




ChatGPT, un chatbot de inteligencia artificial (IA) generativa, es una herramienta prometedora de apoyo en el diagnóstico, en la toma de decisiones y en la educación en Cirugía Ortopédica y Traumatología (COT). El objetivo principal de este estudio es evaluar la capacidad de ChatGPT-4o para responder las preguntas de un examen teórico dirigido a residentes de COT. El objetivo secundario es comparar la tasa de aciertos y el patrón de respuestas obtenidos por este chatbot con los de los residentes, categorizados según sus años de experiencia.
MétodosEs un estudio observacional retrospectivo. Se ha analizado el examen teórico de COT realizado por residentes de un hospital terciario español en 2024. El examen incluyó 48 preguntas tipo test (10 con imagen), distribuidas entre distintas subespecialidades. Se registraron las respuestas de ChatGPT-4o y de los residentes para comparar las tasas de aciertos. Además, se analizó la capacidad de acertar preguntas en función de la temática y de la vinculación a imagen.
ResultadosChatGPT-4o respondió correctamente 34 de 48 preguntas (71%). La tasa de respuestas correctas de ChatGPT fue superior a la media de los residentes de COT (67%), obteniendo una puntuación similar a la de los residentes de quinto año (70%). Sin embargo, mostró una tasa de acierto mucho menor en las preguntas vinculadas a imagen clínica o radiológica (30%).
ConclusionesChatGPT-4o es capaz de responder preguntas de un examen teórico sobre COT, obteniendo una tasa de aciertos superior a la media de los residentes de COT y similar a la de los residentes de quinto año. No obstante, la tasa de errores fue del 29,2% y destacó una capacidad más limitada para acertar preguntas vinculadas a imágenes, así como cuestiones que exijan razonamiento clínico complejo. El uso de este modelo de IA no puede sustituir la experiencia y el razonamiento del profesional médico.
.
ChatGPT, a generative artificial intelligence (AI) chatbot, represents a potential tool to support diagnosis, decision-making, and education in Orthopaedic Surgery and Traumatology (OST). The primary aim of this study was to evaluate the ability of ChatGPT-4o to answer questions from a theoretical exam designed for OST residents. The secondary aim was to compare the chatbot's score and response patterns with those of residents, stratified by years of training.
MethodsThis was a retrospective observational study. A theoretical OST exam administered in 2024 to residents at a Spanish tertiary hospital was analyzed. The exam comprised 48 multiple-choice questions (10 including images) across different subspecialties. The responses of ChatGPT-4o and the residents were recorded to compare accuracy rates. In addition, the ability to correctly answer questions was analyzed according to topic and association with images.
ResultsChatGPT-4o correctly answered 34 out of 48 questions (71%). Its accuracy rate was higher than the average of OST residents (67%), achieving a score comparable to fifth-year residents (70%). However, its performance was notably lower in image-based clinical or radiological questions (30% accuracy).
ConclusionChatGPT-4o is capable of answering questions from a theoretical OST examination, achieving a score higher than the average of OST residents and comparable to that of the most experienced residents (fifth-year). However, the error rate was 29.2%, with a notably lower accuracy in questions involving images and those requiring complex clinical reasoning. The use of this AI model cannot replace the expertise and reasoning of medical professionals.
Durante la última década se ha producido un desarrollo muy significativo en inteligencia artificial (IA) y aprendizaje profundo (deep learning [DL]). Esta tecnología ha transformado la manera en que los humanos abordamos una amplia variedad de tareas, afectando también al ámbito científico y médico1. En particular, la aplicación de la IA ha ganado notable relevancia en el análisis de datos clínicos2, ya que la IA es especialmente eficaz en identificar patrones y realizar clasificaciones binarias3. La IA se ha desarrollado también en el área de la Cirugía Ortopédica y Traumatología (COT), donde su uso se está diversificando rápidamente. Se ha incorporado en la educación del paciente y del profesional, así como en la formación específica quirúrgica4. También ha incrementado su uso en investigación científica COT5,6. Finalmente, puede intervenir en distintas fases del proceso asistencial, como la planificación preoperatoria7,8 o la predicción de resultados clínicos9.
En este contexto, ha surgido ChatGPT (OpenAI®, San Francisco, EE.UU.), un chatbot de IA generativa que emplea modelos de lenguaje de gran escala (large language models [LLM]). Ha demostrado capacidades avanzadas en el procesamiento y la generación de texto en lenguaje natural. Entrenado con grandes volúmenes de datos, este modelo es capaz de interpretar preguntas complejas, analizar de manera contextualizada y generar respuestas argumentadas10, lo que lo posiciona como una herramienta prometedora en entornos educativos y clínicos.
Diversos estudios han evaluado los conocimientos médicos de ChatGPT mediante la capacidad para responder preguntas de examen en distintas especialidades médicas, incluyendo el ámbito de COT. Se han reportado tasas de acierto que varían entre el 35.8% y el 76%, según el país, la versión del modelo utilizada y la complejidad de las preguntas11-14.
El objetivo principal de este estudio es evaluar la capacidad de ChatGPT (versión 4o) para responder las preguntas de un examen teórico dirigido a residentes de COT en un hospital de tercer nivel en España. El objetivo secundario es comparar la tasa de aciertos y el patrón de respuestas obtenidos por este chatbot con los de los residentes, categorizados según sus años de experiencia.
MétodosDiseño del estudioEn este estudio comparativo se ha evaluado la capacidad de un modelo de IA generativa (ChatGPT) para responder preguntas de un examen teórico sobre COT. Para el desarrollo de esta investigación se han seguido las recomendaciones de la guía «TRIPOD+AI». Se ha tomado como referencia el examen teórico realizado previamente (2024) a los residentes de COT de un hospital de tercer nivel español. Dicho examen se realiza cada año en el hospital para evaluar el nivel de competencia teórica en COT de los residentes del servicio. El examen es diseñado internamente por los especialistas del servicio de COT. La residencia consta de cinco años, habiendo seis residentes cada año. En el año 2024, este examen escrito contó con 48 preguntas tipo test, con cuatro opciones de respuesta donde solo una era correcta y los errores no restaban puntuación. Diez de las preguntas estaban vinculadas a una imagen clínica o radiológica. Las preguntas estaban divididas equitativamente entre las siguientes subespecialidades: reconstrucción osteoarticular séptica, COT-pediátrica, cirugía de rodilla, cirugía de tobillo-pie, cirugía de antebrazo-mano, cirugía de cadera, reconstrucción osteoarticular oncológica, cirugía de hombro, traumatología y cirugía de raquis.
Se recogieron las respuestas, la tasa de acierto y las puntuaciones de los residentes COT mediante la base de datos electrónica prospectiva del Servicio COT. Se analizó la tasa de acierto en función del año de experiencia de los residentes, la temática de la pregunta y la vinculación o no a imagen. Estos resultados se compararon con los proporcionados por ChatGPT.
Modelo de IASe usó la versión más reciente del modelo ChatGPT (Chat Generative Pre-trained Transformer; OpenAI®, San Francisco, EE.UU.) disponible en el momento de realizar el estudio: ChatGPT-4o. Se usó el siguiente prompt para optimizar la capacidad de respuesta del sistema de IA: «Tu tarea consiste en responder preguntas sobre cirugía ortopédica y traumatología. Yo proporcionaré las preguntas. Se trata de preguntas tipo test, donde solo una opción es correcta. Debes elegir la opción correcta. Quiero que actúes como un cirujano ortopédico experto. Debes basarte en todos los conocimientos disponibles sobre cirugía ortopédica y traumatología, así como los estándares de manejo establecidos como referencia actual y estar actualizado con los hallazgos de investigación más recientes en el campo. Si no estás seguro de una respuesta, utiliza tus herramientas para obtener información relevante. Debes analizar cuidadosamente cada respuesta antes de responder». Cada pregunta se realizó una única vez. Después de cada respuesta del chatbot se abrió un nuevo chat para realizar la siguiente pregunta, con el objetivo de garantizar la independencia de las respuestas entre sí. Las preguntas se realizaron en castellano o catalán, copiando el formato y el idioma original de cada pregunta.
Análisis estadísticoLas variables categóricas se describieron mediante sus valores absolutos, fracciones y porcentajes. Las variables continuas se presentaron mediante su media y desviación estándar. Los grupos se compararon utilizando la prueba Z-test para proporciones. Todos los valores de p fueron bilaterales. Se consideró estadísticamente significativo un valor de p<0,05. El análisis estadístico se realizó utilizando IBM SPSS v. 20.0 (IBM Corp., Armonk, NY, EE.UU.).
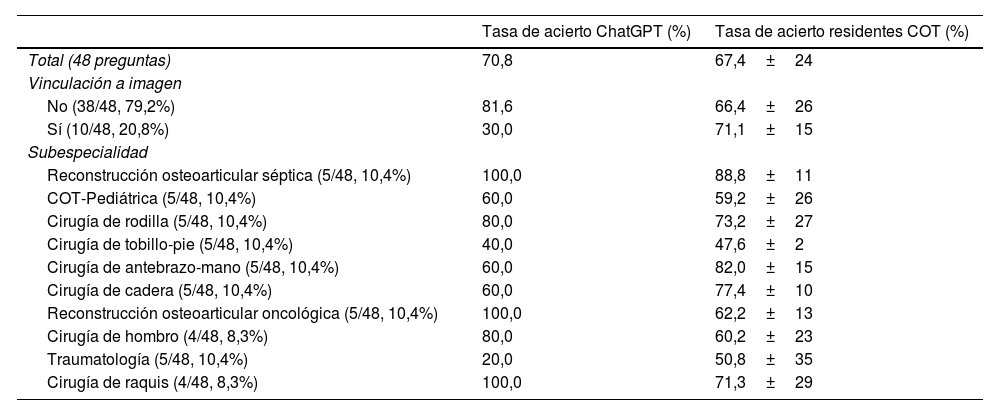
ResultadosModelo de IAChatGPT acertó 34 de 48 preguntas, correspondiendo a una tasa de acierto del 71%. La distribución de la tasa de aciertos en función de la temática de las preguntas se encuentra en la tabla 1. Destaca que solo acertó el 30% de las preguntas (3/10) vinculadas a imagen clínica o radiológica, siendo un resultado significativamente inferior a su tasa media de acierto (p<0,01). No hubo diferencias en la tasa de aciertos entre las preguntas redactadas en castellano o en catalán: 23/33 (70%) vs 11/15 (73%); p=0,8.
Distribución de la tasa de aciertos de las preguntas teóricas de un examen sobre COT realizado por ChatGPT y por residentes de COT. Se analizan los resultados en función de la subespecialidad temática y de la presencia de imagen en la pregunta
| Tasa de acierto ChatGPT (%) | Tasa de acierto residentes COT (%) | |
|---|---|---|
| Total (48 preguntas) | 70,8 | 67,4±24 |
| Vinculación a imagen | ||
| No (38/48, 79,2%) | 81,6 | 66,4±26 |
| Sí (10/48, 20,8%) | 30,0 | 71,1±15 |
| Subespecialidad | ||
| Reconstrucción osteoarticular séptica (5/48, 10,4%) | 100,0 | 88,8±11 |
| COT-Pediátrica (5/48, 10,4%) | 60,0 | 59,2±26 |
| Cirugía de rodilla (5/48, 10,4%) | 80,0 | 73,2±27 |
| Cirugía de tobillo-pie (5/48, 10,4%) | 40,0 | 47,6±2 |
| Cirugía de antebrazo-mano (5/48, 10,4%) | 60,0 | 82,0±15 |
| Cirugía de cadera (5/48, 10,4%) | 60,0 | 77,4±10 |
| Reconstrucción osteoarticular oncológica (5/48, 10,4%) | 100,0 | 62,2±13 |
| Cirugía de hombro (4/48, 8,3%) | 80,0 | 60,2±23 |
| Traumatología (5/48, 10,4%) | 20,0 | 50,8±35 |
| Cirugía de raquis (4/48, 8,3%) | 100,0 | 71,3±29 |
COT: Cirugía Ortopédica y Traumatología.
Los residentes de COT acertaron de media el 67,4% de las preguntas (67,4±0,9) (tabla 1). Se observó un incremento progresivo en la media de tasa de acierto en función de los años de experiencia de los residentes (R): R1 (54±6), R2 (56±8), R3 (62±9), R4 (69±6) y R5 (70±3) (fig. 1). No se encontraron diferencias en la tasa de acierto entre las preguntas con o sin imagen: 71,1% vs 66,4% (p=0,7).
 obtenida en un examen teórico sobre COT entre el modelo de IA ChatGPT (color naranja, patrón sombreado cuadrícula) y residentes de COT categorizados según sus años de experiencia (color verde, patrón sombreado punteado). COT: Cirugía Ortopédica y Traumatología; R: residente.")
Gráfico comparando la tasa de aciertos (%) obtenida en un examen teórico sobre COT entre el modelo de IA ChatGPT (color naranja, patrón sombreado cuadrícula) y residentes de COT categorizados según sus años de experiencia (color verde, patrón sombreado punteado).
COT: Cirugía Ortopédica y Traumatología; R: residente.
La tasa de aciertos obtenida por ChatGPT en el examen teórico en COT fue superior a la tasa media de los residentes de COT (71% vs 67%). De hecho, la puntuación de este modelo de IA fue parecida a la media obtenida por los residentes de quinto año (71% vs 70%) (fig. 1). Sin embargo, su tasa de acierto fue muy inferior en las preguntas vinculadas a imagen (30% vs 71%) (tabla 1).
DiscusiónEl resultado más relevante de este estudio es que ChatGPT-4o presentó un 29,2% de errores al responder preguntas sobre COT en un examen teórico dirigido a residentes. Destaca también que mostró una tasa de acierto significativamente menor en las cuestiones vinculadas a imagen clínica o radiológica (30%). No obstante, la tasa de respuestas correctas de ChatGPT fue superior a la tasa media de los residentes de COT (71% vs 67%), obteniendo una puntuación similar a la de los residentes de quinto año (71% vs 70%).
ChatGPT es un modelo de IA basado en LLM que ha sido entrenado con una enorme cantidad de texto generado por humanos, incluyendo publicaciones científicas15. Gracias a este entrenamiento, maneja un volumen masivo de datos al tratar cuestiones relacionadas con distintas especialidades médicas. Una de las ventajas más destacadas de ChatGPT es su capacidad para comprender lenguaje natural y generar texto original de forma coherente y contextualizada. Esto permite que el usuario le pueda realizar preguntas y mantener un diálogo lógico. Todos estos factores hacen que ChatGPT sea una herramienta con mucho potencial en el entorno médico16. Las últimas versiones de este sistema de IA también permiten integrar, interpretar y generar imágenes. Sin embargo, estudios previos han evidenciado que tareas aparentemente sencillas, como el reconocimiento de imágenes u objetos, pueden suponer un reto considerable para los modelos de IA, ya que involucran procesos cognitivos abstractos que resultan difíciles de codificar y de replicar en sistemas basados en lenguaje natural como los chatbots17,18. El potencial en el análisis de imágenes de ChatGPT aún no ha sido plenamente desarrollado19. De hecho, en nuestro estudio destaca que ChatGPT presentó una tasa de acierto muy inferior en las preguntas vinculadas a imagen (30% vs 71%). Adicionalmente, se observó que podía confundir zonas de la imagen de escasa definición con un trazo de fractura, y por este motivo es recomendable utilizar documentos con buena calidad visual al valorar imágenes radiológicas por ChatGPT.
Nuestros resultados son comparables a los obtenidos por la versión ChatGPT-4o al realizar exámenes sobre la especialidad de COT en otros países. Pamuk et al. observaron una tasa de acierto del 76% en el Turkish Orthopedics and Traumatology Board Examination, obteniendo una nota superior al 98,7% de los candidatos humanos11. Maraqa et al. reportaron una puntuación del 74,8% en el French Orthopedic and Trauma Surgery Exam, superior a la del 70,8% obtenida por los residentes13. Estos autores destacaron la alta capacidad de ChatGPT para responder preguntas teóricas en formato texto. Sin embargo, Cuthbert y Simpson evaluaron la capacidad de ChatGPT para superar el examen de Fellowship del Royal College of Surgeons en COT y observaron que el modelo alcanzó únicamente un 35,8% de respuestas correctas14. Esta puntuación fue significativamente inferior al umbral de aprobación del examen y a la media obtenida por los candidatos humanos. Entre las principales limitaciones identificadas en ChatGPT se encontraron su incapacidad para ejercer juicio clínico y la falta de razonamiento lógico requerido para resolver preguntas que demandan un procesamiento cognitivo más complejo. Esta debilidad también se evidenció en nuestro estudio. Observamos que ChatGPT presenta una elevada capacidad para resolver preguntas teóricas directas, ya que es capaz de obtener la información a través del volumen inmenso de datos con los que se ha entrenado. Sin embargo, tiene más dificultades para resolver preguntas relacionadas con un caso clínico o que requieran un razonamiento complejo. Por ejemplo, el modelo de IA no supo responder correctamente una pregunta sobre cómo equilibrar la tensión ligamentosa en una prótesis de rodilla con una discrepancia entre la laxitud en flexión-extensión (sin embargo, esta pregunta fue acertada por el 65% de residentes). Por otro lado, también detectamos la dificultad de ChatGPT para entender conceptos más inespecíficos como «relevante» o «probable», más fácilmente comprensibles para los candidatos humanos. Por todo esto, es probable que las diferencias observadas en las tasas de acierto entre subespecialidades (tabla 1) no se explican necesariamente por el nivel de conocimiento en cada área, sino más posiblemente por la naturaleza y el enfoque de las preguntas formuladas, así como por la presencia de cuestiones vinculadas a imagen. Estos resultados refuerzan la necesidad de evaluar de manera crítica la fiabilidad y la aplicabilidad de la IA en escenarios clínicos reales, especialmente en aquellos de alta complejidad20.
Existen múltiples sistemas de IA generativa basados en lenguaje natural, como Claude, GROK, Gemini o DeepSeek, que presentan sus particularidades, sus pros y sus contras. A pesar de sus claros beneficios, todos los chatbots enfrentan aún limitaciones estructurales. 1)Problemas de sesgo y generalización, ya que estos modelos reproducen las limitaciones presentes en sus datos de entrenamiento. Por ejemplo, la infrarrepresentación de ciertas subpoblaciones en bases de datos clínicas puede generar recomendaciones diagnósticas o terapéuticas inadecuadas para estos pacientes21,22. 2)Falta de empatía y juicio clínico adaptativo, limitando su utilidad en contextos médicos complejos23. 3)Problemas relacionados con la privacidad y la propiedad de los datos clínicos de los pacientes24. Por ejemplo, al plantear preguntas al chatbot usando documentos o texto que contengan datos personales. 4)Falta de claridad en la asignación de responsabilidades, que plantea riesgos legales frente a errores cometidos al seguir las recomendaciones de la IA25. 5)Controversias éticas26. 6)Falta de explicabilidad; el modelo procesa los datos de entrada y genera una salida de forma opaca, sin proporcionar información sobre el razonamiento subyacente (modelos de «caja negra»)27. 7)Falta de confianza en el sistema de IA y miedo a la pérdida de capacidades humanas27. 8)Riesgo de alucinaciones, situaciones donde la IA responde con contundencia y de forma convincente, aunque no tenga certeza de la información que proporciona o incluso haya generado una respuesta ficticia28. Todas estas limitaciones deben ser detectadas, reconocidas y comunicadas claramente, con el objetivo de que los profesionales clínicos comprendan el alcance y las restricciones actuales de estos sistemas.
Los resultados de este estudio confirman el potencial de la IA en el ámbito de la COT. Sin embargo, a pesar de que ChatGPT obtuvo una puntuación superior a la media de candidatos humanos, destaca que presentó un 29,2% de respuestas erróneas en un examen dirigido a residentes. Este dato es relevante, porque este chatbot puede ser una herramienta de consulta habitual para los cirujanos en formación. Por ello, la implementación de la IA debe enmarcarse dentro de una estrategia supervisada y crítica, subrayando la importancia de seguir promoviendo el razonamiento clínico, la humanización de la medicina, la seguridad del paciente y la ética en la formación de los residentes. En estos aspectos, los profesionales humanos continúan siendo insustituibles frente a la IA.
Este estudio presenta limitaciones. El uso de un único modelo de IA (ChatGPT) limita la posibilidad de generalizar los hallazgos a otros modelos. Además, el estudio refleja la capacidad para responder preguntas sobre COT por una versión concreta de ChatGPT (4o), por lo que futuras actualizaciones del modelo podrían modificar su eficacia. El prompt concreto usado al realizar las preguntas y el número de iteraciones también podría influir en los resultados. Por otro lado, el examen se llevó a cabo por residentes de un único centro. Aun así, en el hospital del estudio se forman seis residentes cada año, aportando un número considerable de candidatos humanos. Aunque se trata de un examen no oficial, este test se realiza cada año y sigue un formato y una estructura similares a los de otras pruebas formales. La heterogeneidad en la redacción de las preguntas debido a que han sido escritas por diferentes profesionales también puede haber afectado a la capacidad de ChatGPT para responder correctamente. Finalmente, el tamaño muestral y el número de preguntas relativamente pequeños podría limitar el poder estadístico del estudio.
Son fortalezas del estudio el haber evaluado tanto preguntas en formato texto como vinculadas a imagen, ofreciendo un análisis más completo sobre las capacidades de este modelo de IA. Además, se ha comparado la tasa de aciertos y patrón de respuestas obtenidos por el chatbot con los de los residentes, considerando también sus años de experiencia. Finalmente, se ha usado un prompt exhaustivo (reflejado en el apartado métodos) para optimizar la capacidad de respuesta del sistema.
ConclusionesChatGPT-4o es capaz de responder preguntas de un examen teórico sobre COT, obteniendo una tasa de aciertos superior a la media de los residentes de COT y similar a la de los residentes de quinto año. Este hallazgo refuerza su potencial como herramienta de apoyo y formación dentro del ámbito médico. No obstante, la tasa de errores fue del 29,2% y destacó una capacidad más limitada para acertar preguntas vinculadas a imágenes clínicas o radiológicas, así como cuestiones que exijan razonamiento clínico complejo. El uso de este modelo de IA no puede sustituir la experiencia y el razonamiento del profesional médico; debe enmarcarse dentro de una estrategia de implementación crítica y supervisada, garantizando la seguridad del paciente y la responsabilidad ética.
Nivel de evidenciaNivel de evidencia IV.
FinanciaciónEsta investigación no recibió ninguna subvención específica de organismos de financiación de los sectores público, comercial o sin ánimo de lucro.
Consideraciones éticasEl estudio estuvo exento de aprobación ética, y se le concedió la exención de exigir el consentimiento por escrito de los pacientes.
Contribución de los autoresTodos los autores contribuyeron por igual a este trabajo. Todos los autores contribuyeron en la concepción y el diseño del estudio, la preparación del material, la recopilación y el análisis de datos. El primer borrador del manuscrito fue escrito por OP, y todos los autores comentaron las versiones del manuscrito. Todos los autores leyeron y aprobaron el manuscrito final.
Conflicto de interesesNinguno.
