








Reversible watermarking (RW) is the art of embedding secret information in the host image such that after extraction of hidden information, original image is also restored from the watermarked image. Prediction error expansion (PEE) is state of the art technique for RW. Performance of PEE methods depends on the predictor's ability to accurately estimate image pixels. In this paper, a novel Diamond-Mean (D-Mean) prediction mechanism is presented. The D-Mean predictor uses only D-4 neighbors of a pixel, i.e. pixels located at {east, west, north, south}. In the estimation process, apart from edge presence, its orientation and sensitivity is also taken into account. In experimental evaluations, the D-Mean predictor outperforms currently in use MED (median edge detector) and GAP (gradient adjusted predictor) predictors. For, standard test images of Lena, Airplane, Barbara and Baboon, an average improvement of 51.79 for mean squared PE and an average improvement of 0.4 for error-entropy than MED/GAP are observed. Payload vs imperceptibility comparison of the method shows promising results.
Internet is a highly convenient medium for transmitting and sharing of multimedia data. It rejuvenated businesses by attracting large number of customers. With the ease of access and increased business benefits, arises a greater challenge of ownership and authenticity of the media content. Watermarking of multimedia content is a very popular technique of coupling secret information with images and videos.
Image watermarking is the art of hiding ‘secret message’ in the image in such a way that it should not cause any visible distortion. It is one of the recent image protection methods, which provides security against illegal production and re-sharing of the copyright content. The process of hiding secret information is called as ‘watermark embedding’. When an image, also known as ‘cover-image’, undergoes embedding process it is called as ‘watermarked-image’. The main objective of watermarking is to make the watermarked-image alterations imperceptible to the image viewer, i.e. the quality of cover-image and watermarked-image should be visually identical. The amount of data that can be successfully embedded and retrieved in the cover-image is called as ‘payload’ of the embedding method. Increase in payload affects the imperceptibility negatively and vice versa.
Methods that can extract the watermark (hidden message) as well as completely retrieve the cover image from its watermarked-image are called as reversible watermarking (RW) methods (Caldelli, Filippini, & Becarelli, 2010). Recovery of the cover image is very important in medical imaging or in military applications where even a minute alteration/distortion is unacceptable. An MRI or CT scan image of a patient if not fully recovered might endanger the life of a patient by misleading the physician. Other applications of RW include remote sensing (Barni, Bartolini, Cappellini, Magli, & Olmo, 2001) and multimedia archive management (Park, 2014). Many reversible watermarking techniques has been proposed in the most recent literature (Kotvicha, Sanguansat, & Kasemsa, 2012; Shi & Xiao, 2013; Song, Li, Zhao, Hu, & Tu, 2015; Zhang, Qian, Feng, & Ren, 2014; Zhao & Feng, 2016).
Tian (2003) introduced difference expansion transform for RW which was followed by prediction-error expansion (PEE) method by Thodi and Rodríguez (2004, 2007) they introduced histogram-shifting (HS) which significantly reduced location map (LM) size. Since then, many variations of PEE based methods (Kamstra & Heijmans, 2005; Luo, Chen, Chen, Zeng, & Xiong, 2010; Peng, Li, & Yang, 2012; Sachnev, Kim, Nam, Suresh, & Shi, 2009; Tai, Yeh, & Chang, 2009; Wang, Li, & Yang, 2010) were developed. Performance of these methods heavily rely on the predictor's ability to accurately predict image pixels. In most of the methods researchers investigated different embedding mechanisms while not much work is being done in developing new predictors. MED (Weinberger, Seroussi, & Sapiro, 2000) and GAP (Wu & Memon, 1997) are mostly used predictors by these methods.
In this paper a novel predictor for reversible watermarking is proposed. The predictor accurately models the flat and edge regions in an image hence better prediction of pixels which leads to less distortion of watermarked image. Improved embedding of watermark in conjunction with histogram shifting and D-Mean predictor led to gain higher imperceptibility levels for a given payload.
The paper organization is as follows: In the next section relevant reversible image hiding methods are discussed. In Section 3, MED and GAP are reviewed and novel D-Mean predictor is presented. Reversible watermarking method based on the proposed predictor is discussed in Section 4. Experimental setup and results are provided in Section 5 and conclusions are drawn in Section 6.
2Related workFirst expansion based method was presented by Tian (2003) and it achieved moderate payload with good image quality. In this method, image is divided into pairs of pixels and each pair based on its mean and difference value undergoes 1 bit of data embedding. Let (x0, x1) be the values of a pair of pixels, then integer mean and difference are denoted as l=⌊(x0+x1)/2⌋ and h=x1−x0. To embed 1 bit watermark b∈{0, 1} in h, it is expanded to h′=2h+b and watermarked values (x0′,x1′) are obtained using Eq. (1). For an easy reference, notations used in the paper are summarized in Table 1:
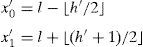
Notations.
| Symbol | Description |
|---|---|
| h | Difference of pixels |
| h′ | Expanded difference after embedding of data |
| e | Prediction error |
| E | Expanded prediction error |
| x | Original pixel |
| xˆ | Estimate/prediction of a pixel |
| x′ | Watermarked pixel |
| T | Embedding capacity threshold |
| TS | Edge sensitivity threshold used in D-Mean predictor |
| SPE | Entropy measured over PE of a predictor |
| I | Original Image |
| Θ1 and Θ2 | Two disjoint sets of an image |
| Ψ | Pixels which can be modified twice without producing overflow |
| Φ | Pixels which can be modified once and will lead to overflow upon 2nd modification |
| ϒ | Pixels which cannot be modified |
| bh | hard bit used for testing of overflow |
| Du | Watermark data to be embedded in the image |
| D | Payload which includes auxiliary information, LM and watermark data |
| Ai | Auxiliary information necessary for watermark extraction |
| Tv | Pixel selection threshold based on variance of the context |
| v(·) | Variance of a set of pixels |
| NLM | Length of location map |
| ⊙ | Concatenation operator |
Pairs which are not suitable for data embedding are listed in location map (LM). For successful extraction of hidden data and restoration of cover image pixels, LM is also stored in the watermarked-image alongside embedded bits as overhead information. Originally, image pixel values range from 0 to 255 for an 8 bits per pixel representation. Expanded pixels which lie outside the permissible range are marked as unexpandable pairs in LM. Size of LM hampers the embedding capacity (EC); therefore reduction in its size is very important, hence researchers are using lossless compression methods to reduce its size. Using Tian method, 1 bit can be embedded in each pair of pixels while 1 bit for each pair is also required in LM hence space for data embedding is created by lossless compression of LM.
Alattar (2004) extended the idea of a pair to k pixels cell. Each cell has been used to hide k−1 bits. For each cell one bit is required in LM, this helps decrease the size of LM to (1/k)th the image size. Unexpandable cells cannot be used for embedding due to problems of underflow or overflow (noted as overflow), so payload of the method is always less than (k−1)/k bpp (bits per pixel).
Location map is the bottleneck of reversible image hiding methods. Even compressed LM takes significant part of the payload. Thus, LM size determines the performance of a method. Later, authors investigated methods that generate small-size location map or no map at all. Lee, Yoo, and Kalker (2007) used block-based approach with integer-to-integer wavelet transform to hide data. An image of size X×Y is divided into blocks of size N×M. The method produces relatively small LM and better exploits redundancy present in the sub-bands of wavelet transformed coefficients, hence, outperforms Tian (2003) and Alattar (2004).
Image pixels are highly correlated with neighboring pixels. Thodi and Rodríguez (2004) used MED predictor to predict image pixels from their neighborhood pixels. The prediction error (PE) is used to hide watermark bits instead of difference between pairs of pixels. In prediction, more than one pixel of the neighborhood is used which results in smaller PE. PE denoted as e of a pixel x having prediction value xˆ, is computed using Eq. (2). In Thodi and Rodríguez (2007), HS was incorporated in error expansion. In this method e is expanded for data embedding and the expanded error E is computed using Eq. (3):
Watermarked pixel x′ is calculated using Eq. (4)In the decoder, E and e are computed using Eqs. (5) and (6) respectively:Embedded data bit b can be extracted using Eq. (7) and original pixel value is restored using Eq. (8):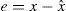
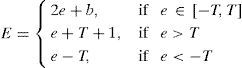
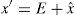
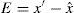
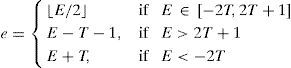
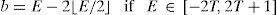
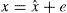
Kim, Sachnev, Shi, Nam, and Choo (2008) further used a simplified approach to reduce the size of LM and need for lossless compression was evaded. van der Veen, Bruekers, van Leest, and Cavin (2003) used companding technique for reversible watermarking of audio streams while van Leest, van der Veen, and Bruekers (2004) extended the same method for images. For data hiding Ni, Shi, Ansari, and Su (2006) used shifting of bins in histogram of image pixels. Yang, Schmucker, Funk, Busch, and Sun (2004) presented a generalized RW method for coefficients of integer discrete cosine transform. In another research Yang, Schmucker, Busch, Niu, and Sun (2005), they also used high frequency wavelet coefficients with histogram expansion. Luo et al. (2010) introduced an interpolation based RW method which has high fidelity but with relatively low capacity. Hong, Chen, Chang, and Shiu (2010) presented a high performance error expansion based RW method. Tsai, Hu, and Yeh (2009) compute the residual image from basic pixels and reference pixels in nonoverlapping blocks, high payload is achieved by multilevel embedding in residual image. Luo et al. (2010) used full context for interpolation of a pixel, interpolation error is expanded to embed data. Due to the fact that they have used 8 neighbors of a pixel context their results are significantly improved from methods that uses MED and GAP based prediction mechanism which use 3 and 7 pixels respectively.
Wang, Li, Yang, and Guo (2010) presented generalized version of the Tian's difference expansion algorithm. The difference is converted to extended integer transform and rather than using difference, mean of the block is computed and difference of the mean and pixel is used for embedding. It uses multiple embedding passes to achieve high EC. It had better imperceptibility performance than its predecessors. Hu, Lee, and Li (2009) proposed a major improvement in DE by incorporating MED and dual expansion. Dual expansion is carried out in two stages. In 1st stage the histogram bin is shifted to the right and in the 2nd stage the bin is slightly shifted back to the left, hence reducing/reversing the distortion caused by 1st stage embedding. The performance was further improved by introducing capacity control mechanism.
Peng et al. (2012) proposed a block based method. The image is first divided into non-overlapping blocks. Embedding capacity of each block is computed by using variance as the capacity control parameter. Variance is inversely proportional to the EC of a block. Location map for each block is computed and compressed using a lossless method. Watermark and LM are embedded into each block to generate watermarked image. This approach has better performance at higher payloads.
In most of the expansion based methods MED and GAP predictors are used. As these predictors were designed for lossless compression rather than data hiding, they cannot fully exploit existing correlations among image pixels for the purpose of watermarking.
3Diamond-Mean predictorIn reversible watermarking methods PE histogram is modeled by Laplacian distribution. This is because of the spatial redundancy in image pixels. To get higher peaks in the center of the PE histogram, high performance predictors are being used in the prediction process. MED (Weinberger et al., 2000) and GAP (Wu & Memon, 1997) are the advanced predictors used in JPEG-LS and Context-based Adaptive Lossless Image Coding (CALIC). In the proposed reversible watermarking method D-Mean (Diamond-Mean) predictor is used. Before presenting the D-Mean predictor MED and GAP are reviewed.
3.1Median edge detectorMED is one of the mostly used predictor in lossless compression and reversible watermarking. To calculate the prediction it uses forward context pixels. Pixel context is given in Fig. 1. Using MED, the estimate of a pixel xˆ can be calculated using Eq. (9):
The predictor selects xs incase a vertical edge is detected, xe incase of a horizontal edge and xs+xe−xse when no edge is detected. In Martucci (1990) they have denoted it as the median of the set {xs, xe, xs+xe−xse}. MED is being used by Thodi and Rodríguez (2007) and many other PE techniques. It efficiently detects the presence of an edge but major limitation is its inability to detect intensity of the edge.3.2Gradient adjusted predictor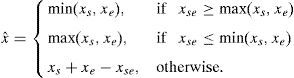

GAP is more complex than MED. The prediction context is extended to 7 pixels. It not only detects the existence of an edge but also the intensity (weak, normal, strong). The direction of edge is detected by comparing local gradients with empirical thresholds. It performs better than MED at the expense of mathematical complexity. Estimate xˆ of a pixel is calculated using Eq. (10):
where
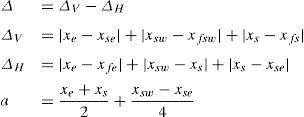
Both MED and GAP were originally designed for predictive coding in image/video compression. Due to limitations in coding for compression in the respective standards these predictors only use one side of a pixel context hence are unable to fully exploit the correlation between neighboring pixels.
3.3Proposed Diamond-Mean predictorA predictor that would better exploit correlation of pixels is presented. The proposed D-Mean (Diamond-Mean predictor) calculates the estimate xˆ=⌊α⌋, while α is calculated using Eq. (11):
where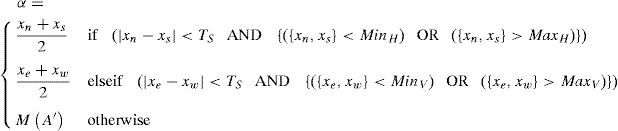
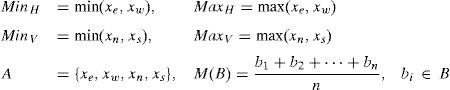
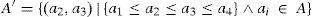
Set A consists of four neighbors of a pixel, i.e. {xe,xw,xn,xs} as defined in Fig. 1. A′ contains the 2nd and 3rd largest elements of A. M function computes the mean of a set while ⌊α⌋ returns floor of α, i.e. the largest integer less than α.
For each pixel, the predictor first checks if neighboring pixels (xn, xs) or (xe,xw) are close enough to be on the same edge, an edge sensitivity threshold TS is used for this purpose. For vertical edges, if both xn and xs are less than MinH (a dark edge on a bright background) or both are greater than MaxH (bright edge on a dark background) then there exist an edge which passes through xn and xs (a vertical edge). Horizontal edges are detected in the same manner and current pixel prediction is calculated. If there exist no definite edge, mean of 2nd and 3rd largest pixels from {xe,xw,xn,xs} is taken as prediction. Using this method the predicted value may not be an integer, which must be converted to an integer if it is to be used in RW, for that purpose floor of the predicted value is calculated. The PE histogram of MED, GAP and D-Mean predictors is compared in Fig. 2. Significant improvement is observed for all four standard images, i.e. Lena, Airplane, Barbara and Baboon. Surge in the histogram peaks at 0 and short tail of PE for D-Mean confirms the superior performance of the proposed D-Mean predictor over MED and GAP methods.

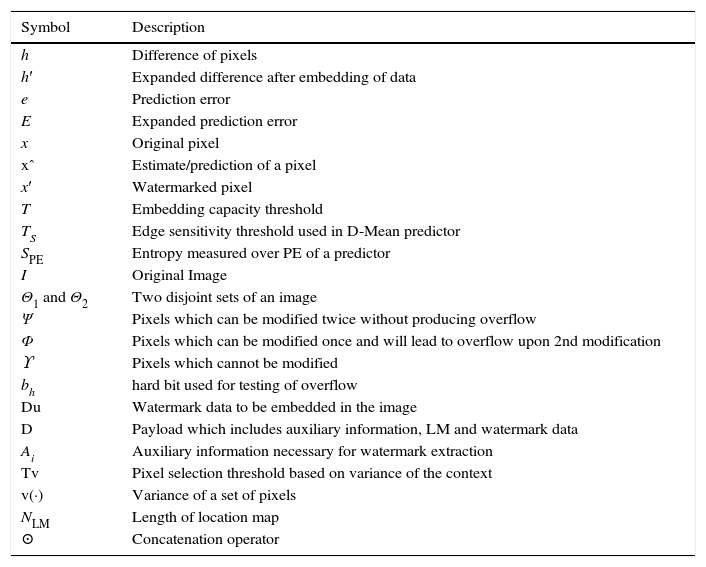
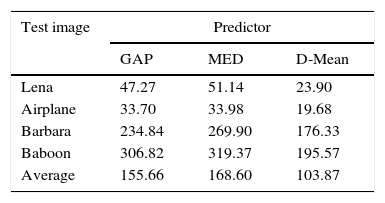
Quantitative measures of predictor's performance are mean squared prediction error (MSPE) and entropy of PE (SPE). Watermarking method's performance is inversely proportional to both the measures, i.e. smaller MSPE and entropy of PE (SPE) leads to better imperceptibility results. MSPE is computed using Eq. (12) and SPE using Eq. (13). Here, e is PE computed using Eq. (2), Ne is the length of error vector, and pr(e) is the probability of error, e. In Table 2, predictors are compared on the basis of MSPE. For all the test images D-Mean yields the least MSPE than MED and GAP. Entropy comparison of PE is provided in Table 3 and again D-Mean has outperformed other predictors. Overall, average performance of D-Mean is also better for both MSPE and SPE:
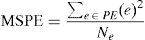
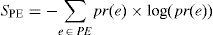
With D-Mean predictor two-stage image traversal mechanism is used. Pixels classification into 2 sets is provided in Fig. 3. Pixels of an image I having positions (i, j) are assigned to disjoint sets Θ1 and Θ2. As both sets are disjoint, pixels in Θ1 can be used in estimation of pixels in Θ2 and vice versa.
4Proposed method
Proposed watermarking method uses high performance D-Mean prediction mechanism. Pixel's PE is expanded to embed watermark bits. Some of the pixels that may result in overflow due to embedding are left unmodified in the watermarked image. Intelligent embedding is being used to only select pixels that have small PE which further improved imperceptibility of the proposed method. Illustration of the proposed method is provided in Fig. 4.

Given an image I of size M×N having pixels {(i, j)|1≤i≤M, 1≤j≤N} is processed in two stages. Θ1 pixels are processed first. Based on pixel's modifiability 3 sets of pixels are defined for Θ1, unambiguously modifiable (noted as Ψ), ambiguously modifiable (noted as Φ) and non-modifiable (noted as ϒ) pixels. Pixel's PE is calculated using Eq. (2) and tested by modification with hard bit (bh) using Eq. (3), modified pixel xt1 is calculated using Eq. (4). If xt1 satisfies (xt1<0∨255<xt1) it is assigned to ϒ otherwise xt1 is further checked for modification with bh in the same manner and modified pixel xt2 is calculated. If xt2 satisfies (xt2<0∨255<xt2) it is assigned to Φ, otherwise it is assigned to Ψ. In Eq. (3), bh is being used for overflow checking in place of b and is defined as:
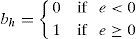
LM is maintained for pixels that may result in overflow due to embedding. Here an approach similar to Kim et al. (2008), is being used in recording of LM. Pixels in Ψ can be unambiguously interpreted in the decoder, hence these pixels do not require the use of LM. Pixels of the set Φ are only modified with hard bit and pixels of the set ϒ are not modified at all. In LM Φ and ϒ pixels are noted 0 and 1 respectively. In our case LM is a 1D binary string and its length is defined as |Φ|+|ϒ|, here |·| is a cardinal number of the set.
Payload of the proposed method is controlled by EC parameter T as used in Eq. (3). Due to iterative nature of existing RW algorithms, selection of T is a computationally expensive task because they had to compress LM for each value of T. We are using a simple methodology to record LM which significantly reduces its size hence compression is not required. A simple procedure to compute T is followed.
Let Nc be the length of data Du to be embedded in the image. In the proposed two stage processing, Nc1 and Nc2 are the sizes of data embedded in stage 1 and 2 respectively. Nc1 and Nc2 are computed as follows:
Auxiliary information Ai is required for successful extraction of watermark in the decoder. Ai is also embedded as part of the payload in the image. |Ai| is 68 bits, 8 for EC threshold T, 24 for pixel selection threshold Tv and 18 for LM length and 18 for last modified pixel position according to ⌈log2(M×N)⌉ for 512×512 size image. For each stage Θ1 and Θ2 three sets ϒ(T), Φ(T) and Ψ(T) can be defined for T∈{1, 2, …, 255}. Data embedding in each stage is possible subject to Eq.(16). If T which satisfies Eq.(16) then it is not possible to hide data of size Nci in each stage.Smallest T for which, |Ψ(T)|≥D is selected as EC threshold.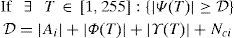
Maximum data that can be embedded in a single stage is |Ψ|. Let Nci be the length of data desired to be embedded in each stage. If D<|Ψ| then a subset Ψs of pixels can be selected from Ψ for embedding. Error due to embedding of PEE based methods is directly proportional to the magnitude of PE hence Ψs must contain pixels having small PE. Here a pixel selection mechanism is defined based on variance of the neighboring pixels. Let Ψs be defined as:
Here xN for a pixel x at location (i, j) is defined as a set, i.e. {(i−1, j), (i, j−1), (i, j+1), (i+1, j)} also mentioned as xn,xw,xe and xs of a pixel context in Fig. 1, while υ(xN) is defined as:Tv is a threshold for selection of pixels having small PE. In this way, proposed method tends to select the pixels having small error and hence better visual quality of the watermarked image is obtained.4.1Watermark embedding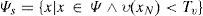
In this sub-section watermark embedding procedure is listed. Step by step description of the proposed method is followed. Embedding data Du is divided into 2 parts, Du1 and Du2 using Eq. (15). Data streams Du1, Du2 contains Du{1⋯Nc1} and Du{Nc1+1⋯Nc} respectively. Du1 is embedded in pixels from Θ1 while Θ2 will be embedded with Du2. For each set, Θ1 and Θ2, repeat the following steps:
- Step 1:
Select the EC threshold T, which satisfies Eq. (16).
- Step 2:
Compute υ for all pixels using Eq. (18) and arrange pixels in increasing magnitude with respect to υ.
- Step 3:
Skip the initial 68 pixels. Among the remaining, using Eq. (17) select a subset Ψs from Ψ.
- Step 4:
All pixels of the set, Φ will be modified with hard-bit using Eq. (14). Pixels of the set, ϒ will not be modified but noted in LM. In LM Φ and ϒ pixels are noted as ‘0’ and ‘1’ respectively. Size of LM, NLM will be |Φ(T)|+|ϒ(T)|
- Step 5:
Collect LSB of initial 68 pixels and construct the payload as Dup=LSB⊙LM⊙Dui. Where ⊙ is a concatenation operator.
- Step 6:
Each pixel of the set Ψs is used to embed 1 data bit from Dup using Eq. (4). Estimate of the pixel, xˆ is computed using proposed D-Mean predictor.
- Step 7:
Auxiliary information Ai, consists of 68 bits and contains, T, Tv, NLM and position of the last modified pixel. Replace LSBs of the initial 68 pixels with Ai.
In the decoder watermarked image is processed in the reverse order. First, pixels of stage-II, Θ2 are decoded and restored. Then, Θ1 pixels are processed. Step-by-step procedure of decoding is described as:
- Step 1:
Extract LSBs of the initial 68 pixels and compute the parameters of T, Tv, and NLM and location of the last modified pixel.
- Step 2:
As done in the encoder, compute υ for all pixels using Eq. (18) and arrange pixels in the increasing magnitude with respect to υ.
- Step 3:
Make a set Ψe of pixels having υ
- Step 4:
Check each pixel of the set Ψe for expansion with hard bit, using Eq. (3) and Eq. (4). This step is performed until we reach the last modified pixel of the set.
- a.
If the pixel results in overflow, check LM, it belongs to one of the sets, Φ or ϒ. If corresponding bit in the LM is 0, it belongs to the set, Φ. The pixel is restored using the Eqs. (5) and (8). The bit stored in the current pixel is discarded and is not recorded in the data.
- b.
If the pixel did not resulted in overflow then stored data bit is extracted and the pixel is restored. The data bit from the pixel is extracted using Eq. (5) and (7) and recorded in the output data. While pixel restoration is carried out using Eq. (8).
- a.
- Step 5:
Restore the LSBs of initial 68 pixels from the extracted data.
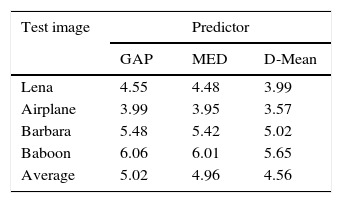
The method is assessed by comparing with Hu et al. (2009), Luo et al. (2010), Wang, Li, Yang, and Guo (2010) and one of the recent works by Peng et al. (2012). Results are compiled over the standard grayscale images of Lena, Airplane, Barbara and Baboon of size 512×512. The images are shown in the Fig. 5. The imperceptibility results are given in Fig. 6. The superior performance of the proposed method can be observed over all the test images. Improvement in results is primarily due to the use of high performance D-Mean predictor in the prediction mechanism. Maximum payload that can be embedded in a single pass of the proposed method is at most 1bpp. Hence, for large payload size, the method should be applied iteratively.

, Luo et al. (2010), Wang, Li, Yang, and Guo (2010) and Peng et al. (2012) over standard images.")
Performance comparison between proposed method and that of Hu et al. (2009), Luo et al. (2010), Wang, Li, Yang, and Guo (2010) and Peng et al. (2012) over standard images.
Selection of appropriate value for Edge sensitivity threshold TS, is important for predictor performance. In this work the TS is empirically determined and a value of 5 is used. It may be observed that the EC threshold controls the dual behavior of the predictor. For smaller values of TS the predictor will act like median of four pixels, while large value of the threshold will make the predictor similar to mean predictor. An image, I after watermark embedding phase is noted as, I′. Imperceptibility test of the methods is carried out based on PSNR for a specific bpp (bits per pixel). Higher PSNR is always desired. It can be computed using Eq. (19). Comparison based on PSNR measure of watermarking methods is provided in Fig. 6. Imperceptibility test for a specific bpp of 0.5 is provided in Table 4. An average of 2.14 (dB) improvement in PSNR can be observed in comparison to Peng et al. (2012):
MAXf for an 8 bit grayscale image is 255.6Conclusion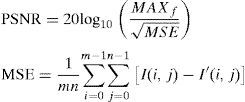
In this paper, a novel D-Mean predictor is proposed for PEE based reversible watermarking methods. D-Mean is state-of-art predictor which outperformed MED and GAP. D-Mean better models the presence/absence of an edge and uses 4 pixels around a pixel context which led to reduction in prediction-error. The method is simple and can be easily incorporated in the existing systems. Due to reduced overflow situation, location map shrinks to smaller sizes. The advantage of using D-Mean proved useful and results are improved for PEE based method. Future researchers may like to devise a scheme to auto-tune the parameters used in the D-Mean predictor and watermark embedding routine.
Conflict of interestThe authors have no conflicts of interest to declare.
First author would like to thank Higher Education Commission, Pakistan for funding a PhD fellowship under indigenous scheme through the grant no. 074-0941-PS4-070.
Peer Review under the responsibility of Universidad Nacional Autónoma de México.