




Realizar una evaluación crítica de un artículo capacita a los profesionales para hacer un buen uso de la nueva información. Este hecho repercutirá de forma directa en el beneficio de nuestros pacientes. Antes de realizar una lectura crítica minuciosa hay que considerar si el artículo escogido tiene el diseño más adecuado para la pregunta que se quiere contestar (es decir, si tiene un buen nivel de evidencia). Por ello, es necesario conocer la clasificación de los estudios en función de su diseño (descriptivos o analíticos; prospectivos o retrospectivos; transversales o longitudinales), así como su correlación con los niveles de evidencia. También en lectura crítica es importante conocer los principales errores sistemáticos o sesgos. Los sesgos pueden aparecer en cualquier fase del estudio, pudiendo afectar a la muestra, al desarrollo del estudio o finalmente a la medida de los resultados.
The critical evaluation of an article enables professionals to make good use of the new information and therefore has direct repercussions for the benefit of our patients. Before undertaking a detailed critical reading of the chosen article, we need to consider whether the study used the most appropriate design for the question it aimed to answer (i.e., whether the level of evidence is adequate). To do this, we need to know how to classify studies in function of their design (descriptive or analytical; prospective or retrospective; cross-sectional or longitudinal) as well as their correlation with the levels of evidence. In critical reading it is also important to know the main systematic errors or biases that can affect a study. Biases can appear in any phase of a study; they can affect the sample, the development of the study, or the measurement of the results.
Uno de los principios fundamentales de la medicina es que la práctica clínica debe estar basada sobre el análisis crítico y la evaluación de las investigaciones1. Este principio se integra en el concepto de la Radiología basada en la evidencia (RBE) que se define como la decisión que resulta de integrar la clínica con la prueba de imagen más adecuada en base a la mejor evidencia disponible, la experiencia del médico y las expectativas del paciente2. La lectura crítica de artículos constituye el tercer paso dentro de la práctica de la RBE tras la formulación de la pregunta y la búsqueda en la literatura3.
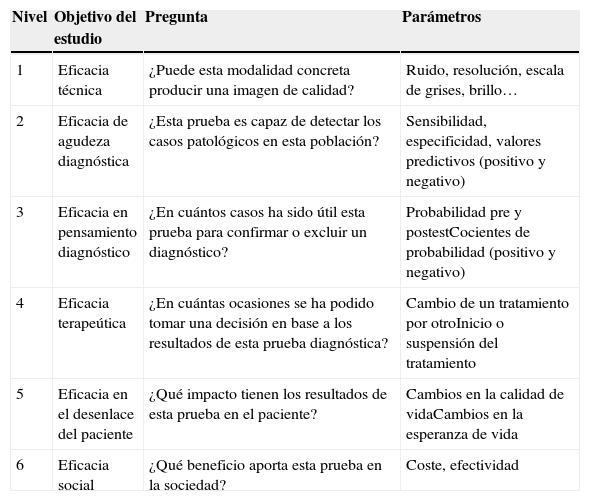
Actualmente hay una rápida proliferación de la tecnología radiológica. El objetivo de la mayoría de los estudios de investigación en diagnóstico por imagen es saber si una prueba determinada es útil o no para confirmar o excluir una enfermedad en un tipo de paciente concreto. Este aspecto se relaciona de forma directa con el pronóstico del paciente, ya que un diagnóstico correcto y precoz permitirá aplicar el tratamiento lo antes posible, mejorando así su esperanza y calidad de vida4. En diagnóstico por imagen existe una clasificación de los estudios atendiendo a su eficacia (tabla 1)5. Así, debido a la naturaleza del proceso de la imagen y el contexto en el que tiene lugar, la eficacia de la imagen diagnóstica se organiza de forma jerárquica, comenzando en el nivel 1 que habla sobre los fundamentos físicos aplicados hasta el nivel 6 que es el beneficio social que implica6.
Clasificación de las pruebas diagnósticas atendiendo a los niveles de eficacia
| Nivel | Objetivo del estudio | Pregunta | Parámetros |
|---|---|---|---|
| 1 | Eficacia técnica | ¿Puede esta modalidad concreta producir una imagen de calidad? | Ruido, resolución, escala de grises, brillo… |
| 2 | Eficacia de agudeza diagnóstica | ¿Esta prueba es capaz de detectar los casos patológicos en esta población? | Sensibilidad, especificidad, valores predictivos (positivo y negativo) |
| 3 | Eficacia en pensamiento diagnóstico | ¿En cuántos casos ha sido útil esta prueba para confirmar o excluir un diagnóstico? | Probabilidad pre y postestCocientes de probabilidad (positivo y negativo) |
| 4 | Eficacia terapeútica | ¿En cuántas ocasiones se ha podido tomar una decisión en base a los resultados de esta prueba diagnóstica? | Cambio de un tratamiento por otroInicio o suspensión del tratamiento |
| 5 | Eficacia en el desenlace del paciente | ¿Qué impacto tienen los resultados de esta prueba en el paciente? | Cambios en la calidad de vidaCambios en la esperanza de vida |
| 6 | Eficacia social | ¿Qué beneficio aporta esta prueba en la sociedad? | Coste, efectividad |
Fuente: Hollingworth et al.5.
La rápida evolución tecnológica también influye en el número de publicaciones ya que aumentan de forma paralela7. Pero lo importante no es el número de artículos, sino la calidad de los mismos. En este sentido solo se deben utilizar como base de nuestra práctica aquellos estudios que sean consistentes desde el punto de vista metodológico y que sean aplicables en nuestro ámbito (es decir, que tengan una buena validez interna y externa). Por ello se deben analizar de forma crítica8.
Los artículos originales normalmente se estructuran en cinco partes: introducción, material y métodos, resultados, discusión y conclusiones.
Aunque se deben valorar determinados aspectos dentro de cada apartado, la mayoría de las preguntas claves que se deben responder para garantizar la calidad de un artículo se encuentran en la sección de «material y métodos» y en la de «resultados».
Antes de comenzar a leer con detenimiento un artículo, se deben plantear algunas preguntas generales1:
- -
¿Es el tema actual y relevante?
- -
¿Cuál es la pregunta científica que quieren contestar los autores?
- -
¿Hay publicados estudios previos similares? ¿Cuáles fueron sus resultados?
- -
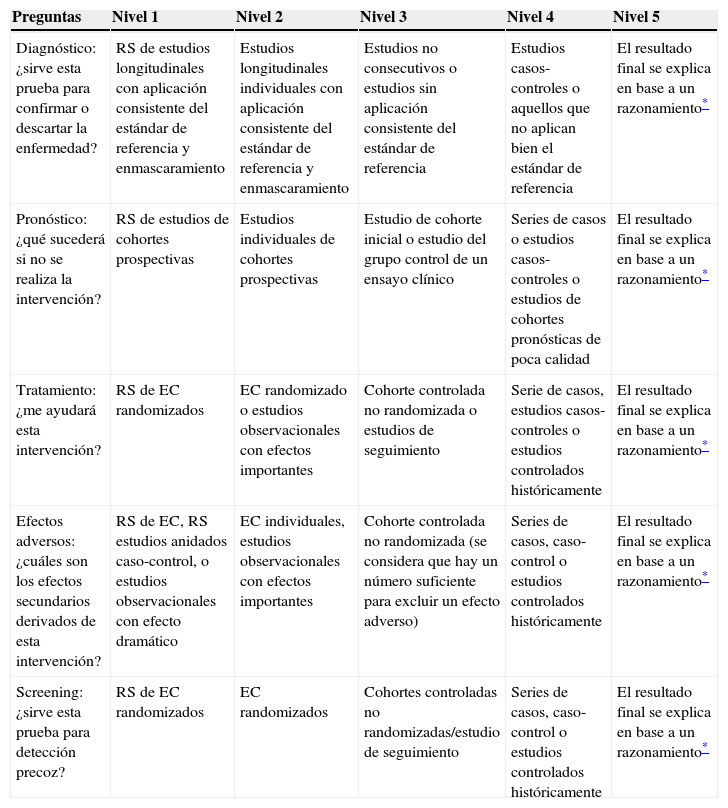
¿Tiene el mejor diseño posible para contestar nuestra pregunta de investigación? Por ejemplo, si se trata de elegir entre un tratamiento u otro para nuestro paciente, el ensayo clínico (o un metaanálisis que englobe los resultados de varios ensayos clínicos) es el estudio que tendría el mayor nivel de evidencia; sin embargo, si se quiere responder una pregunta sobre costes - beneficios, se tendría que elegir uno sobre análisis económico. Para ello, se establecieron los niveles de evidencia9 que van desde el uno (la mejor evidencia) hasta el cinco (la evidencia menos sólida (tabla 2)10.
Tabla 2.Nueva clasificación de los niveles de evidencia de la Universidad de Oxford
Preguntas Nivel 1 Nivel 2 Nivel 3 Nivel 4 Nivel 5 Diagnóstico: ¿sirve esta prueba para confirmar o descartar la enfermedad? RS de estudios longitudinales con aplicación consistente del estándar de referencia y enmascaramiento Estudios longitudinales individuales con aplicación consistente del estándar de referencia y enmascaramiento Estudios no consecutivos o estudios sin aplicación consistente del estándar de referencia Estudios casos-controles o aquellos que no aplican bien el estándar de referencia El resultado final se explica en base a un razonamiento* Pronóstico: ¿qué sucederá si no se realiza la intervención? RS de estudios de cohortes prospectivas Estudios individuales de cohortes prospectivas Estudio de cohorte inicial o estudio del grupo control de un ensayo clínico Series de casos o estudios casos-controles o estudios de cohortes pronósticas de poca calidad El resultado final se explica en base a un razonamiento* Tratamiento: ¿me ayudará esta intervención? RS de EC randomizados EC randomizado o estudios observacionales con efectos importantes Cohorte controlada no randomizada o estudios de seguimiento Serie de casos, estudios casos-controles o estudios controlados históricamente El resultado final se explica en base a un razonamiento* Efectos adversos: ¿cuáles son los efectos secundarios derivados de esta intervención? RS de EC, RS estudios anidados caso-control, o estudios observacionales con efecto dramático EC individuales, estudios observacionales con efectos importantes Cohorte controlada no randomizada (se considera que hay un número suficiente para excluir un efecto adverso) Series de casos, caso-control o estudios controlados históricamente El resultado final se explica en base a un razonamiento* Screening: ¿sirve esta prueba para detección precoz? RS de EC randomizados EC randomizados Cohortes controladas no randomizadas/estudio de seguimiento Series de casos, caso-control o estudios controlados históricamente El resultado final se explica en base a un razonamiento*
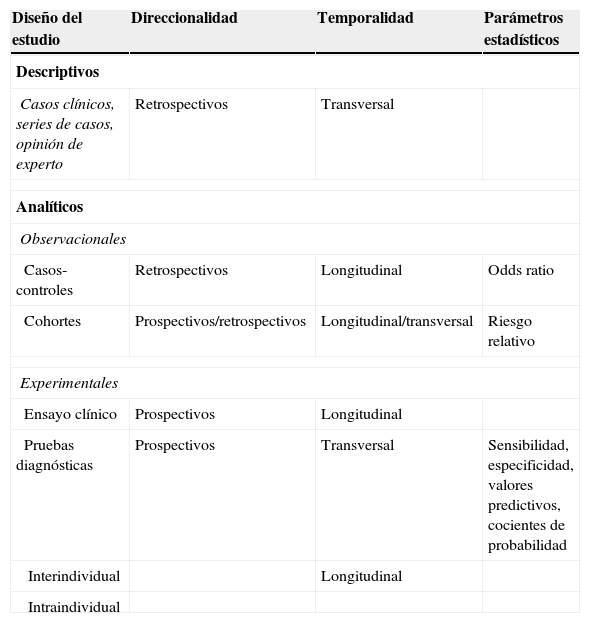
De forma muy general, podemos diferenciar entre estudios descriptivos y analíticos (tabla 3). A su vez, los estudios de investigación pueden ser clasificados desde el punto de vista de su direccionalidad en prospectivos (comienzan en el presente, pero los datos se analizan en el futuro) y retrospectivos (se analizan en el presente con datos del pasado)11.
Clasificación de los estudios
| Diseño del estudio | Direccionalidad | Temporalidad | Parámetros estadísticos |
|---|---|---|---|
| Descriptivos | |||
| Casos clínicos, series de casos, opinión de experto | Retrospectivos | Transversal | |
| Analíticos | |||
| Observacionales | |||
| Casos-controles | Retrospectivos | Longitudinal | Odds ratio |
| Cohortes | Prospectivos/retrospectivos | Longitudinal/transversal | Riesgo relativo |
| Experimentales | |||
| Ensayo clínico | Prospectivos | Longitudinal | |
| Pruebas diagnósticas | Prospectivos | Transversal | Sensibilidad, especificidad, valores predictivos, cocientes de probabilidad |
| Interindividual | Longitudinal | ||
| Intraindividual | |||
Otro aspecto de la clasificación es atendiendo a la temporalidad:
- -
Estudios transversales: se realizan con datos obtenidos en un momento puntual. La variable se mide solo una vez por cada sujeto. La medida básica que se usa es la prevalencia).
- -
Estudios longitudinales: implican el seguimiento de un determinado grupo para establecer una relación causa-efecto, midiendo una variable en un período de tiempo. Se necesita al menos dos medidas por cada sujeto (antes-después).
También se denominan estudios de información. Intentan responder a la pregunta ¿qué sucede? Describen las relaciones entre variables en un momento determinado, generando hipótesis que deberán ser comprobadas con otro tipo de estudios. Requieren una selección aleatoria de los sujetos para obtener muestras representativas de la población.
Son estudios observacionales. Normalmente son retrospectivos. Suelen ser útiles para investigaciones de enfermedades raras o nuevas tecnologías.
No tienen participación activa de pacientes, ni resultan de aplicar nuevos procedimientos por lo que no aumentan el riesgo de las personas ni el coste.
Dentro de los estudios observacionales descriptivos, existen varios tipos12,13:
- -
Casos clínicos y series de casos clínicos: son los estudios descriptivos más frecuentes y los más básicos en cuanto a diseño. Son los que tendrían menor nivel de evidencia. Sirven para generar hipótesis pero no para comprobarlas ya que no tienen grupo control.
- -
Estudios de morbilidad-mortalidad: Utilizan datos de los certificados de defunción o del sistema de enfermedades de declaración obligatoria. Son rápidos y baratos, resultando muy útiles en planificación sanitaria.
- -
Estudios ecológicos: utilizan datos de poblaciones, no de individuos. Algunos valoran los determinantes más que la distribución salud/enfermedad, siendo analíticos.
- -
Estudios de corte o sección transversal: la presencia o ausencia de enfermedad y exposición se miden en el mismo momento del tiempo. Son útiles en el estudio de enfermedades de larga duración y frecuentes. Habitualmente son descriptivos (miden la frecuencia) pero también pueden ser analíticos si establecen una relación entre la exposición y los efectos (midiendo entonces la prevalencia).
Los estudios analíticos pueden ser de tipo observacional (cohortes y casos y controles) o experimental (ensayos clínicos controlados). La diferencia principal entre ambos grupos es que en los estudios analíticos observacionales el investigador se limita a «observar» las características tanto de la exposición como del desenlace dentro de un grupo o entre dos grupos8. Por el contrario, en los estudios analíticos experimentales el investigador es quien asigna a los sujetos al grupo control o al grupo del tratamiento14,15.
Una característica común que tienen todos los estudios analíticos prospectivos es que para llevarlos a cabo se requiere siempre la aprobación por los Comités de Ética y que los pacientes firmen un consentimiento informado16.
Estudios analíticos observacionalesSe suelen utilizar para determinar si hay una relación causal entre un factor de riesgo y la aparición de una enfermedad. En estos casos no se pueden aplicar estudios experimentales, ya que no es ético aleatorizar de forma prospectiva a sujetos sanos y exponerlos o no exponerlos a algún factor que puede ser dañino. Dentro de los estudios observacionales analíticos se distinguen los siguientes:
Estudios de cohortesSon estudios analíticos, observacionales y longitudinales. Suelen ser prospectivos aunque en algún caso pueden ser retrospectivos. No resultan eficaces para evaluar enfermedades raras o con un período de latencia largo. Permiten el cálculo de la incidencia de la enfermedad y el riesgo relativo. Es decir, miden la fuerza de asociación entre exposición y efecto, indicando cuánto más probable es el efecto en expuestos respecto a no expuestos.
En los estudios de cohortes, se clasifican los participantes en expuestos y no expuestos a un determinado factor de riesgo y son seguidos durante un período de tiempo.
Un ejemplo de este diseño en nuestro ámbito podría el seguimiento de un grupo de radiólogos intervencionistas (mayor exposición a los rayos X) frente a otro grupo de radiólogos diagnósticos y medir la incidencia de cáncer en ambos grupos.
Estudios casos-controlesSon estudios analíticos, longitudinales y observacionales. En los estudios casos-controles, el investigador selecciona los sujetos en base a la presencia (casos) o ausencia (controles) de una enfermedad particular, comparando la historia de exposición a un factor de interés. Habitualmente son retrospectivos.
Ambos grupos deben presentar características basales similares, a excepción de la enfermedad. En ocasiones es necesario recurrir a un emparejamiento de cada caso con un control similar (por ejemplo de edad, sexo, peso…), obteniendo así pares de sujetos parecidos.
Son útiles para el estudio de enfermedades con periodo de latencia largo, permitiendo también el estudio de enfermedades raras.
En diagnóstico por imagen, pueden comparar un hallazgo de imagen entre sujetos sanos y enfermos. Los pacientes también sirven como sus propios controles bajo diferentes técnicas de imagen.
Estudios observacionales transversalesEn este tipo de estudios no hay comparación entre grupos de sujetos. Normalmente son prospectivos y estudian simultáneamente la exposición y la enfermedad en una población bien definida en un momento determinado, midiendo por tanto la prevalencia. Pueden ser retrospectivos si investigamos eventos pasados sin comparación del grupo control.
Estudios analíticos experimentalesSon estudios analíticos y longitudinales, en los que existe un grupo experimental y un grupo de comparación.
Existe una asignación aleatoria de sujetos para que ambos grupos sean equivalentes y únicamente se diferencien en la intervención que se va a aplicar.
Este grupo de estudios está constituido por los ensayos en sus distintas variantes: ensayo clínico, ensayo de campo y ensayo comunitario, si bien para el diagnóstico por imagen solo es de interés el primero.
El ensayo clínico es un estudio prospectivo que compara el efecto y valor de una intervención con respecto a un grupo control. En Radiología, los ensayos clínicos ayudan por ejemplo a comparar el nivel de eficacia de las técnicas intervencionistas guiadas por imagen con otros tratamientos17.
Estudios de evaluación de pruebas diagnósticasEl objetivo de estos estudios es definir la capacidad que tiene una prueba para diferenciar entre sujetos enfermos y sanos. Es el diseño más utilizado por los radiólogos en los últimos años.
Normalmente, se comparan los resultados de la prueba a evaluar con el estándar de referencia (que puede ser la anatomía patológica o bien otro examen diagnóstico ya establecido), que establece el resultado positivo o negativo de un paciente de forma definitiva.
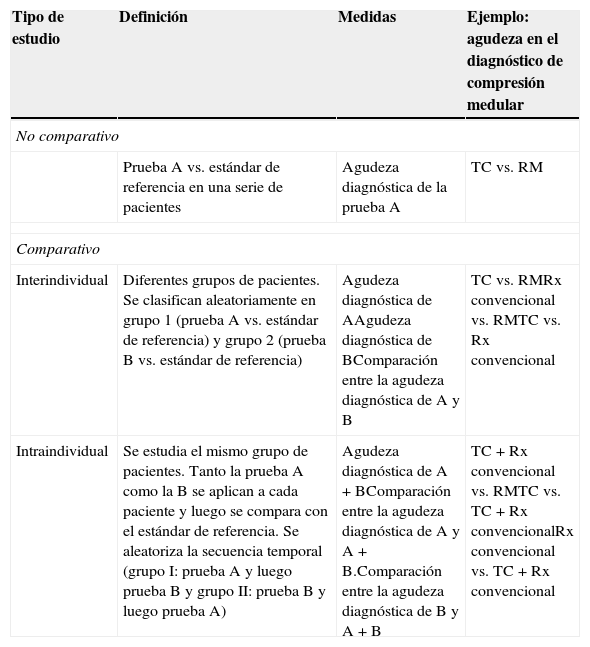
Dentro de este grupo, se puede diferenciar entre estudios no comparativos y estudios comparativos (inter o intraindividuales) (tabla 4)18.
Clasificación de los estudios de pruebas diagnósticas
| Tipo de estudio | Definición | Medidas | Ejemplo: agudeza en el diagnóstico de compresión medular |
|---|---|---|---|
| No comparativo | |||
| Prueba A vs. estándar de referencia en una serie de pacientes | Agudeza diagnóstica de la prueba A | TC vs. RM | |
| Comparativo | |||
| Interindividual | Diferentes grupos de pacientes. Se clasifican aleatoriamente en grupo 1 (prueba A vs. estándar de referencia) y grupo 2 (prueba B vs. estándar de referencia) | Agudeza diagnóstica de AAgudeza diagnóstica de BComparación entre la agudeza diagnóstica de A y B | TC vs. RMRx convencional vs. RMTC vs. Rx convencional |
| Intraindividual | Se estudia el mismo grupo de pacientes. Tanto la prueba A como la B se aplican a cada paciente y luego se compara con el estándar de referencia. Se aleatoriza la secuencia temporal (grupo I: prueba A y luego prueba B y grupo II: prueba B y luego prueba A) | Agudeza diagnóstica de A+BComparación entre la agudeza diagnóstica de A y A+B.Comparación entre la agudeza diagnóstica de B y A+B | TC+Rx convencional vs. RMTC vs. TC+Rx convencionalRx convencional vs. TC+Rx convencional |
RM: resonancia magnética; Rx: radiografía; TC: tomografía computerizada.
Fuente: Sardanelli et al.18.
A cada sujeto se le aplica tanto la prueba a evaluar como el estándar de referencia y se comparan ambos resultados. Los estudios deben ser interpretados con enmascaramiento. Es decir, las pruebas deben ser interpretadas por profesionales diferentes para que no conozcan los resultados.
Estudios comparativosA su vez, los estudios comparativos se pueden clasificar en interindividuales (se comparan dos o más modalidades de imagen, pero cada modalidad es interpretada en diferentes grupos de pacientes) e intraindividuales (se comparan dos –o más– modalidades de imagen con otra, pero siempre en el mismo grupo de pacientes).
Al igual que en los estudios no comparativos, la lectura de cada prueba y la del estándar de referencia se debe realizar por separado. En los estudios interindividuales los pacientes deben ser aleatorizados. En los intraindividuales se debe aleatorizar el orden de aplicación de las pruebas y es importante establecer la secuencia temporal de las diferentes imágenes en cada paciente. Se debe aplicar un período de lavado (de al menos una o dos semanas) entre la aplicación de pruebas diferentes.
La comparación de múltiples exámenes suele ser más potente cuando usamos un diseño intraindividual que uno interindividual. Al interpretar múltiples exámenes en los mismos pacientes, se obtiene una reducción en la variabilidad con respecto a la que se obtendría usando un diseño interindividual. Este hecho permite reducir el número de sujetos, reducir el coste y la duración del estudio.
SESGOSEn estadística, el término «error» es un concepto amplio que incluye todo lo que falta a la verdad, sin distinguir la causa que lo provoque. De forma general, se pueden diferenciar dos tipos de errores principales: el error aleatorizado (ocasionado por el azar) y el error sistemático o sesgo19.
El sesgo es un error sistemático en la recolección, análisis, interpretación, publicación o revisión de los datos.
El factor de confusión se puede considerar un sesgo. Se produce cuando hay factores adicionales o variables que se asocian a la exposición y de forma independiente con la enfermedad pudiendo producir un efecto mixto. Por ejemplo, si se está estudiando el efecto del alcohol como factor de riesgo de cáncer de laringe. Muchos pacientes además de beber, fuman. El tabaco por tanto, actuaría ahí como factor de confusión ya que no se pueden analizar los hábitos por separado.
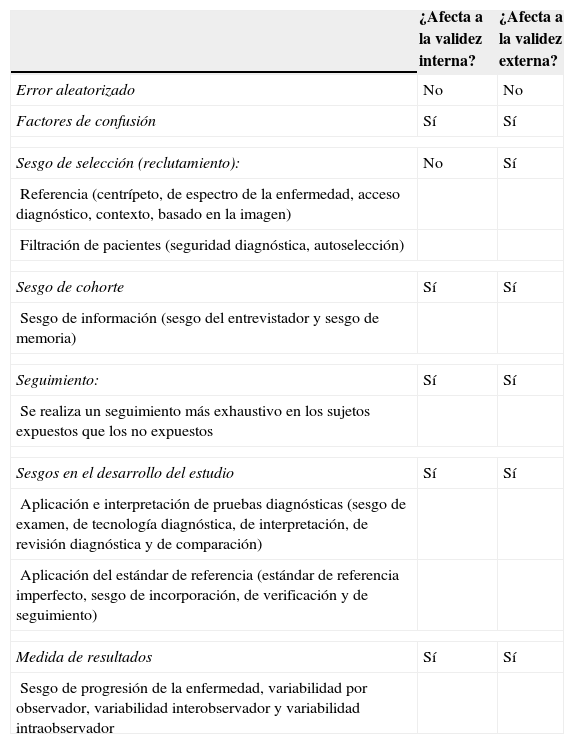
Los sesgos se pueden clasificar en positivos (cuando un parámetro alcanza valores superiores al real o se produce una asociación al azar) y negativos (cuando la estimación de un parámetro es inferior a la real o se anula una asociación que verdaderamente existe), (tabla 5). También se considera sesgo si se cambia el sentido de una asociación o diferencia (por ejemplo, lo que es factor de riesgo de una enfermedad pasa a ser un factor de protección de la misma).
Principales sesgos
| ¿Afecta a la validez interna? | ¿Afecta a la validez externa? | |
|---|---|---|
| Error aleatorizado | No | No |
| Factores de confusión | Sí | Sí |
| Sesgo de selección (reclutamiento): | No | Sí |
| Referencia (centrípeto, de espectro de la enfermedad, acceso diagnóstico, contexto, basado en la imagen) | ||
| Filtración de pacientes (seguridad diagnóstica, autoselección) | ||
| Sesgo de cohorte | Sí | Sí |
| Sesgo de información (sesgo del entrevistador y sesgo de memoria) | ||
| Seguimiento: | Sí | Sí |
| Se realiza un seguimiento más exhaustivo en los sujetos expuestos que los no expuestos | ||
| Sesgos en el desarrollo del estudio | Sí | Sí |
| Aplicación e interpretación de pruebas diagnósticas (sesgo de examen, de tecnología diagnóstica, de interpretación, de revisión diagnóstica y de comparación) | ||
| Aplicación del estándar de referencia (estándar de referencia imperfecto, sesgo de incorporación, de verificación y de seguimiento) | ||
| Medida de resultados | Sí | Sí |
| Sesgo de progresión de la enfermedad, variabilidad por observador, variabilidad interobservador y variabilidad intraobservador | ||
Un sesgo común en la literatura científica es el de publicación. Existe una tendencia reconocida a publicar solo estudios con resultados positivos. Un artículo que concluyera que el TC no es de utilidad para excluir cierta enfermedad, tiene menos «impacto» para el lector y es menos citable que uno que dijera que sí. Sin embargo, ambos serían igual de relevantes desde el punto de vista clínico.
Como se ha visto anteriormente, los sesgos se pueden producir en las diferentes fases del estudio (desde la recolección de datos hasta la interpretación de los resultados). Dependiendo de la fase donde se produzcan, pueden afectar a la validez interna (es decir, los sesgos impiden aceptar los resultados de un estudio) y a la validez externa (los sesgos no permiten hacer una buena inferencia de la realidad, por lo que los resultados del estudio no pueden ser extrapolados a la población general).
A continuación se explicarán los principales sesgos.
Sesgos relacionados con la muestraSesgos en la selección de sujetosEl sesgo de selección o de muestreo se produce cuando algunos sujetos de la población tienen más probabilidades de ser seleccionados para la muestra que otros y la muestra seleccionada no es representativa de la población. Al no estar los sujetos bien seleccionados, no se pueden extrapolar las conclusiones del estudio a la población general, afectando a la validez externa. Las técnicas de muestreo probabilístico y el reclutamiento de forma consecutiva ayudan a prevenir este tipo de sesgo.
Los sesgos de selección se clasifican dependiendo de la fase del estudio en que se produzcan:
Fase de reclutamiento de sujetos-Sesgo de referencia: se produce cuando la población de la que se obtiene la muestra tiene una prevalencia de la enfermedad mayor o menor que la población general. Al tener la muestra una prevalencia aumentada, se afectarán los valores predictivos y también se podrían afectar la sensibilidad y especificidad20.
- •
Sesgo centrípeto: la muestra se obtiene de un hospital muy especializado.
- •
Sesgo de espectro de enfermedad: puede ocurrir cuando los pacientes seleccionados presentan un subtipo de enfermedad con una severidad o duración de los síntomas diferente de la de los pacientes que se tratan en la práctica clínica o bien cuando la enfermedad se encuentra muy avanzada ya que los casos iniciales son difíciles de detectar21. Por ejemplo, en un estudio que investiga la habilidad de la RM para excluir cirrosis, si incluimos solo los casos avanzados, la sensibilidad será sobrestimada.
- •
Sesgo de acceso diagnóstico: dependiendo del entorno geográfico (y económico), los pacientes tienen más o menos probabilidades de ser incluidos en el estudio. Por ejemplo, un barrio con alto índice de analfabetismo, tiene menos probabilidades de ser incluido en el estudio si el reclutamiento es por carta.
- •
Sesgo de contexto: se refiere a la alteración de la prevalencia de la enfermedad en un período concreto de tiempo. Si la prevalencia de la enfermedad en esos meses es más alta que en el resto del año, se afectarían los valores predictivos.
- •
Sesgo de inclusión: si la selección se realiza vía telefónica, se excluyen automáticamente todas las personas que no tienen o no cogen el teléfono.
- •
Sesgo de selección basado en la imagen: cuando la inclusión de los sujetos depende de disponer una técnica de imagen concreta. Es común en la literatura radiológica, donde la población de estudio es seleccionada en base a la disponibilidad de técnicas de imagen. Otra forma de este sesgo se basa en las exploraciones en tiempo real, que solo guardan las imágenes seleccionadas (endoscopia, ecografías). En estudios retrospectivos solo se analizan estas imágenes.
- •
Sesgo de seguridad diagnóstica: si el estudio utiliza técnicas de diagnóstico invasivas o que administran mucha radiación, favorece que se incluyan en el estudio aquellos sujetos sintomáticos o con alta sospecha de enfermedad. Se evitan así daños a personas potencialmente sanas.
- •
Sesgo de autoselección: a veces, las personas que acceden a entrar en el estudio no tienen las mismas características que las que no quieren participar. Este sesgo es importante en los estudios de cribado: una persona que se encuentra mal o que tenga más consciencia de la enfermedad es más probable que acepte la inclusión en el estudio que una que se encuentra perfectamente22.
Tras comprobar que la población está bien elegida (no hay sesgos de referencia) y que tampoco hay sesgos de filtración, se debe analizar si la muestra obtenida (cohorte) es representativa de la población general. El sesgo de cohorte incluye las condiciones patológicas, clínicas y comorbilidades de la muestra (a no ser que en los criterios de inclusión se especifiquen unas características concretas)23.
También ocurre cuando hay un error en la clasificación del paciente respecto al estado expuesto/no expuesto o enfermo/no enfermo (sesgo de información). Este tipo de sesgo también afecta la validez interna. Puede ocurrir por diferentes motivos:
- -
Sesgo del entrevistador: el que pregunta o recoge la información conoce el grupo al que pertenece el sujeto de estudio (expuesto o no expuesto, caso o control).
- -
Sesgo de memoria: el sujeto entrevistado no recuerda bien si estuvo expuesto o no al factor de riesgo estudiado.
Como su nombre indica, se produce por pérdidas durante el seguimiento. Debemos conocer las causas del abandono de aquellas personas que dejaron el estudio, ya que puede estar relacionada precisamente con la exposición de la enfermedad o por la intervención realizada.
Otro sesgo que puede aparecer durante esta fase es que exista una observación desigual entre los sujetos expuestos y no expuestos a un determinado factor de riesgo (estudios de cohortes): se tendería a realizar un mayor número de pruebas diagnósticas a los sujetos expuestos que a los no expuestos. En este caso habría una mayor probabilidad de detectar enfermedad en los expuestos, ya que se encuentran mejor valorados.
Sesgos durante el desarrollo del estudioMientras que los sesgos de selección pueden ocurrir en todos los tipos de estudios, este bloque tiene especial importancia en los estudios de diagnóstico.
Relacionados con la aplicación e interpretación de pruebas diagnósticas- •
Sesgo de examen: cuando un estudio es técnicamente limitado o es incompleto se excluye del análisis. También se suelen incluir solo aquellos pacientes que son «ideales» para una prueba de imagen (como excluir los obesos de la ecografía). Estos dos hechos producirán una sobrestimación tanto de la sensibilidad como de la especificidad, disminuyendo los falsos positivos y los falsos negativos.
- •
Sesgo de selección del número de lectores: cuando se comparan varias pruebas, se deben escoger para interpretar cada una de ellas varios radiólogos. La agudeza de la prueba es una conjunción de la modalidad y del radiólogo que la interpreta24.
- •
Sesgo de tecnología diagnóstica: cuando se diseña un estudio, se debe utilizar una tecnología actualizada y considerar el tiempo necesario para completar el reclutamiento con vistas a predecir la evolución tecnológica. Este sesgo ocurre cuando las pruebas radiológicas empleadas ya se encuentran obsoletas. Dentro de este grupo encontramos también el sesgo de protocolo de imagen (cuando no se tienen en cuenta todos los parámetros técnicos como la posición del paciente, dosis de radiación, etc.) o el sesgo de medición (refleja una discrepancia en las medidas obtenidas con una nueva técnica comparadas con las obtenidas usando la técnica de referencia utilizadas en las mismas condiciones)25.
- •
Sesgo de revisión (de interpretación): la prueba debe ser interpretada sin conocimiento del diagnóstico final ni otra información adicional. Esto es lo que se conoce como «cegamiento». Si el radiólogo no está «cegado», podrían sobrestimarse tanto la sensibilidad como la especificidad, no siendo válidas sus conclusiones. En este sentido, un investigador es mucho más efectivo en un estudio prospectivo que en uno retrospectivo.
- •
Sesgo de revisión diagnóstica: ocurre cuando una interpretación subjetiva del explorador causa sobrediagnóstico. Por ejemplo, si se está evaluando la utilidad de la ecografía para el diagnóstico de trombosis venosa profunda y el radiólogo diagnostica de trombosis venosa profunda aquello que no lo es. A diferencia del anterior, no se elimina diseñando un estudio prospectivo.
- •
Sesgo de comparación: aparecen en los estudios que comparan la agudeza diagnóstica de dos o más test que implican diferentes técnicas (por ejemplo un enema de bario con simple o doble contraste) o diferentes técnicas de imagen (CT vs. RM). Puede ocurrir cuando los test no son independientemente interpretados o el estándar de referencia no es independiente de los test que están siendo comparados. En el caso extremo donde uno de los test es usado como estándar de referencia, cualquier discordancia entre los resultados del test es categorizada como un falso positivo o falso negativo del otro test.
- •
Sesgo del estándar de referencia imperfecto: cuando el estándar de referencia no es 100% diagnóstico para una enfermedad (por ejemplo, cuando se detecta un pólipo en colonoscopia por TC y luego no se confirma con la óptica por un error humano). También cuando se utiliza otro test diferente como estándar de referencia por razones éticas o económicas.
- •
Sesgo de incorporación: se produce cuando la definición del test incorpora elementos del estándar de referencia (lo definido forma parte de la definición).
- •
Sesgo de verificación: cuando se quiere comprobar la utilidad de una prueba diagnóstica se tiende a demostrar que la prueba que estamos evaluando es más útil que la que ya está establecida como estándar de referencia. El sesgo de verificación ocurre cuando solo aplicamos el estándar de referencia a los pacientes que han dado resultado positivo en la prueba a evaluar. Este tipo de error también conlleva un aspecto ético: ¿qué hacemos cuando el estándar de referencia puede conllevar efectos secundarios? (necesidad de biopsia o exploración quirúrgica); ¿se podría esperar para observar el desenlace? (a veces una espera puede significar un deterioro de salud si se retrasa el diagnóstico). En este punto, todos los médicos debemos ser conscientes de las limitaciones que en ocasiones tiene aplicar el estándar de referencia, porque no siempre es posible y debemos ser flexibles.
- •
Sesgo de seguimiento22: se produce cuando el test detecta un resultado que obliga a realizar un seguimiento para determinar finalmente el diagnóstico de enfermedad. Esto obliga a hacer controles periódicos para una enfermedad que en otra circunstancia no hubiera sido diagnosticada. Al contrario también puede pasar: a aquellos que den un resultado negativo no se les hace más pruebas, por lo que se podría incurrir en un infradiagnóstico (se pierde aquellos pacientes que realmente tienen la enfermedad).
Incluyen todos los errores sistemáticos que se producen durante la medición de las variables del estudio, en el proceso de recogida de datos26.
- •
Sesgo de progresión de la enfermedad: es exclusivo del diagnóstico por imagen. Ocurre cuando transcurre mucho tiempo entre la aplicación del test que se está evaluando y la aplicación del estándar de referencia. Pueden haber cambiado las características radiológicas de la enfermedad.
- •
Sesgo de variabilidad por observador: la experiencia y habilidad del observador son muy importantes. Como el diagnóstico por imagen requiere de interpretación, esto es particularmente relevante con vistas a la reproducibilidad. Debemos saber el número de observadores y experiencia de cada uno.
- •
Variabilidad intrínseca interobservador: cuando hay más de un observador. Hay que aportar el índice Kappa.
- •
Variabilidad interobservador extrínseca: solo es relevante cuando combinamos resultados de varios estudios diferentes. Las diferencias entre tecnologías deben ser consideradas.
- •
Variabilidad intraobservador: concierne a la subjetividad y reproducibilidad de un observador simple.
Las listas de verificación o comprobación son como unas «guías» que ayudan a los lectores a saber qué tipo de parámetros deben evaluar para saber si las conclusiones de un artículo son válidas o no.
Como hemos dicho anteriormente, dependiendo del diseño, debemos valorar unos parámetros u otros. Se elaboran por consenso de un grupo de expertos en la materia.
Así, se han elaborado listas muy minuciosas (donde entran a valorar aspectos desde qué debe contener el resumen o la discusión) y otras más pragmáticas, que son las que desde mi punto de vista debemos seguir al principio.
Vamos a ir viendo los aspectos más importantes de cada una de ellas.
STARD: The Standars for Reporting of Diagnostic Accuracy27Se aplican a los estudios sobre validez de pruebas diagnósticas. Constan de 25 ítems. Sus autores revisaron 33 listas de comprobación previamente publicadas, de las que extrajeron un total de 75 preguntas de entre las cuales seleccionaron las 25 finales. Además, también tienen un diagrama de flujo que explica cómo se reclutaron los pacientes y a quiénes se aplicó el estándar de referencia, la prueba a evaluar o ambas.
QUADAS: Quality Assessment of Diagnostic Accuracy Studies28Al igual que la anterior, también está relacionada con los estudios de diagnóstico. Inicialmente fue ideada para la evaluación de la calidad de los estudios primarios incluidos en revisiones sistemáticas. Al desarrollar esta herramienta, un grupo de expertos seleccionó los 14 ítems que cubrían aspectos relacionados con el diagnóstico y que deberían de aparecer en un estudio de validez de pruebas diagnósticas.
DELPHI List29Se realizó con el propósito de obtener un consenso sobre los ítems que debían aparecer para asegurar la calidad de los ensayos clínicos. Inicialmente constaba de 206 ítems, que fueron reducidos a 8 en la lista final. Según los autores, es importante comprobar en un ensayo clínico que la asignación de tratamientos se realizó de forma aleatoria y con enmascaramiento; que se obtuvieron grupos equiparables a excepción de la intervención; exponer los criterios de inclusión y exclusión y que se efectuó un análisis por intención de tratar.
CONSORT (Consolidated Standars of Reporting Trials)30Consiste en 25 ítems y un diagrama de flujo que utilizan los autores para asegurar la calidad de un ensayo clínico. Es utilizado por muchos comités editoriales para garantizar la calidad de los ensayos clínicos publicados. En el sitio web http://www.consort-statement.org puede encontrar una explicación de su elaboración y el documento final, que fue actualizado en 2010.
QUORUM: The Quality of Reporting of Meta-analyses31Se creó para valorar la calidad de los metaanálisis de los ensayos clínicos controlados. Consta de una lista de comprobación con 21 ítems y un diagrama de flujo que muestra información acerca del número de ensayos identificados, incluidos y excluidos y las razones de su exclusión. Los 21 ítems repasan el título (debe incluir que se trata de un metaanálisis o una revisión sistemática sobre ensayos clínicos), el resumen, la introducción, material y método (debe cubrir aspectos como la estrategia de búsqueda empleada, la selección de estudios, las características de los estudios y la síntesis de datos de forma cuantitativa), resultados (deben exponerse las características del estudio y presentar datos descriptivos de cada ensayo, además de presentar una síntesis de datos). Esta herramienta era tan completa, que la intentaron aplicar algunos investigadores para diseñar una revisión sistemática y les fue muy complicado, por lo que estuvo vigente solo un par de años.
PRISMA: Preferred Reporting Items for Systematic reviews and Meta-analyses32No es exactamente una lista de comprobación. Se trata de una actualización y expansión de la anterior. Se creó para facilitar la comprensión de las revisiones sistemáticas y no intentaba asegurar la calidad, sino la claridad y transparencia de las mismas.
AMSTAR: Assessment of multiple Systematic Reviews33Este instrumento fue construido sobre las herramientas previas, evidencia empírica y consenso de expertos. A partir de unas 100 preguntas, fueron seleccionando hasta llegar a las 11 principales que son las que componen el cuestionario.
La iniciativa CASPe34El grupo Critical Appraisal Skills Programme (CASP) (Programa de habilidades en lectura crítica) es un programa creado en el Institute of Health Sciences de Oxford que tiene por objetivo enseñar y difundir habilidades de búsqueda y lectura crítica de la evidencia para aplicarlas a la toma de decisiones diarias. En España, existe una red CASP (CASP España-CASPe), con múltiples nodos distribuidos por el territorio y una sede coordinadora ubicada en Alicante. CASPe forma parte de una organización internacional llamada CASP Internacional con la que comparte la filosofía docente, los materiales desarrollados en conjunto, las experiencias docentes y organizativas y los proyectos de investigación sobre docencia.
Entre sus materiales docentes, están las plantillas para realizar lectura crítica de cualquier tipo de artículo (ensayos clínicos, revisiones sistemáticas, estudios de diagnóstico, evaluación económica, estudios de pronóstico, estudios de casos y controles y estudios de cohortes). Todas las plantillas constan de diez preguntas, dividiéndolas en tres bloques principales:
- •
¿Son válidos los resultados del estudio? Aquí establecen unas preguntas de eliminación (si no son respondidas de forma afirmativa, el estudio tiene un error metodológico importante y sus conclusiones no son válidas) y unas preguntas de detalle (también son importantes, pero no invalidan el estudio).
- •
¿Cuáles son los resultados?
- •
¿Son los resultados aplicables a nuestro medio?
En algunos países como Estados Unidos, la lectura crítica se incluye dentro de las competencias profesionales de los médicos en formación, entre ellos los radiólogos1. Para facilitar este aprendizaje se han creado los clubes de lectura crítica (Jounals Clubs). La dinámica de estas sesiones es similar a la práctica de la RBE. Los residentes son los encargados de elegir los temas y los artículos. Hay un coordinador por sesión, que distribuye las diferentes tareas según el año de especialidad. Así, por ejemplo, los residentes de primer año se encargan de elaborar la pregunta de investigación. El objetivo principal es aprender a analizar y evaluar crítica y analíticamente un artículo. Tras varios años de funcionamiento, se ha demostrado que son una buena manera de formar a los residentes en las habilidades en RBE y para que aprendan conceptos estadísticos básicos y de diseño de estudio a través de la lectura crítica35.
ConclusiónRealizar una evaluación crítica de un artículo capacita a los profesionales para hacer un buen uso de la nueva información. Este hecho repercutirá de forma directa en el beneficio de nuestros pacientes, ya que se elegirá la opción más adecuada. Además, adquirir habilidades en lectura crítica también nos ayudará a mejorar nuestros proyectos de investigación y nuestros artículos, dado que podemos saber cuáles son los aspectos principales en los que se fijan los revisores y evaluadores y nuestros trabajos estarán mejor diseñados. Antes de comenzar a leer de forma minuciosa un artículo, se deben conocer una serie de aspectos generales como por ejemplo qué tipo de diseño tiene y si este diseño es el más adecuado para contestar nuestra pregunta de investigación. También se deben conocer los principales errores sistemáticos o sesgos. Las listas de verificación o la formación de clubes de lectura crítica son algunas de las herramientas que se han diseñado para facilitar el aprendizaje y la práctica de las habilidades en lectura crítica.
Conflicto de interesesLos autores declaran no tener ningún conflicto de intereses.

