










Low-density lipoprotein cholesterol (LDL-C) is a significant cardiovascular risk factor, as direct measurement is expensive and often unavailable in most clinical laboratories. The Friedewald formula (FD), despite its widespread use since 1972, has notable limitations, especially at high triglyceride levels and low LDL-C concentrations. Machine learning (ML) techniques offer promising alternatives for accurate LDL-C estimation, potentially overcoming traditional formula limitations by leveraging complex pattern recognition in lipid profile data.
Material and methodsThis retrospective study analyzed 34,678 lipid profiles from patients over 18 years attending Hospital Virgen Macarena, Seville (January 2021–December 2022). The study was approved by the Ethics Committee (CEI HVM-VR_03/2024). All lipid parameters (total cholesterol, triglycerides, HDL-C, LDL-C) were measured using Cobas 6000 analyzer. Twenty-two machine learning models were developed using Python's PyCaret library with 80/20 train-test split. Models included Linear Regression, Random Forest, XGBoost, LightGBM, and Gradient Boosting among others. Performance was evaluated using coefficient of determination (R2), mean absolute error (MAE), and root mean square error (RMSE). Four triglyceride subgroups were analyzed: <150, 150–250, 250–400, and >400mg/dL.
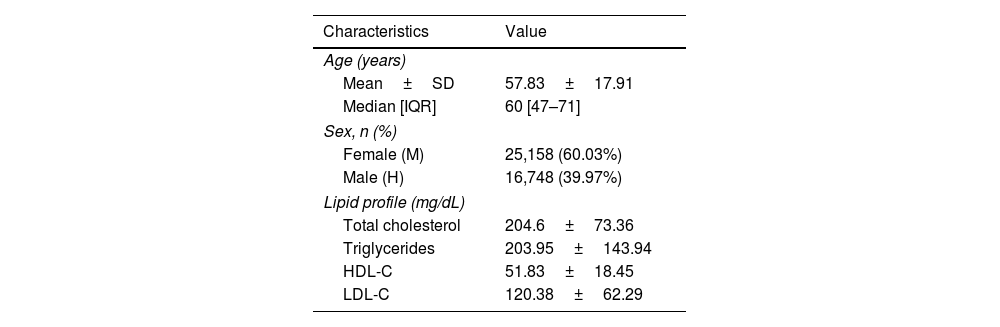
ResultsThe dataset comprised 34,678 individuals with mean values: total cholesterol 204.6±73.36mg/dL, triglycerides 203.95±143.94mg/dL, HDL-C 51.83±18.45mg/dL, and LDL-C 120.38±62.29mg/dL. LightGBM achieved the highest performance (R2=0.965, RMSE=11.35, MAE=7.99), followed by Gradient Boosting (R2=0.962, RMSE=11.89, MAE=7.87) and XGBoost (R2=0.958, RMSE=12.49, MAE=8.3). Traditional formulas showed inferior performance: Martin–Hopkins (R2=0.951, RMSE=13.82, MAE=9.3) and Friedewald (R2=0.926, RMSE=16.92, MAE=11.97). Performance differences were more pronounced at triglyceride levels≥250mg/dL, with ML models maintaining R2>0.92 while classical formulas deteriorated significantly, particularly Friedewald (R2=0.34) at triglycerides>400mg/dL.
ConclusionsMachine learning models, particularly boosting algorithms (LightGBM, Gradient Boosting, XGBoost), significantly outperformed traditional LDL-C calculation formulas across all triglyceride ranges. These AI-based approaches yielded superior accuracy and robustness, especially in challenging clinical scenarios with elevated triglycerides where conventional formulas fail. Implementation of ML models in clinical laboratories could provide more reliable LDL-C estimations, contributing to improved cardiovascular risk stratification and patient management. This technological advancement represents a promising transformation in laboratory medicine methodology.
El colesterol de lipoproteínas de baja densidad (c-LDL) es un factor de riesgo cardiovascular significativo, siendo su medición directa costosa y no disponible en la mayoría de los laboratorios clínicos. La fórmula de Friedewald (FD), a pesar de su uso generalizado desde 1972, presenta limitaciones particularmente en niveles altos de triglicéridos y concentraciones bajas de c-LDL. Las técnicas de aprendizaje automático (ML) ofrecen alternativas prometedoras para la estimación precisa del c-LDL, superando potencialmente las limitaciones de las fórmulas tradicionales mediante el reconocimiento de patrones complejos en los datos del perfil lipídico.
Material y métodosEste estudio retrospectivo analizó 34.678 perfiles lipídicos de pacientes mayores de 18 años que acudieron al Hospital Universitario Virgen Macarena, Sevilla (enero 2021-diciembre 2022). Se obtuvo la aprobación del estudio por el Comité de Ética (CEI HVM-VR_03/2024). Todos los parámetros lipídicos (colesterol total, triglicéridos, c-HDL, c-LDL) se midieron utilizando el analizador Cobas 6000. Se desarrollaron 22 modelos de aprendizaje automático utilizando la librería PyCaret de Python con división 80/20 entrenamiento-prueba. Los modelos incluyeron Regresión Lineal, Random Forest, XGBoost, LightGBM y Gradient Boosting, entre otros. El rendimiento se evaluó utilizando el coeficiente de determinación (R2), error absoluto medio (MAE) y error cuadrático medio (RMSE). Se analizaron cuatro subgrupos de triglicéridos: <150, 150-250, 250-400 y >400mg/dL.
ResultadosEl conjunto de datos comprendió 34.678 individuos con valores medios: colesterol total 204,6±73,36mg/dL, triglicéridos 203,95±143,94mg/dL, c-HDL 51,83±18,45mg/dL y c-LDL 120,38±62,29mg/dL. LightGBM alcanzó el mayor rendimiento (R2=0,965, RMSE=11,35, MAE=7,99), seguido por Gradient Boosting (R2=0,962, RMSE=11,89, MAE=7,87) y XGBoost (R2=0,958, RMSE=12,49, MAE=8,3). Las fórmulas tradicionales mostraron rendimiento inferior: Martin-Hopkins (R2=0,951, RMSE=13,82, MAE=9,3) y Friedewald (R2=0,926, RMSE=16,92, MAE=11,97). Las diferencias de rendimiento se hicieron más evidentes en niveles de triglicéridos ≥ 250mg/dL, con los modelos de ML manteniendo R2> 0,92 mientras que las fórmulas clásicas se deterioraron significativamente, particularmente Friedewald (R2=0,34) con triglicéridos> 400mg/dL.
ConclusionesLos modelos de aprendizaje automático, particularmente los algoritmos de boosting (LightGBM, Gradient Boosting, XGBoost), superaron significativamente a las fórmulas tradicionales de cálculo del c-LDL en todos los rangos de triglicéridos. Estos enfoques basados en IA demostraron precisión y robustez superiores, especialmente en escenarios clínicos desafiantes con triglicéridos elevados donde las fórmulas convencionales fallan. La implementación de modelos de ML en laboratorios clínicos podría proporcionar estimaciones más confiables del c-LDL, contribuyendo a una mejor estratificación del riesgo cardiovascular y manejo de pacientes. Este avance tecnológico representa una transformación prometedora en la metodología de la medicina de laboratorio.