La finalidad de un estudio de investigación consiste en el análisis de la variable resultado al exponer a la muestra de estudio a una determinada actuación, como puede ser la administración de un fármaco o la implementación de una intervención farmacéutica concreta.
Para poder determinar una relación entre el resultado obtenido y la exposición a esta actuación, es condición imprescindible que las muestras (de intervención y de control) sean absolutamente homogéneas, esto es, que todas las características presentadas sean similares, con la única diferencia entre ellas de la exposición al factor analizado.
Homogeneidad de muestras
El primer análisis, que debe corroborar que las muestras en las que se efectuará el estudio correspondiente son similares, es el de homogeneidad de muestras. Mediante éste se podrá indicar, con suficiente confianza, que el cambio final de la variable resultado se debe a la exposición a la intervención farmacéutica implementada y no a otras causas posibles, puesto que el azar puede explicar las diferencias posibles entre las dos muestras iniciales. Es decir, no es preciso que las muestras sean idénticas en todas sus características, pero sí que las diferencias existentes se deban exclusivamente al azar y que éste sea el único que pueda justificarlas.
Efectivamente, la variabilidad interpersonal hace que todos seamos intrínsecamente iguales, a la vez que extrínsecamente diferentes. Dos personas pueden presentar un peso parecido pero no idéntico, por ejemplo 82,900 y 83,100 kg y el sentido común nos dirá que ambas «pesan igual»; igualmente, dos personas pueden tener pesos que también el sentido común nos indica que «pesan distinto», como 82,900 y 107,500 kg. Ahora bien, ¿cuál es el umbral de diferencia para considerar que pesan igual o distinto? Puesto que sí se sabe que el peso guarda cierta relación con el riesgo de incidencia de diabetes tipo 2, sería muy deseable en un estudio de intervención en esta enfermedad que el peso medio de los individuos expuestos a la intervención y de los no expuestos o de control presenten inicialmente un valor similar.
Análisis de valores medios
De esta forma, se partirá de dos muestras, en el caso más básico pero también más habitual, que presentan un valor medio de la variable de interés, por ejemplo su peso, de P para el grupo de intervención y P' para el de control. Es obvio, entonces, que el análisis de homogeneidad para establecer que los dos pesos son similares trate de demostrar que la diferencia (D) del peso medio entre ambas muestras no es estadísticamente significativa, es decir, que (P - P') tiene un valor que puede ser explicado simplemente por el azar. Si éste no fuera capaz de explicar esta diferencia, concluiríamos que la diferencia entre el peso medio de las dos muestras es estadísticamente significativa y, por lo tanto, las muestras no serían homogéneas respecto del peso.
¿Cómo se puede determinar si el azar explica o no la diferencia entre los dos valores medios del peso? Para ello, imaginemos que se repite muchas veces (n) el proceso de formación de las dos muestras. Se pesaría entonces a los individuos de cada muestra y se estimaría su valor medio (P1, P2, [...], Pn y P'1, P'2, [...], P'n). Una vez que se hubieran pesado los integrantes de todas las muestras, si hubieran sido éstas homogéneas, el valor medio de todas las diferencias (D1, D2, [...], Dn) sería 0.
Como el azar ha intervenido para que se incluyan individuos con mayor o menor peso, es posible encontrar en las muestras personas que presenten pesos diferentes, habiendo entonces muestras que exhiben una diferencia al alza o a la baja, diferencia que sería más rara de encontrar cuanto más diferente fuera del valor de 0. Si existiera alguna otra circunstancia diferente del azar que justificara una mayor diferencia de peso entre ambas muestras, por ejemplo, que una muestra se extraiga de una población que haga ejercicio habitualmente y la otra no, la diferencia de muestras ya no podría ser explicada únicamente por el azar.
Umbral de la diferencia
Entonces, la pregunta clave es dónde ubicar el límite de la diferencia entre los valores medios de los pesos, para que el azar justifique o no la diferencia hallada.
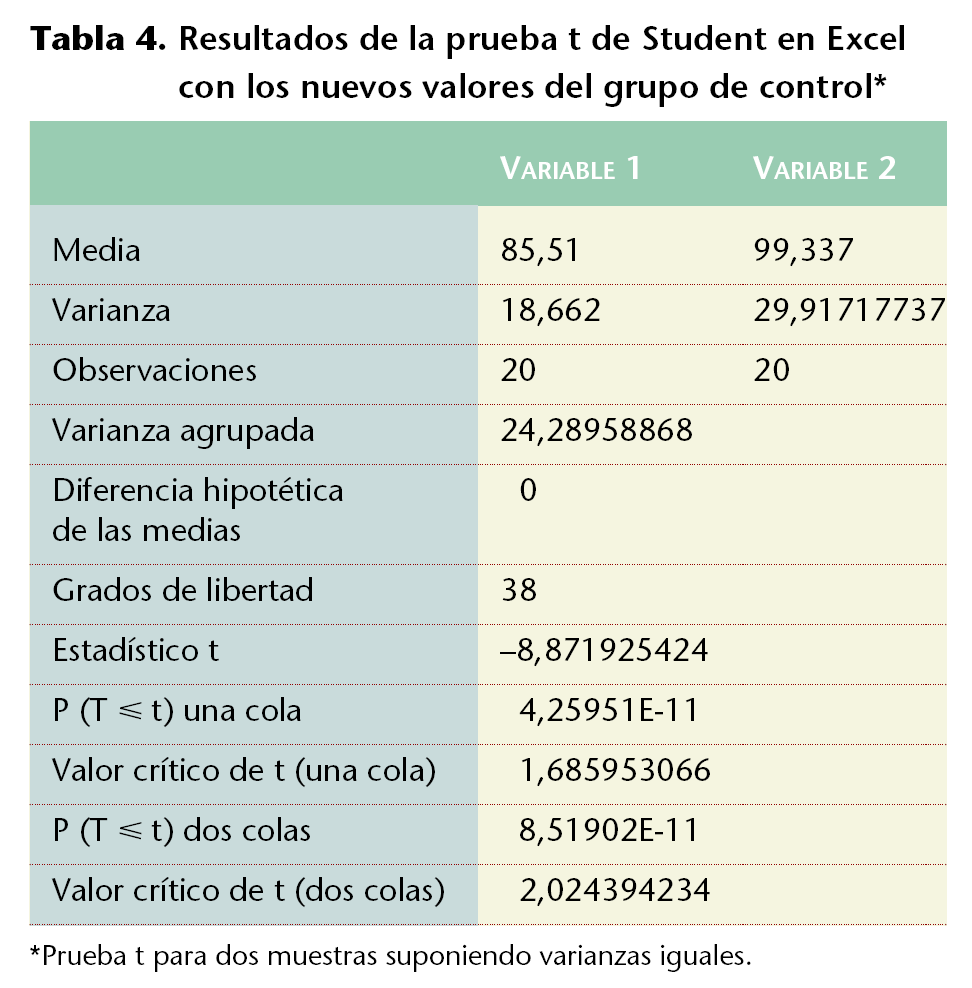
Si se hubiera repetido muchas veces (n) la extracción de las dos muestras, los valores de cada diferencia (D1, D2, [...], Dn) en cada par de muestras seguirían una distribución normal. Recuérdese, entonces, que se tendrá el 95% de confianza de hallar los valores de D entre su media (que se dijo que era 0) y 2 veces el error estándar. Si esto se cumple, significaría que el azar es lo único que puede explicar la diferencia hallada y, por lo tanto, las muestras son homogéneas. Si la diferencia supera el valor de 2 veces el error estándar, ello se debe a que sólo el azar no puede explicar esta diferencia y las muestras no serán homogéneas.
Si el tamaño de las muestras es menor de 30 individuos, la distribución resultante de la repetición teórica de la extracción de muestras no sería la normal, sino la llamada t de Student, por lo que el umbral de la diferencia ya no sería 2 veces el error estándar, sino que se emplearía el valor correspondiente a la distribución t de Student.
Cálculo práctico
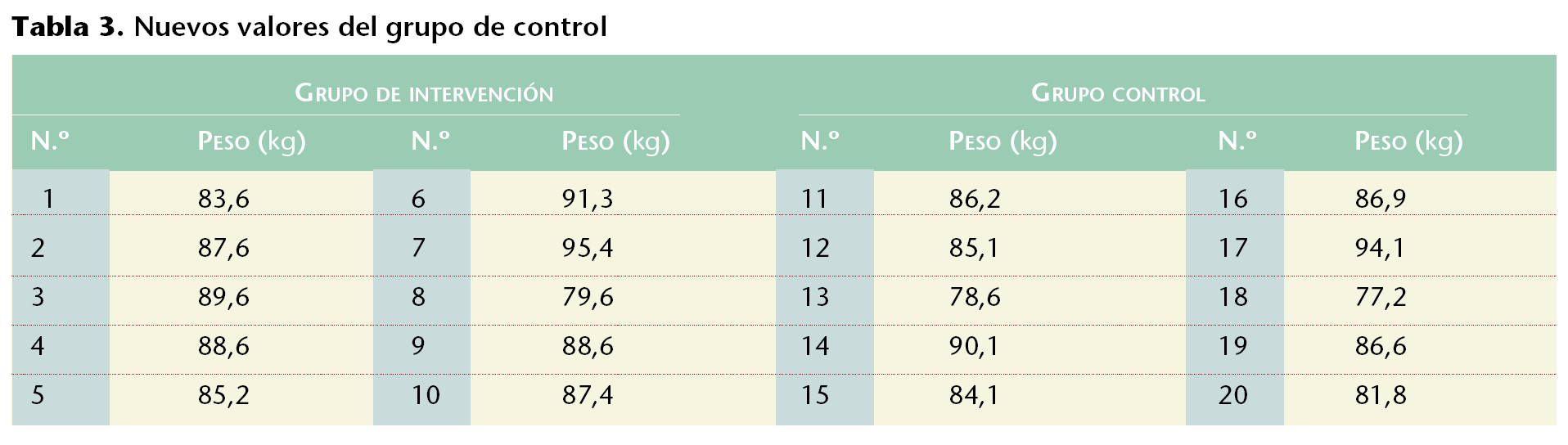
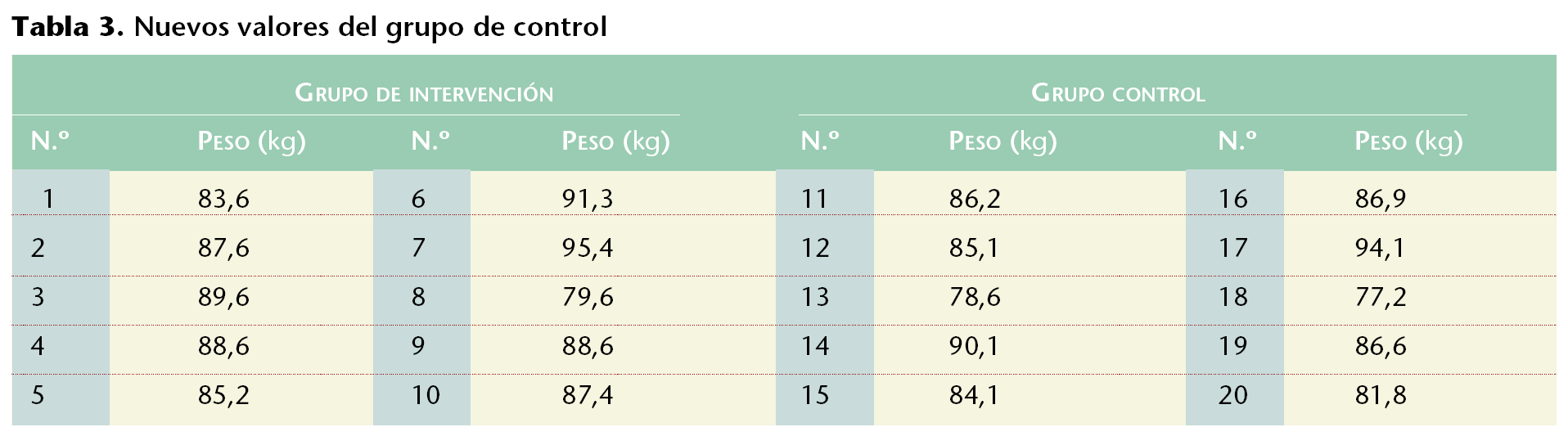
Supongamos que se dispone de dos muestras, cuyos pesos se reflejan en la tabla 1. En Excel se dispondrán todos los valores de cada variable en una columna (columna A para el número, B para el peso de los integrantes del grupo de intervención, C para el número y D para el peso de los integrantes del grupo de control).
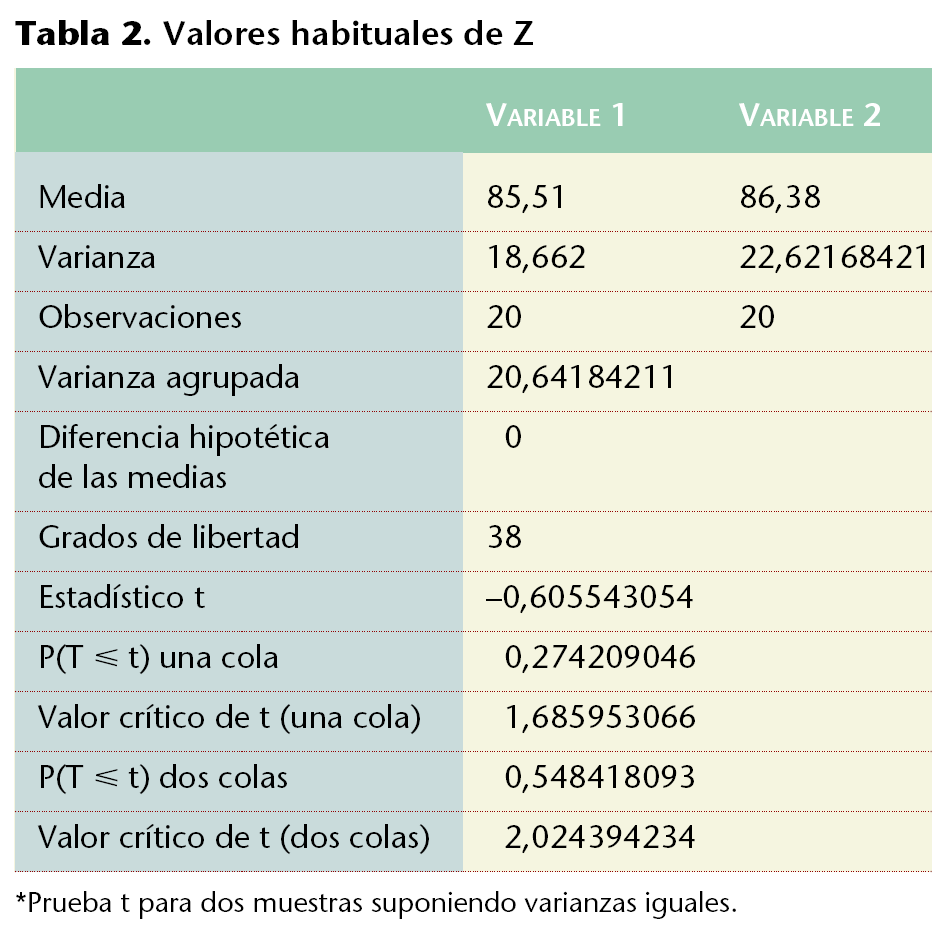
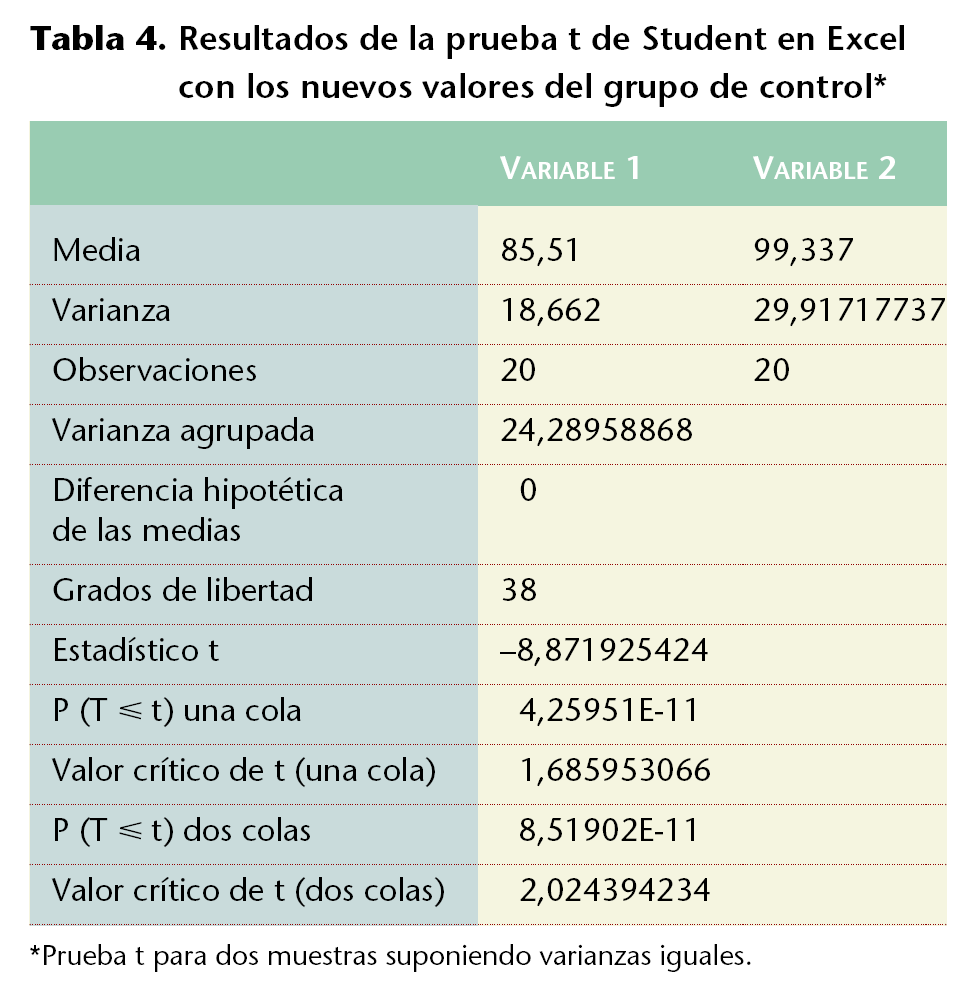
En Excel se puede efectuar fácilmente el análisis de homogeneidad de estas muestras, respecto del peso: en [Herramientas/Análisis de datos/Prueba t para dos muestras suponiendo varianzas iguales] se realiza la prueba de t de Student. Ello se hará indicando los rangos de las variables (B2:B21 y D2:D21) con una diferencia hipotética entre las medias de 0 y un alfa de 0,05. Especificando el rango de salida en una celda vacía (p. ej., A25) quedará una tabla (tabla 2) en la que se ha estimado el valor de la p (de dos colas) que al ser superior a 0,05 puede explicar, con un grado de significación del 95% que la diferencia hallada no es estadísticamente significativa y se debe exclusivamente al azar.
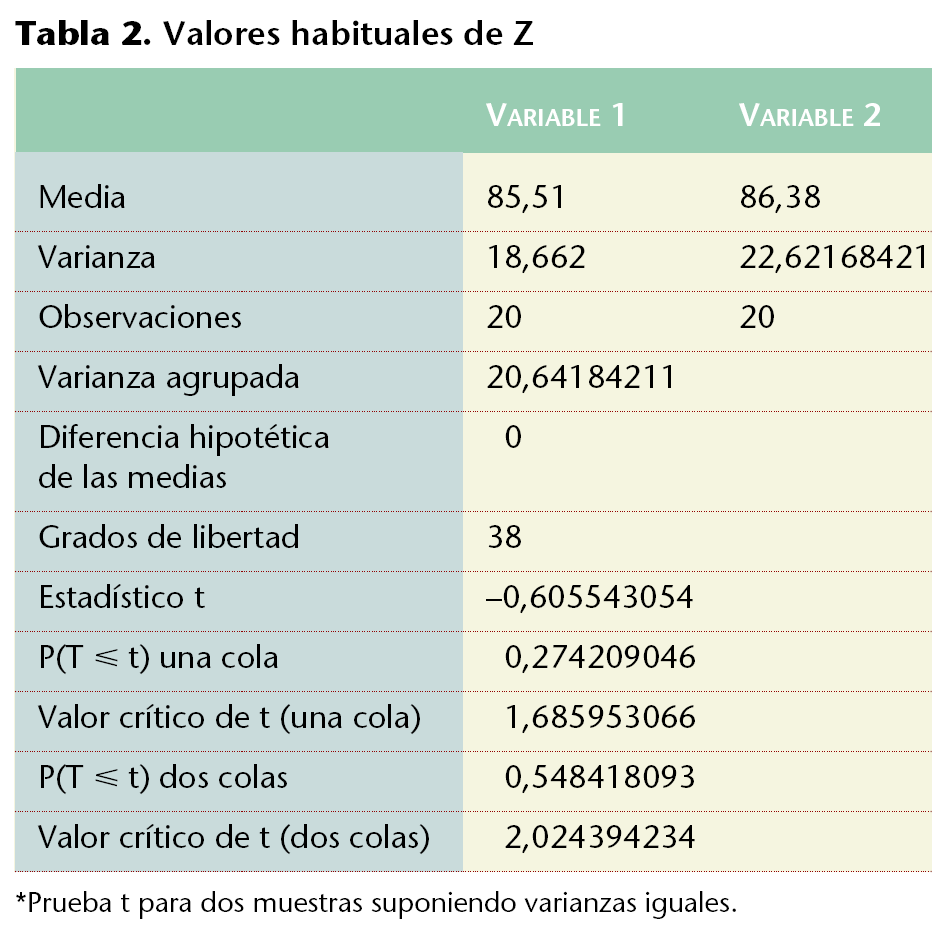
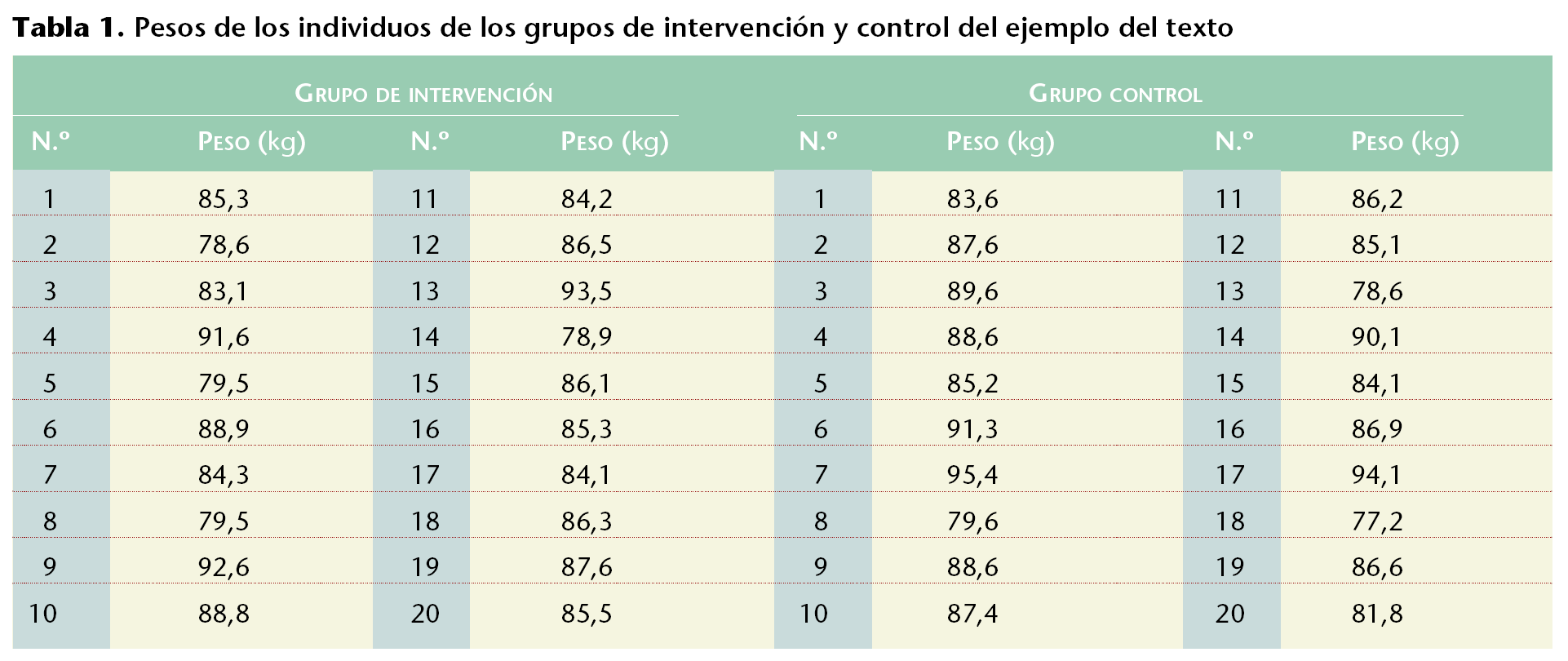
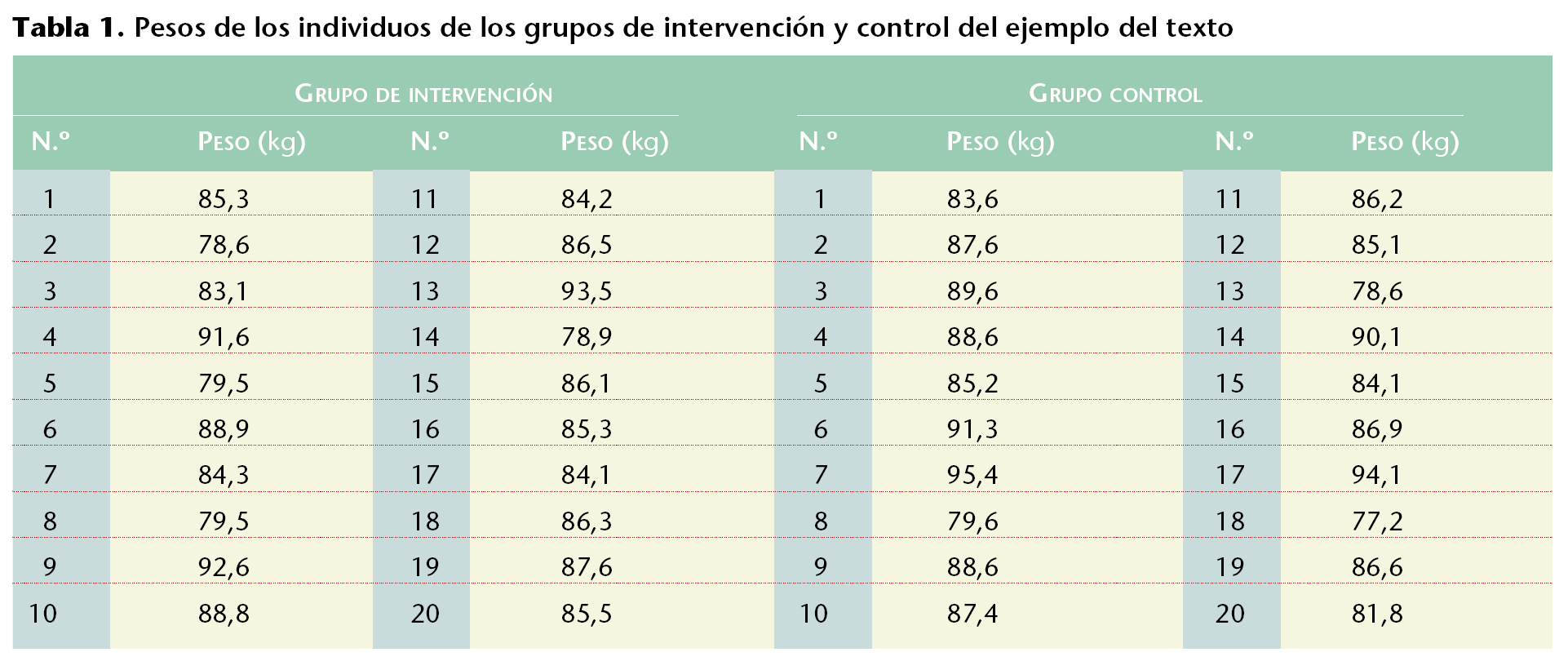
Si el grupo de control hubiera tenido los valores de pesos de la tabla 3, el resultado de Excel hubiera sido el ofrecido en la tabla 4, donde la p estimada de 2 colas es de 8,5190 * 10-11, lo que indica que la diferencia no puede ser explicada sólo por el azar, por lo que la diferencia es significativa y las muestras no son homogéneas.