,62 para diagnosticar melanoma a partir de imágenes dermatoscópicas48. Una de las causas de su impacto es que los dermatólogos fueron capaces de predecir correctamente el 86.6% de los melanomas, y el 71.3% de las lesiones benignas; a una misma sensibilidad, la especificidad de la RNC es mayor, con un 82.5% de las lesiones benignas correctamente diagnosticadas. Un artículo de prensa, titulado “La IA [N.T.: Inteligencia Artificial] supera a doctores en diagnóstico de cáncer”2 nos indica que una RNC está “inspirada por los procesos biológicos que actúan cuando las células neurales (neuronas) en el cerebro se conectan unas con otras y responden a lo que el ojo ve.”351 ¿Cómo un marco conceptual nos permite interpretar estos resultados?
Primero, el problema de diagnóstico es un problema de predicción; a partir de una imagen dermatoscópica, que constituye la variable predictora, se desea determinar si la lesión es maligna o no, lo que constituye la variable de respuesta. Nuestro marco conceptual nos indica que la RNC es, por tanto, un método que intenta aproximar la relación que existe entre la imagen y el estado de la lesión, maligno o benigno, a partir de diagnósticos efectuados en el pasado. En general, es sabido que una RNC es un método particularmente efectivo para problemas de predicción a partir de imágenes52. Al examinar el artículo, vemos que esta red fue adaptada para la detección de melanomas a partir de una red existente, entrenada para otras tareas, utilizando 100 mil imágenes digitales con su respectivo diagnóstico. Los resultados fueron evaluados utilizando una base de 100 dermatoscopías clasificadas por el método entrenado y por 57 dermatólogos, 17 de los cuales declaraban 2 años o menos de experiencia, 11 declaraban entre 2 y 5 años de experiencia, y 30 declaraban más de 5 años de experiencia.
Podemos detectar varios elementos del diseño experimental que pueden influenciar el desempeño del método y de los dermatólogos, y que nos permitan interpretar este resultado. Es importante evaluar siempre la relación que los datos de entrenamiento pueden tener con los datos de prueba. Por ejemplo, los datos de entrenamiento pueden tener sesgos, en términos de la presencia desbalanceada de las distintas lesiones en estos datos, que expliquen la alta especificidad de la RNC en comparación con los dermatólogos. Los autores reconocen que los datos de prueba “no muestran un rango completo de lesiones”4 y que existe una “carencia de lesiones melanocíticas de otros tipos de piel y origen genético”5 ¿Es posible que los resultados estén influenciados por la exposición de los dermatólogos a una mayor variedad de lesiones? Por otra parte, los dermatólogos pertenecen a 17 países distintos, y su entrenamiento clínico puede generar una exposición dispar a distintos tipos de lesiones; el grupo es además heterogéneo respecto a la experiencia profesional de sus integrantes. Sin mayores detalles acerca de las características de los datos de entrenamiento utilizados, es difícil determinar que otros efectos pueden jugar un rol. Si bien no podemos dar respuesta a estas preguntas, este ejemplo ilustra cómo el marco conceptual presentado nos permite identificar elementos que se deben considerar al interpretar las notas de prensa tras un estudio de este tipo.
Un estudio realizado por Weng et al en 201753, hace uso de técnicas de análisis de datos para predecir riesgo cardiovascular a partir de fichas médicas de pacientes. La nota de prensa indica que “computadores que se pueden enseñar a sí mismos pueden desempeñarse aún mejor que guías médicas estándar, incrementando significativamente las tasas de predicción”6. Nuestro marco permite discutir este estudio en un contexto adecuado. Al revisar el artículo, verificamos que 8 variables de riesgo medidas en 378256 individuos en el Reino Unido fueron utilizadas para predecir el diagnóstico del primer evento cardiovascular. Vemos además la validación efectuada: el 75% de los datos fueron utilizados para entrenar los métodos considerados en el estudio, mientras que el 25% de los datos fueron utilizados como prueba. Estos métodos fueron comparados con la predicción obtenida a partir de las guías del Colegio Americano de Cardiología (ACC por sus siglas en inglés, American College of Cardiology) y la Sociedad Americana del Corazón (AHA por sus siglas en inglés, American Heart Association) que hacen uso de estas mismas 8 variables para predecir el riesgo de un evento cardiovascular. En general, los métodos de análisis de datos utilizados presentan un incremento en la tasa de predicción de eventos cardiovasculares por sobre las guías médicas utilizadas hoy en día. Este estudio ilustra algunos elementos importantes. Si bien los métodos fueron entrenados en datos, las variables de riesgo son las mismas determinadas por las guías de la ACC y AHA; el desempeño se puede deber a que los métodos capturan correlaciones entre estas variables que no son obvias, algo que los autores discuten en su artículo. También, mientras que las guías médicas son definidas a través de un comité especializado y tienen por objetivos ser fáciles de implementar en la clínica diaria y persistir en el tiempo, los métodos de análisis de datos pueden ser actualizados día a día, en la medida que nuevos datos estén disponibles y procedimientos de validación adecuados hayan sido efectuados.
Esto nos lleva a discutir el grado de especialización de estos algoritmos a los datos utilizados como entrenamiento. ¿Tienen estas bases de datos algo particular? ¿Se aplican las relaciones aprendidas a partir de estos datos a la población general? Como mencionamos, una primera medida para evitar una sobre-especialización es el uso de validación cruzada. Sin embargo, ¿qué tan precisa es esta técnica para estimar el error de generalización?.
Un análisis importante en esta dirección lo constituye el trabajo de Bernau et al10. En él, los autores diseñan un método de validación entre diferentes bases de datos; en otras palabras, un método que utiliza datos adquiridos por varios grupos de investigación para ser utilizados en distintos estudios. Esta técnica, que denominan validación cruzada entre estudios7 permitiría no sólo una evaluación más efectiva de los métodos reportados por la comunidad científica, sino que una validación continua de los mismos en la medida que más datos se encuentren a disposición del público. Además, la validación que consideraría bases de datos adquiridas por distintos grupos de investigación debería reflejar de mejor forma la variabilidad natural que ocurre cuando estos métodos son adoptados en la práctica clínica. El resultado de este trabajo es claro. Estos “...sugieren que la validación cruzada estándar produce una sobreestimación de la precisión de discriminación para todos los algoritmos considerados, en comparación con la validación cruzada entre estudios”8.
En resumen, es importante tener presente la doble responsabilidad que tendrán las instituciones clínicas que utilicen métodos basados en el análisis de datos: por un lado, adoptar métodos estrictamente validados y, por otra parte, validarlos debidamente en sus propias bases de datos, para asegurar una alta calidad, precisión y reproducibilidad de los resultados.
DISCUSIÓNProbablemente la mejor manera de dimensionar el potencial impacto futuro de Big Data en medicina consiste en reflexionar sobre el impacto que ha tenido, y sigue teniendo, el estudio Framingham54. Este proyecto estableció el seguimiento de una cohorte de 5209 hombres y mujeres sanos entre 30 y 62 años en la ciudad de Framingham en Massachusetts, Estados Unidos. El seguimiento se inició en 1948 y hoy continúa siguiendo a la tercera generación de los participantes originales. Las conclusiones que se han obtenido de este estudio han sentado las bases fisiopatológicas y terapéuticas de muchas enfermedades cardiovasculares y nutricionales entre otras55,56. Inspirados por este estudio, consideremos el volumen de datos que se obtendrían a partir de la información clínica de los egresos hospitalarios chilenos: 1.7 millones de egresos al año (DEIS 2015) más toda la información clínica de las consultas ambulatorias, que sólo en el sector público suman 10.8 millones al año (DEIS 2014) y todos los registros de defunciones y causas de muerte (103327 casos anuales, DEIS 2015). La información que se podría extraer supera en órdenes de magnitud aquella obtenida de un estudio de la escala del estudio Framingham. En la literatura se ha sugerido además que sistematizar toda esta información y contar con registros clínicos electrónicos permitiría extraer información similar a la que se obtiene desde estudios aleatorizados y meta análisis57.
Sin duda que el futuro de la unión de la Ciencias de Datos y la medicina es promisorio, pero ¿cuánto de esto resultará en una mejor salud para los pacientes o en una drástica transformación de la profesión médica? Diversos autores han reflexionado sobre los cambios que se avecinan38,58-60 y el consenso es que éstos serán profundos y significativos. Para estimar su impacto, podemos utilizar como referente la revolución que constituyó en las últimas décadas la tecnificación de la medicina por sobre el arte de la medicina59. Esta última revolución sin duda modificó el rol de los equipos médicos, impactó la forma en que se educan y entrenan los profesionales de la salud, generó nuevas necesidades, y mejoró significativamente la calidad de vida de la población. Del mismo modo, hoy nos encontramos en una etapa en la que es necesario responder a nuevas necesidades de cómo realizar investigación y cómo educar a los profesionales médicos del futuro.
Un ejemplo de iniciativas que responden a esta necesidad en investigación en Chile es el Centro de Imágenes Biomédicas de la Pontificia Universidad Católica de Chile. En este centro de investigación interdisciplinario, que depende del Departamento de Radiología, el Departamento de Ingeniería Eléctrica y del Instituto de Ingeniería Biológica y Médica, se desarrollan técnicas de radiología cuantitativa, cuyo fin es transformar la información contenida en imágenes radiológicas en métricas precisas y reproducibles. Por ejemplo, a partir de imágenes de flujo adquiridas por resonancia magnética es posible desarrollar modelos físicos que permiten caracterizar el comportamiento hemodinámico a alta resolución. Estas métricas pueden ser analizadas utilizando las técnicas discutidas a lo largo de este artículo con el fin encontrar biomarcadores que detecten de forma temprana situaciones de riesgo. Gracias al carácter interdisciplinario de este Centro, la visión de médicos, ingenieros, matemáticos y estadísticos forman parte de la motivación, desarrollo, implementación y análisis de estas nuevas metodologías.
CONCLUSIÓNEl marco conceptual delineado en este artículo permite generar una discusión en torno a aplicaciones del análisis de datos masivos en datos clínicos reportados en la prensa y en la literatura científica. Esta discusión informada es un primer paso para facilitar la amplia adopción de estas técnicas en la práctica clínica y para que los profesionales de la salud no sólo sean generadores de datos, sino que, con el apoyo de las tecnologías emergentes, los datos, con su correcto análisis e interpretación, apoyen a los equipos hacia mejores decisiones médicas. Esto no implica que los profesionales de la salud se conviertan en cientistas de datos. Por el contrario, es un llamado a crear grupos interdisciplinarios al interior de hospitales, clínicas y escuelas de medicina, que permitan a los profesionales de la salud familiarizarse con las nuevas técnicas de análisis desarrolladas, y a su vez permitan a los profesionales que desarrollan dichas técnicas familiarizarse con las inquietudes y desafíos que enfrentan los profesionales clínicos. Este es el único camino que garantiza que el desarrollo de estas técnicas computacionales en medicina evolucione en una dirección que beneficie a los pacientes y a los usuarios de los sistemas de salud. El futuro del uso de Big Data en la medicina es brillante, pero no exento de desafíos a los que debemos responder hoy.
Declaración Conflicto de InterésFinanciamiento: C.A.SL. fue parcialmente financiado por un Fondecyt de Iniciación # 11160728. M.A. fue parcialmente financiado por el proyecto Fondecyt #1180525.
“The scientific study of the creation, validation and transformation of data to create meaning.”
“AI Beats Doctors at Cancer Diagnoses”
“Inspired by the biological processes at work when nerve cells (neurons) in the brain are connected to each other and respond to what the eye sees”
“...the test-sets of our study did not display the full range of lesions.”