


Este trabajo transforma la base de datos mundial del Climate Research Unit de la Universidad de East Anglia (http://www.cru.uea.ac.uk/), conocida como CRU TS 2.1, en datos regionales para España, tanto a nivel provincial como de comunidad autónoma.
Dicha base de datos, cuyo formato original es de tipo grid, no se ajusta a las necesidades de los historiadores e investigadores sociales y ello por dos motivos. Por una parte, estos estudiosos no son familiares, todavía, con las nuevas técnicas de los sistemas de información geográfica (SIG) necesarias para la manipulación de estas estructuras de datos. Por otra parte, y más importante, los datos disponibles en este formato no pueden ser combinados de forma adecuada con los que estos investigadores normalmente disponen.
De esta forma, mediante esta transformación, no solo es posible comparar estos datos con los disponibles de estaciones meteorológicas españolas y examinar así su consistencia, sino que es factible integrar dicha información con estadísticas demográficas y socioeconómicas, que típicamente solo están disponibles en formatos dependientes de la estructura política y administrativa de un país.
Our work translates the global data base of the University of East Anglia Climate Research Unit (http://www.cru.uea.ac.uk/), known as CRU TS 2.1, into regional data for Spain at two levels: autonomous communities (Comunidades Autónomas, NUTS 2) and provinces (NUTS 3).
The original data base, which is in grid form, is not suitable for social scientists and historians for two reasons. On the one hand, they are not yet familiar with the new Geographical Information Systems (GIS) technology which is necessary for handling this type of data structure. On the other hand, and more importantly, GIS data in grid form cannot be directly combined with the data usually available to these researchers.
This transformation makes it possible to perform two tasks. We can compare this data base directly with statistics from meteorological stations and examine the consistency between data sources. In addition, we can combine the transformed data base with demographic and socioeconomic data normally available only in formats that depend on a country's administrative and political structure.
«La comparación de las series españolas con las del entorno más próximo o con las de todo el mundo es ahora posible y necesaria». Albert Carreras (2005, Estadísticas Históricas de España, p. 46)
El reciente interés por el cambio climático, y los retos que el mismo plantea para la sociedad global en un futuro más o menos cercano ha hecho crecer las publicaciones relacionadas este tema, desde una perspectiva realmente interdisciplinar, de forma exponencial en los últimos años (Stanhill, 2001). Sin embargo, la idea del efecto invernadero y la posible influencia del ser humano sobre dicho efecto no son nuevas y pueden rastrearse, al menos, hasta el siglo xix (Tyndall, 1863; Arrhenius, 1896).
Este interés ha ido acompañado, al igual que en otras disciplinas, por un énfasis en la recopilación y armonización de estadísticas históricas climáticas que permitieran analizar el largo plazo desde una perspectiva global2. La necesidad de armonización fue claramente puesta de manifiesto a partir de los trabajos del Inter-governmental Panel on Climate Change (IPCC, http://www.ipcc.ch/; McCarthy et al., 2001). Para responder a esta necesidad diversos organismos internacionales producen y armonizan, desde hace algún tiempo, este tipo de información. Entre ellos, es de destacar el Climate Research Unit (CRU) de la Universidad de East Anglia (http://www.cru.uea.ac.uk/), el Tyndall Centre for Climate Change Research, formado por un consorcio de universidades del Reino Unido lideradas por la Universidad de East Anglia (http://www.tyndall.ac.uk/), el Goddard Institute for Space Studies de la NASA (http://www.nasa.gov/) en la Universidad de Columbia (http://www.giss.nasa.gov/), el National Climatic Data Center (NCDC) de la National Oceanic and Atmosphere Administration (NOAA, http://www.ncdc.noaa.gov/) o el Center for Climatic Research de la Universidad de Delaware (http://climate.geog.udel.edu/∼climate/index.shtml).
En España la información histórica sobre datos climáticos está excelentemente recopilada en Carreras (2005) y la bibliografía allí recogida. Aunque ajustados a la fecha de publicación, destacan también los trabajos de Huerta López (1984) y Barriendos Vallvé (1995). Este tipo de recopilaciones recogen datos diversos de las distintas estaciones meteorológicas disponibles en España desde alrededor de mediados del siglo xix; se trata por tanto de información bruta, para ciudades o puntos concretos y cuya disponibilidad espacial es diversa y, normalmente, creciente en el tiempo.
A pesar de que algunos autores acometieron laboriosas tareas de homogeneización (Almarza Mata et al., 1996; Esteban-Parra et al., 1998; Staudt et al., 2007), este tipo de datos directos, procedentes de la observación en puntos aislados y sin una regularidad espacial clara constituía prácticamente la única fuente de información meteorológica antes de la recogida de datos mediante satélite (teledetección). Ya sea en esta forma, o mediante la agregación a promedios anuales y/o espaciales,3 esta ha sido la fuente de información básica utilizada por historiadores económicos en su integración de datos climáticos con datos socioeconómicos y demográficos (Dobado González, 2004, 2006; Pons Novell y Tirado Fabregat, 2008; Ayuda et al., 2010).
Sin embargo, las bases de datos de carácter global presentan un formato muy diferente y difícilmente compatible con la estructura de datos a la que están acostumbrados historiadores, geógrafos, sociólogos y economistas, donde los límites administrativos y políticos determinan la unidad de recogida o presentación de la información. Los climatólogos tienden a favorecer los dominios de recogida y organización de la información según zonas climáticas coherentes, por ejemplo, cuencas hidrográficas; mientras que los investigadores medioambientales, que trabajan normalmente con modelos de simulación de todo el globo terráqueo requieren la información climática en formato de rejilla cartográfica (grid), susceptible de ser tratada mediante los modernos sistemas de información geográfica (SIG). En este caso, dividimos el ámbito espacial objeto de estudio en celdas delimitadas por coordenadas geográficas, y a cada una de ellas asignamos un valor de la variable en cuestión. Este es, hoy día, el formato estándar para los datos climatológicos de carácter global.
Así pues, cuando la información climática debe ser combinada con estadísticas socioeconómicas y demográficas es necesario un cambio de coordenadas de forma que, o los datos climáticos son transformados a dominios espaciales de carácter político-administrativo, o los datos demográficos y económicos son transformados a una grid4.
Este trabajo convierte los datos de la base de datos climática global de series temporales en formato grid de Mitchell y Jones (2005), del Climate Research Unit, conocida como CRU TS 2.1, a un formato estándar en términos de las estadísticas que están habituados a manejar los investigadores sociales: datos regionales (provincias y comunidades autónomas), en formato de serie temporal, o si se prefiere un panel de datos que se extiende a 9 variables climáticas más allá de un siglo y con una periodicidad mensual.
El objetivo es doble. Por una parte, se facilita la comparación de este tipo de estadísticas con las habitualmente disponibles para España (Carreras, 2005). Por otra parte, se dispone de una base de datos estructurada y regular, que puede ser incorporada, con las debidas cautelas, a los modelos históricos de desarrollo regional o localización de la población.
El trabajo se estructura de la siguiente forma. La sección siguiente describe, de forma sucinta, la base de datos original. Esto incluye tanto las variables, como el formato de los datos de partida, su resolución y fiabilidad, así como la forma de medir esta última a partir de los propios datos. La metodología solo se describe someramente, remitiendo al lector a las fuentes bibliográficas originales. La sección tercera describe el proceso de transformación de los datos originales en datos provinciales y de comunidades autónomas. Y finalmente se hacen algunas comparaciones con datos españoles. Un breve apéndice describe la disponibilidad de los datos y su formato de distribución.
2La base de datos CRU TS 2.1.2.1AntecedentesEl origen de las bases de datos del Climate Research Unit (CRU) de la Universidad de East Anglia lo constituyen una serie de conjuntos de datos globales sobre estaciones meteorológicas que el CRU ha ido compilando y actualizando durante los últimos 30 años. Sobre la base de esta información, New et al. (1999) construyeron una grid climatológica de 0,5° de resolución, 0,5° latitud×0,5° longitud de tamaño de celda (aproximadamente 56 km×56 km en el ecuador), de medias mensuales de determinadas variables para el periodo 1961–1990. Una grid climatológica representa el clima promedio para un periodo de tiempo largo y permite la comparación espacial de características medioambientales relacionadas con el clima, pero no recoge la variación temporal. Esta grid es conocida como CRU CL 1.05.
A partir de este trabajo inicial, New et al. (2000) construyeron, con la misma resolución espacial, una grid de series temporales mensuales para determinadas variables climáticas y el periodo 1901–1996. Para ello utilizaron un método estándar en la interpolación de series climáticas, el «método de las anomalías» (Jones, 1994), que trata de maximizar la información disponible sobre estaciones meteorológicas en el tiempo y en el espacio. A grandes rasgos en esta técnica, las series temporales de estaciones se expresan en términos de desviaciones relativas a un periodo base de referencia: 1961–1990, se interpolan estas desviaciones sobre una grid, en lugar de interpolar los valores absolutos de las variables, y se combinan finalmente con una grid de «normales» para el periodo base. En el contexto de las estadísticas económicas el proceso es similar a, una vez estimada una tendencia, sobreponer la estimación del ciclo para llegar al valor interpolado final. Como referencia se utilizó la CRU CL 1.0 de New et al. (1999). Esta grid inicial es conocida como CRU TS 1.0 y fue actualizada posteriormente hasta 1998 por los mismos autores (CRU TS 1.1).
El proceso de cálculo efectúa las correcciones necesarias por la altitud del terreno, de hecho, la base de datos proporciona un modelo digital de elevaciones con la misma resolución que para las variables climáticas, así como por la distancia desde el centro de la celda hasta el lugar donde se encuentran las estaciones cercanas que contribuyen al valor de la celda en cuestión. Los ajustes por distancia se efectúan a través de una ponderación determinada mediante una función de deterioro de la correlación (correlation decay function; Jones et al., 1997). Por su parte, la distancia que delimita el umbral que define la inclusión o exclusión de estaciones en el cálculo se determina empíricamente, como aquella a partir de la cual la correlación inter-estaciones, adecuadamente ponderada según zonas, deja de ser significativa a un 95% de confianza para un número dado de observaciones (correlation decay distance, CDD; Dai et al., 1997). Aunque la función que determina los pesos asignados a las estaciones es la misma para todas las variables, las distancias que definen la inclusión o no de las mismas depende de la variable concreta (New et al., 2000).
Mitchell et al. (2004) revisaron estas grids y las actualizaron hasta el año 2000 (CRU TS 2.0)6. Posteriormente, Mitchell y Jones (2005) emprendieron una tarea de revisión y ampliación de las bases de datos de partida de las estaciones, desarrollaron una serie de mejoras metodológicas en los procesos de interpolación, generación de series de referencia utilizando información de estaciones vecinas, ampliación de variables y extensión del periodo temporal hasta 2002, pero mantuvieron lo sustancial del método: interpolación de las anomalías sobre un periodo base de referencia, que se sigue manteniendo en 1961 – 1990. De esta forma generaron la base de datos conocida como CRU TS 2.1, y que es el objeto de este trabajo. La metodología de las diferentes versiones indica claramente que no se deben mezclar las diferentes grids7.
2.2Variables consideradasLa CRU TS 2.1 comprende 1.224 observaciones mensuales de 9 variables climáticas para el periodo 1901–2002, cubre toda la tierra, con excepción de la Antártica, y ofrece una resolución espacial de 0,5°. Las 9 variables climáticas y sus unidades de medida son las siguientes:
- 1.
PRE: precipitación (mm, equivalente a litros/m2)
- 2.
TMP: temperatura media cerca de la superficie (grados Celsius, C°)
- 3.
DTR: rango de temperatura diurna cerca de la superficie (C°)
- 4.
WET: frecuencia de días húmedos (días)
- 5.
VAP: presión de vapor (hecto-Pascales, hPa)
- 6.
CLD: cobertura de nubes (%)
- 7.
FRS: frecuencia de días con helada (días)
- 8.
TMN: temperatura mínima cerca de la superficie (C°)
- 9.
TMX: temperatura máxima cerca de la superficie (C°)
A efectos de utilización de esta información es necesario dividir las variables en 3 grupos: (i) variables primarias, (ii) variables secundarias y (iii) variables derivadas.
2.2.1Variables primariasComprenden la precipitación, la temperatura media y el rango de temperatura diurna.
Para estas variables se dispone de suficiente información sobre las estaciones de base como para obtener las grids directamente a partir de las anomalías de dichas estaciones. Por tanto, los datos de las variables primarias se basan solamente en observaciones directas de estaciones.
2.2.2Variables secundariasComprenden la presión de vapor, la cobertura de nubes y las frecuencias de días húmedos y con heladas.
Para estas variables la información directa de las estaciones es menor que en el caso anterior, sobre todo a principios del siglo xx. Por este motivo la información sobre estaciones es aumentada mediante relaciones empíricas o conceptuales a partir de las variables primarias. Estas relaciones se utilizan para la construcción de grids sintéticas de anomalías mensuales que son las utilizadas en el proceso final. New et al. (2000) proporcionan información detallada sobre dichas relaciones.
2.2.3Variables derivadasComprenden la temperatura máxima y mínima.
Estas variables se obtienen directamente de las variables primarias temperatura media y el rango de temperatura diurna8.
A efectos prácticos, las variables primarias son siempre más fiables que el resto, ya que puede considerarse que proceden de la observación directa, mientras que las variables secundarias deben ser utilizadas con mayor cautela, aunque sobre este tema volveremos más adelante.
2.3Utilización de la base de datosEl propósito principal de la base de datos es la de proporcionar a los analistas medioambientales uno de los inputs necesarios para sus modelos de simulación. Esta finalidad ha sido determinante en ciertas opciones metodológicas y deben ser tenidas en cuenta por el usuario, ya que condicionan el propio uso de la base de datos en un contexto de series temporales. Los elaboradores de la información avisan claramente de estas limitaciones a los potenciales usuarios, http://www.cru.uea.ac.uk/∼timm/grid/ts-advice.html, y que por su relevancia comentamos brevemente.
Una de las principales cuestiones que se plantea es hasta qué punto es legítimo utilizar esta base de datos para examinar el argumento sobre el cambio climático. En este contexto hay dos cuestiones puntuales diferentes:
- 1.
¿Es legítima la utilización de la CRU TS 2.1 para la «detección del cambio climático antropo-génico»?9
La respuesta es claramente no. La información de base incluye estaciones urbanas con un cierto sesgo hacia temperaturas más cálidas. Para ser capaces de detectar la influencia de la actividad humana en el clima (en un sentido causal) es necesario eliminar todas las influencias del desarrollo urbano y de los cambios en el uso del suelo en los datos de partida de las estaciones meteorológicas.
Es importante observar que esta limitación se aplica a la práctica totalidad de los datos disponibles sobre variables climáticas y, en consecuencia, muchos de los trabajos que analizan la existencia de cambio climático en España no analizan el cambio climático antropo-génico, sino, en el mejor de los casos, el cambio climático regional (Sanz Donaire, 2008).
- 2.
¿Es legítima la utilización de la CRU TS 2.1 para medir el cambio climático regional?
La respuesta a esta pregunta depende de la homogeneidad y calidad de los datos de partida para la región en cuestión. La CRU TS 2.1 no proporciona una representación homogénea del cambio climático en todas y cada una de las celdas. Esto es consecuencia tanto de la información disponible como del propio diseño. La CRU TS 2.1 puede considerarse como la mejor estimación del patrón espacial del clima en cada momento de tiempo, al mismo tiempo que es completa en las dimensiones espacial y temporal.
En este sentido, hay dos características relevantes de la CRU TS 2.1 que es necesario conocer:
- (i)
Las grids se basan en los datos de las estaciones sin depurar. En las regiones y los meses para los que no se dispone de información directa, es decir, no hay ninguna estación dentro del radio de CDD, las anomalías se relajan hacia el cero, y en consecuencia el valor final de la variable en cuestión se relaja hacia el promedio mensual del periodo 1961–1990, que es el que se toma como referencia10. Esta característica se basa en el supuesto de que, en ausencia de información temporal específica disponible para un punto concreto, la mejor estimación en ese momento del tiempo es la media de largo plazo, y se la conoce con el nombre de «relajación hacia la climatología». En el contexto de las estadísticas económicas es similar a, una vez estimada una tendencia, sesgar los valores de las interpolaciones hacia dicha tendencia cuando no dispongamos de información adicional, lo que podríamos denominar «relajación hacia la tendencia». Resulta obvio que esta puede ser una limitación para un análisis de series temporales, donde la variabilidad a lo largo del tiempo es crucial11, de la misma forma que la «relajación hacia la tendencia» puede ser una limitación para el análisis del ciclo económico.
- (ii)
Cada grid mensual se basa en una interpolación de los datos de las estaciones disponibles en ese momento del tiempo. De un mes a otro la red de estaciones disponibles puede variar. Por tanto, los cambios a lo largo del tiempo de los valores a nivel de celda individual se deberán no solo a cambios genuinos en el clima, sino también a fluctuaciones en la red de estaciones disponibles. La interpolación de anomalías, en lugar de valores absolutos, tiende a minimizar estas fluctuaciones, que sin embargo no pueden ser eliminadas totalmente.
Para ser capaces de evaluar las posibilidades de la CRU TS 2.1 en términos de un análisis de series temporales, la Climate Research Unit hace pública, junto con las grids de las variables climáticas, unas grids con la información del número de estaciones que han contribuido al valor de la celda en cuestión.12 La CRU no hace pública la información directa de las estaciones por cuestiones de confidencialidad.
La conclusión de esta reflexión es que a nivel regional los datos serán más fiables cuanto mayor sea el nivel de agregación espacial que consideremos, pero aún así la cantidad de información detrás de los datos debe ser examinada. Para áreas pequeñas es posible que sea más conveniente el examen directo de las observaciones de las estaciones meteorológicas, en lugar de las de los datos globales procedentes de grids. En España disponemos de registros de estaciones desde mediados del siglo xix (Carreras, 2005), pero aún así, la utilización de los datos de estaciones en análisis de series temporales está sujeto a dos problemas principales: (i) dichos datos proporcionan una indicación del fenómeno de interés en un punto concreto del espacio; como se relaciona lo observado en ese punto con un valor promedio para un área dada no es una cuestión trivial, y (ii) los datos de series temporales derivados de observaciones de estaciones no son necesariamente precisos ni homogéneos en el tiempo. Existe una abundante literatura al respecto (Peterson et al., 1998), y algunos autores españoles se han ocupado de estas cuestiones de homogeneización para las precipitaciones y la temperatura (Esteban-Parra et al., 1998; Staudt et al., 2007).
Aunque es cierto que este tipo de cuestiones metodológicas sobre la homogeneidad de los datos de estaciones no ha recibido en ocasiones la atención que se merece, la recopilación para España de Almarza Mata et al. (1996) muestra lo determinante que puede resultar un tratamiento adecuado de la información de partida para la selección de series básicas o de referencia.
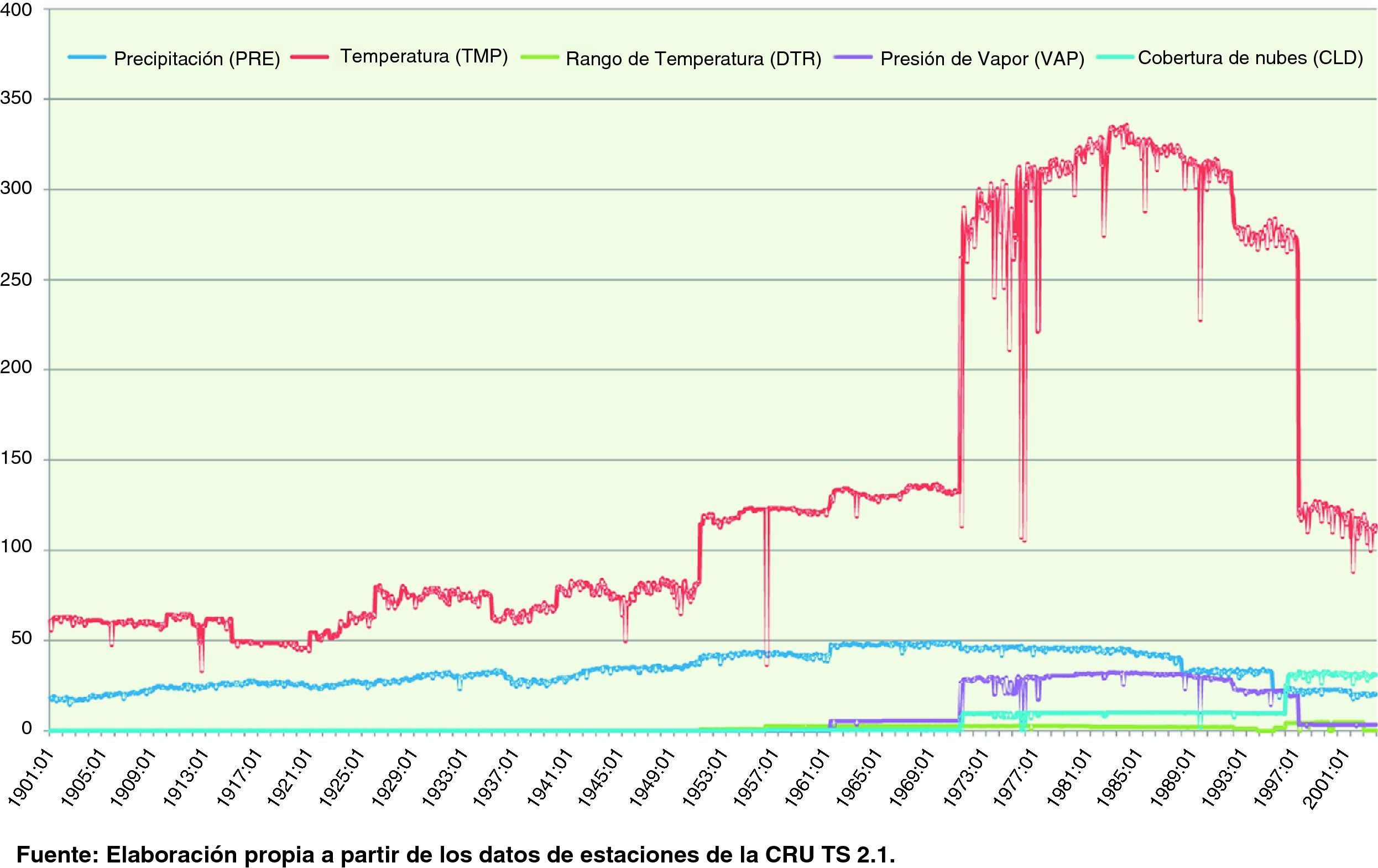
En el caso español, un examen directo de las 285 celdas correspondientes a nuestro territorio indicó que la información de partida es siempre suficiente a priori para las variables precipitación y temperatura media, si bien en el caso del archipiélago canario, dada su localización geográfica, la información es notablemente inferior a la del resto de España. Además, el número de estaciones que hay detrás de los valores finales en las celdas es siempre mayor en el caso de la temperatura media que en el caso de la precipitación. Por el contrario, para el resto de variables, incluida el rango de temperatura diurna que es una de las variables primarias, existen muchos valores de celdas particulares que proceden de la interpolación, especialmente en la primea mitad del siglo xx. En algunos casos, un simple gráfico de series temporales refleja claramente la «relajación hacia la climatología» que hemos mencionado anteriormente y hace dudar de la utilidad de esta información para un análisis de series temporales. La interpolación es especialmente evidente en el caso de la variable frecuencia de días húmedos, donde no parece que exista información directa para España en todo el periodo considerado.
Estas afirmaciones son ilustradas de forma visual en la figura 1, que muestra el promedio del número de observaciones de estaciones meteorológicas por celda para el conjunto nacional, es decir, para las 285 celdas mencionadas.

Tomados en su conjunto, la información de partida es razonable en todo el periodo para las variables precipitación y temperatura media, que son además las más frecuentemente utilizadas en los trabajos de carácter histórico. Para el resto de variables la figura 1 indica que los números que se ofrecen en la base de datos deben ser manejados con mayor precaución en un contexto de series temporales, especialmente para ámbitos geográficos pequeños. Como es lógico, la información de estaciones subyacentes tiende a crecer en el tiempo, con un pico en el entorno de mediados de los 80, ya que en los años recientes se han desarrollado otros métodos de observación climatológica.
3Construcción de observaciones climáticas regionalesEl formato original de la base de datos CRU TS 2.1, disponible en la web del CRU (http://www.cru.uea.ac.uk/cru/data/hrg/), está en formato ASCII delimitado por comas representando una grid regular latitud-longitud, y su manejo es muy laborioso13. Por esta razón, el Consortium for Spatial Information (CGIAR-CSI), del Consultative Group on International Agricultural Research (CGIAR), reformateó los datos originales en un formato manejable mediante software estándar de SIG, en concreto la base CRU TS 2.1 se transformó a una grid en formato ArcInfo de ESRITM (http://www.esri.com/), para su manejo en ArcView 3.x, ArcGIS 8/9 o ArcInfo 8/9. Esta grid regular, cuya resolución espacial es de 0,5° y está en el sistema de referencia geodésico WGS84 con coordenadas geográficas, contiene un valor identificativo único para cada celda de la superficie terrestre,14 lo que permite su unión y/o relación, mediante este código, con las tablas de datos o de estaciones correspondientes a las variables climáticas. Es esta grid, obtenida de la web del CGIAR-CSI, la que constituye el punto de partida de los datos utilizados en este trabajo.
La conversión de estos datos en estadísticas regionales para España sigue un proceso similar al utilizado por Mitchell et al. (2002) para la elaboración de las estadísticas de países o áreas geográficas coherentes desde un punto de vista climático15, aunque existen algunas diferencias. Estos autores asignan cada celda de la grid a un único país a partir de una inspección visual16, y calculan el valor del país en cuestión como una media ponderada de los valores de las celdas que pertenecen a dicho país. El peso de cada celda es el coseno de la latitud, puesto que la superficie de las celdas disminuye al incrementarse la latitud. Un procedimiento similar es utilizado por Dell et al. (2008) a partir de los datos de Matsuura y Willmott (2007), si bien estos autores utilizan software de SIG y ponderaciones a partir de una grid de población, en lugar de ponderaciones por área, para el cálculo de estos estadísticos zonales.
Nuestra aproximación también utiliza ponderaciones por superficie, si bien, dado que el tamaño de las provincias no es excesivo en relación al de las celdas, no utilizamos el software de SIG para el cálculo directo de los estadísticos zonales, sino para determinar que parte de la superficie provincial pertenece a cada una de las celdas de la grid, siendo esta superficie la ponderación en la obtención de los valores provinciales. En la latitud 40° las celdas de la grid no son cuadradas, y su superficie se ve reducida en una proporción igual al coseno de la latitud. El procedimiento exacto fue el siguiente.
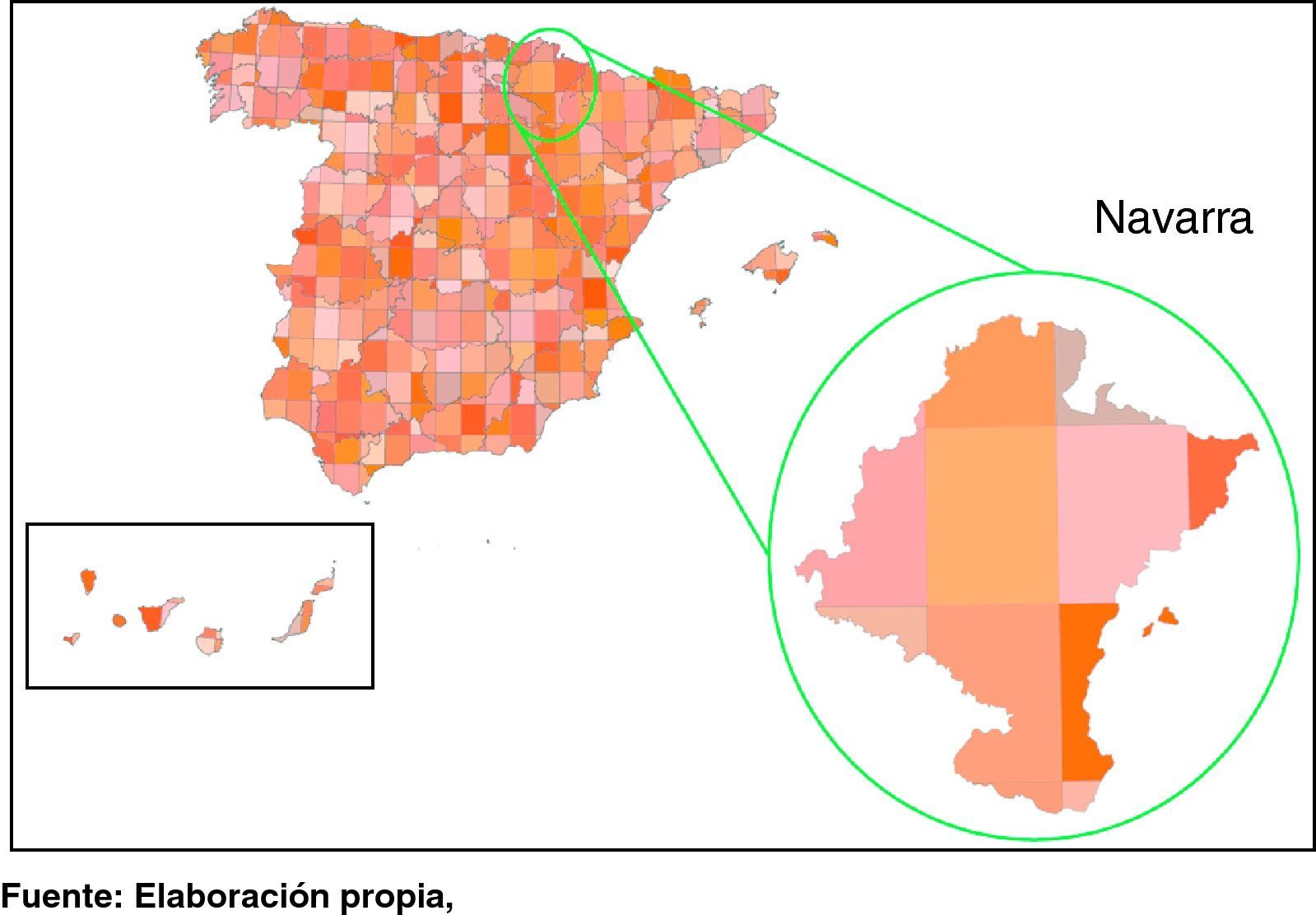
La grid en formato ArcInfo de ESRITM proporcionada por CGIAR-CSI fue transformada a formato vectorial shape de ESRITM y en el que, como atributo, disponíamos del código de enlace de cada celda a los datos climáticos de la grid. Por otra parte disponemos de un fichero vectorial de contornos provinciales, también en formato shape de ESRITM, descargado vía wfs (web feature service) de la Infraestructura de Datos Espaciales (IDEE, http://www.idee.es/) del Instituto Geográfico Nacional (IGN, http://www.ign.es/) y cuyo sistema de referencia geodésico es ED50 en coordenadas geográficas. Este fichero fue transformado al sistema de referencia de la grid CRU TS 2.1, que por tratarse de una grid global es el WGS84. Una vez disponíamos de ambos ficheros en el mismo sistema geodésico, se procedió a realizar una intersección entre los polígonos de la grid y los de las provincias, para a continuación proyectar los datos en UTM (Huso 30N). Una vez efectuada esta proyección se determinó la superficie de cada provincia en cada una de las celdas de la grid, y estas superficies son las que se utilizaron como peso en la construcción de las estadísticas climáticas provinciales.
El resultado de dicho proceso se ilustra en la figura 2, en el que puede verse la provincia de Navarra en términos de las superficies que ocupa en cada celda de la CRU TS 2.1, de esta forma el valor de una variable climática concreta para dicha provincia es un promedio de los valores de las celdas que tienen una intersección no nula con los lindes de la provincia, ponderado por el área correspondiente. Al objeto de poder examinar la variabilidad dentro de un ámbito geográfico determinado, se calculó no solo el promedio, sino también los valores extremos, máximo y mínimo, de las celdas implicadas en el cálculo. El mismo proceso se realizó para los datos de estaciones, lo que permite examinar el número de observaciones directas que entran en la obtención de un valor provincial concreto y que, por las razones explicadas en el epígrafe anterior, puede tomarse con un indicador de la calidad de los datos y su potencial uso en un análisis de series temporales. De esta forma, para cada ámbito territorial considerado es posible obtener un gráfico similar a la figura 1, que nos indique el número promedio de datos de estaciones que entran en el cálculo de un valor concreto para la variable en cuestión.

El número de celdas que pertenecen a las diferentes provincias osciló entre 5 para Guipúzcoa o Vizcaya y 19 para Badajoz17.
El mismo proceso se efectuó para las comunidades autónomas (CC. AA.) y para la Península Ibérica (es decir, excluyendo Illes Balears, Canarias y las ciudades autónomas de Ceuta y Melilla). Finalmente, y aunque no se trata de una región climáticamente coherente, se obtuvieron también datos para el conjunto de España.
En total pues, se disponen de series temporales mensuales de 1.224 observaciones, desde enero de 1901 a diciembre de 2002, para 9 variables climáticas: PRE, TMP, DTR, WET, VAP, CLD, FRS, TMN y TMX y 6 variables de estaciones: PRE, TMP, DTR, WET, VAP y CLD, para los ámbitos regionales de provincias y CC. AA., además de la Península y el conjunto de España. En cada caso se calcula el valor promedio (ponderado por la superficie), así como el valor máximo y mínimo de las celdas implicadas en el cálculo, si bien la base de datos disponible en la web ofrece solo los valores promedio.
La precisión de esta base de datos depende, por supuesto, de la precisión de la grid original, puesto que la primera deriva directamente de la segunda. Las precisiones metodológicas relevantes han sido expuestas en el epígrafe anterior, aunque se recomienda al lector que acuda a las publicaciones originales (New et al., 2000; Mitchell y Jones, 2005), así como a la web donde los datos están accesibles (http://www.cru.uea.ac.uk/cru/data/hrg/), para información adicional.
4Algunas comparacionesAunque el objetivo inicial de este trabajo era la presentación de la base de datos CRU TS 2.1 en un formato accesible a los investigadores sociales, es decir, la translación de una grid geográfica a datos regionales, es conveniente examinar, si quiera de forma muy somera, la conformidad entre la CRU TS 2.1 y algunos de los datos que con frecuencia utilizan historiadores, geógrafos y economistas en relación a la evolución de ciertas características climáticas en nuestro país.
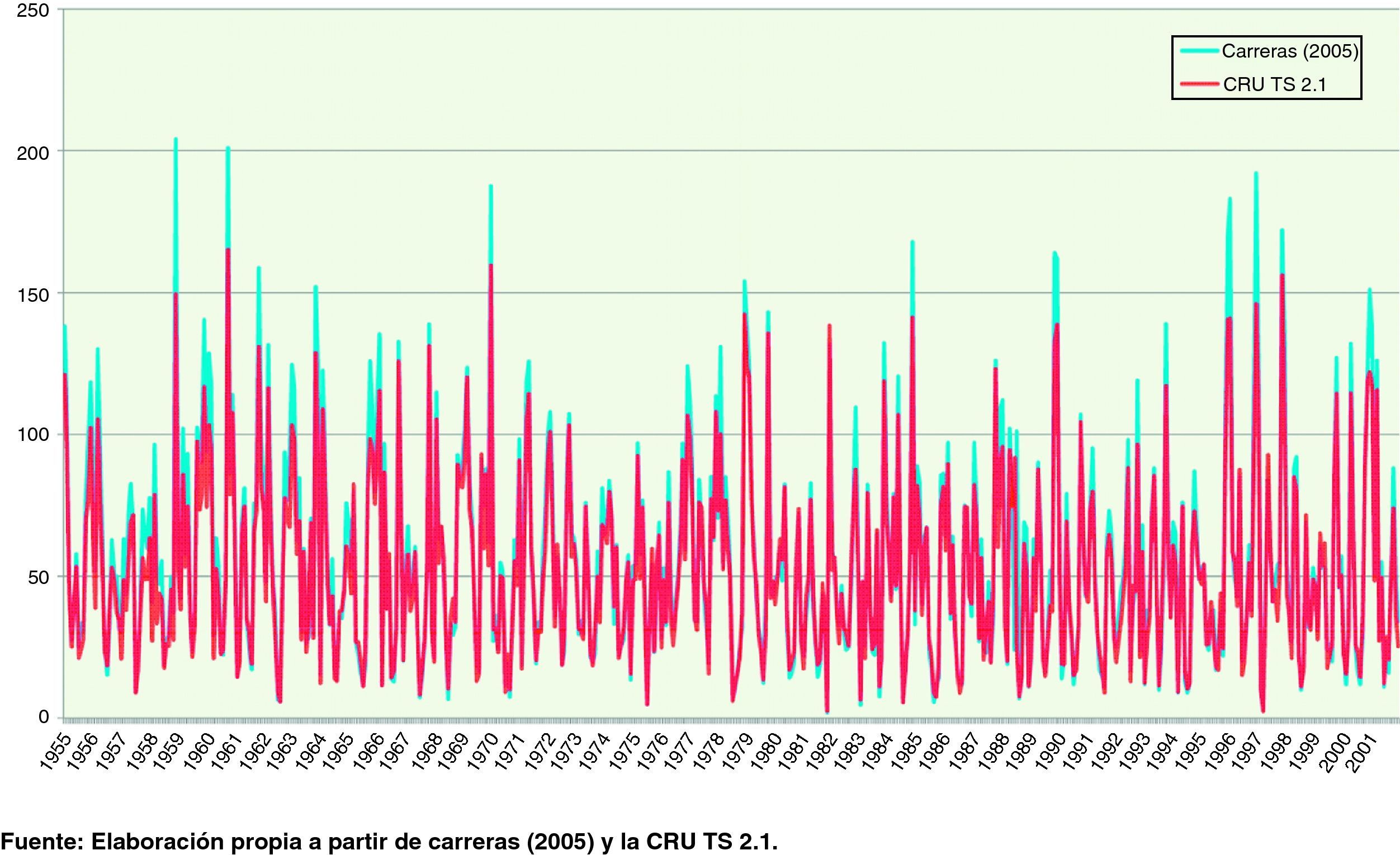
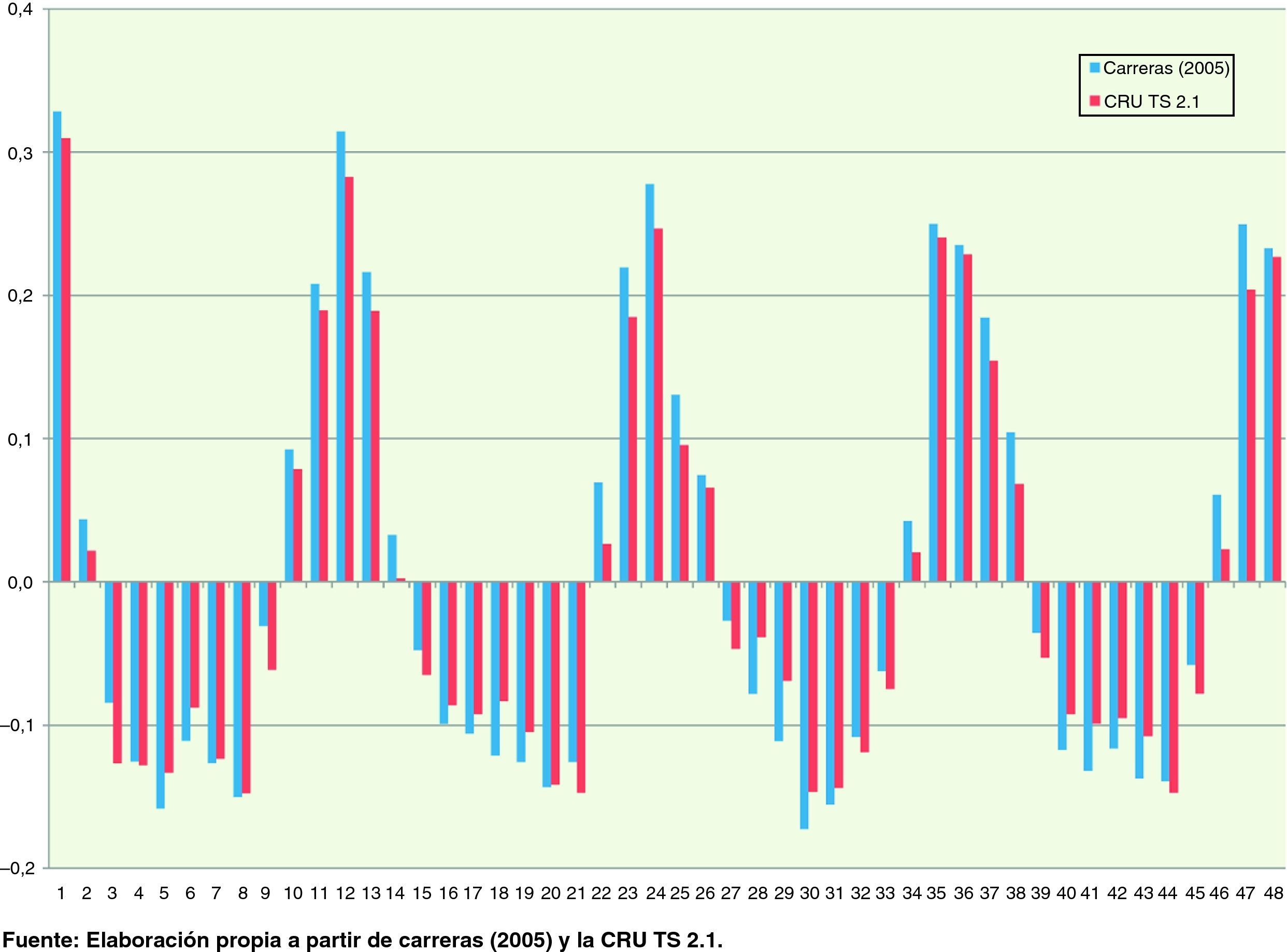
En primer lugar, examinamos brevemente la relación entre la CRU TS 2.1 con los datos de precipitación del cuadro 1.7 de Carreras (2005) que recogen la precipitación acuosa en la España peninsular para el periodo 1955 – 2001, con una frecuencia mensual en litros/m2, y cuya fuente original es el Anuario Estadístico de España del Instituto Nacional de Estadística (INE) y el Calendario Meteorológico del Instituto Nacional de Meteorología (INM). La impresión visual de ambas series se muestra en la figura 3 y se observa claramente un alto grado de conformidad entre las mismas. De hecho el coeficiente de correlación global entre ambas es de 0,976.

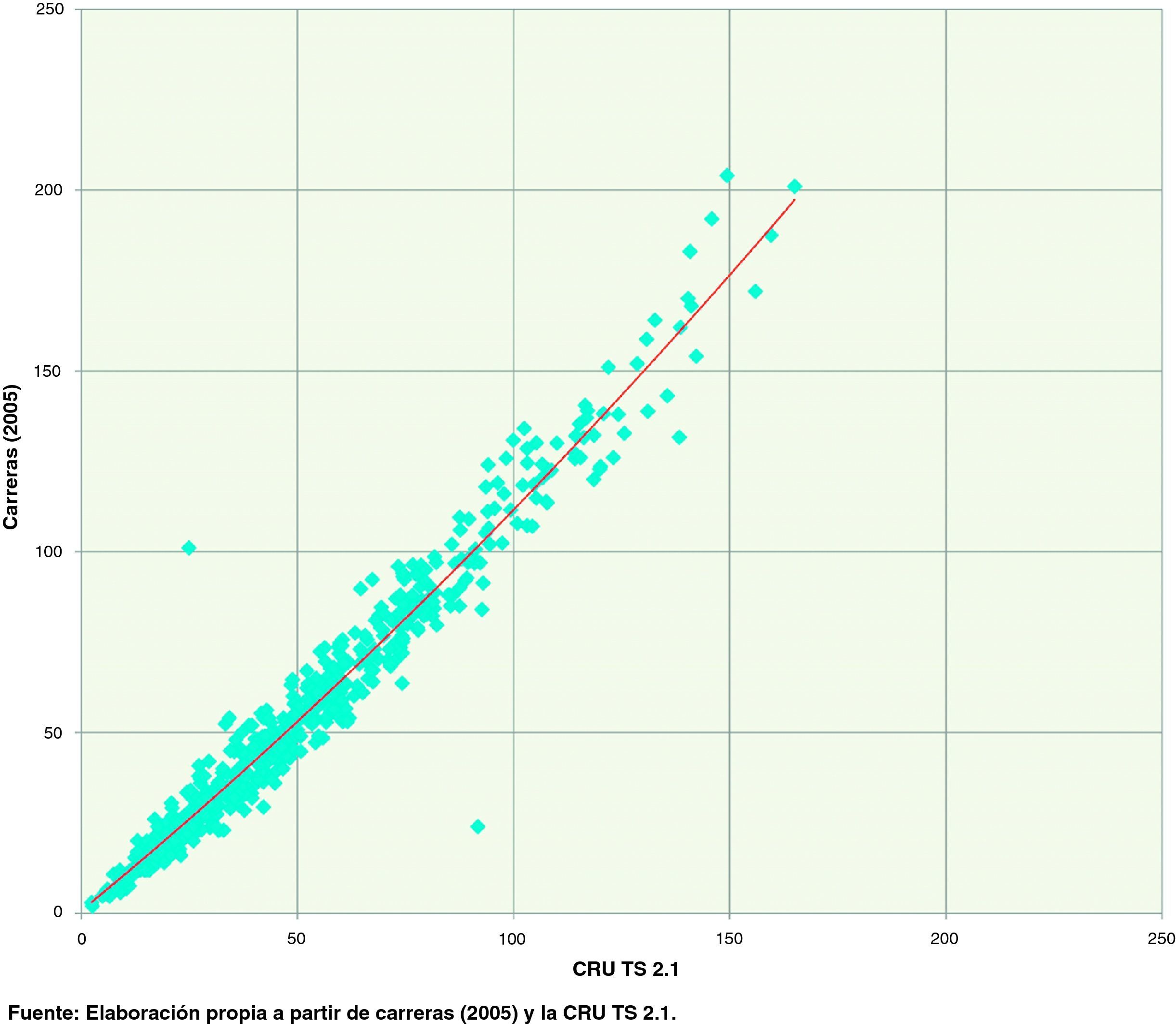
Es posible apreciar, igualmente, que la serie de la CRU TS 2.1 presenta un comportamiento menos extremo en los máximos, como consecuencia, probablemente, del proceso de suavizado en su elaboración, aunque esta característica no parece observarse en los mínimos. Un gráfico de dispersión (fig. 4) revela claramente esta característica: la serie de Carreras (2005), basada directamente en estaciones meteorológicas, tiende a presentar valores mayores conforme crece el nivel de las precipitaciones. La tendencia mostrada en el gráfico se corresponde a una cuadrática y presenta un R2 muy elevado, 0,956; el coeficiente asociado al término cuadrático es significativo (utilizando errores estándares robustos frente a heterocedasticidad de White, 1980), aunque de pequeña magnitud (0,0014), pero la constante, sin embargo, no lo es. La figura 4 permite detectar claramente dos outliers que merecen ser investigados. Al examinar los datos directamente, observamos que se trata de dos meses consecutivos, junio y julio de 1988. En el primer caso, la tabla 1.7 de Carreras (2005, p. 70)18 indica un valor de 24 l/m2, y en el segundo de 101 l/m2; por su parte los valores que hemos obtenido de la CRU TS 2.1 promediando las celdas de la península arrojan valores de 91,8 l/m2 para junio y 24,9 l/m2 para julio. Por tanto, es posible que no se trate de valores discrepantes entre ambas fuente de información, sino de que en los valores originales se haya cometido algún error de transcripción en la información. Puesto que los valores obtenidos de la CRU TS 2.1 se han obtenido promediando un total de 251 celdas parece razonable suponer que dicha errata proceda de la tabla de Carreras (2005) o de las fuentes originales.

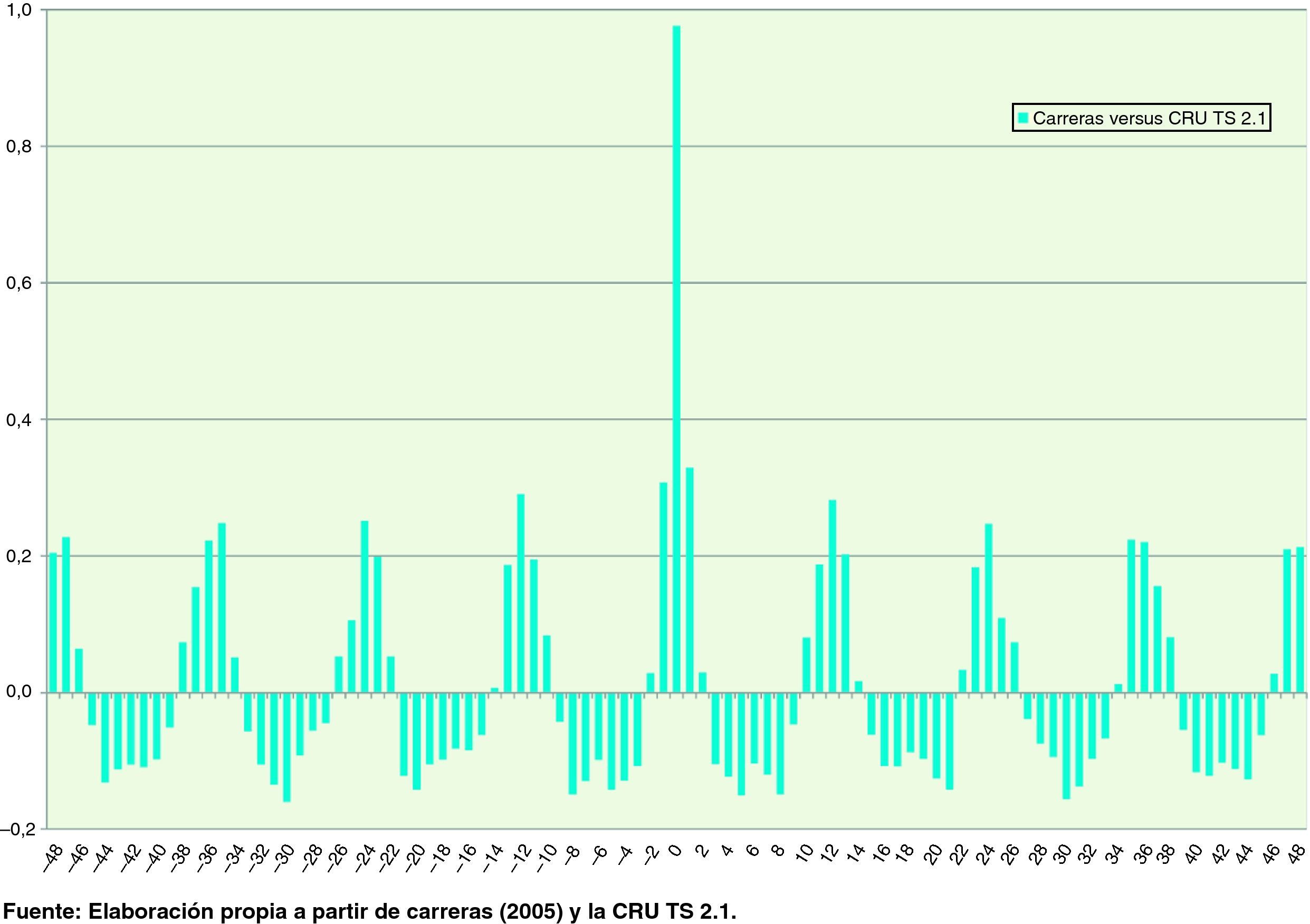
Finalmente, las figuras 5 y 6 ofrecen evidencia adicional de que ambas series tienen propiedades similares en el contexto del análisis de series temporales. La figura 5 muestra las funciones de autocorrelación, con un retardo de hasta orden 48, para las dos series. Ciertamente ambas ofrecen características de autocorrelación muy similares. La correlación entre las funciones de autocorrleacion para estos 48 retardos es de 0,990. Por su parte, la figura 6 muestra la función de autocorrelación cruzada entre las dos series. La coincidencia es máxima, y próxima a la unidad, 0,976, cuando no hay desfase, y muy pequeña en todos los demás casos, donde raramente se observan valores fuera de ± 0,2. Tan solo en los desfases ± 1 se sobrepasa muy ligeramente un valor del coeficiente de correlación cruzada del 0,3.


En definitiva, los resultados apuntan hacia una buena coincidencia entre ambas series, que parecen mantener características de series temporales similares, si bien la serie de precipitaciones de la CRU TS 2.1 tiende a mostrar un comportamiento menos extremo en los valores máximos.
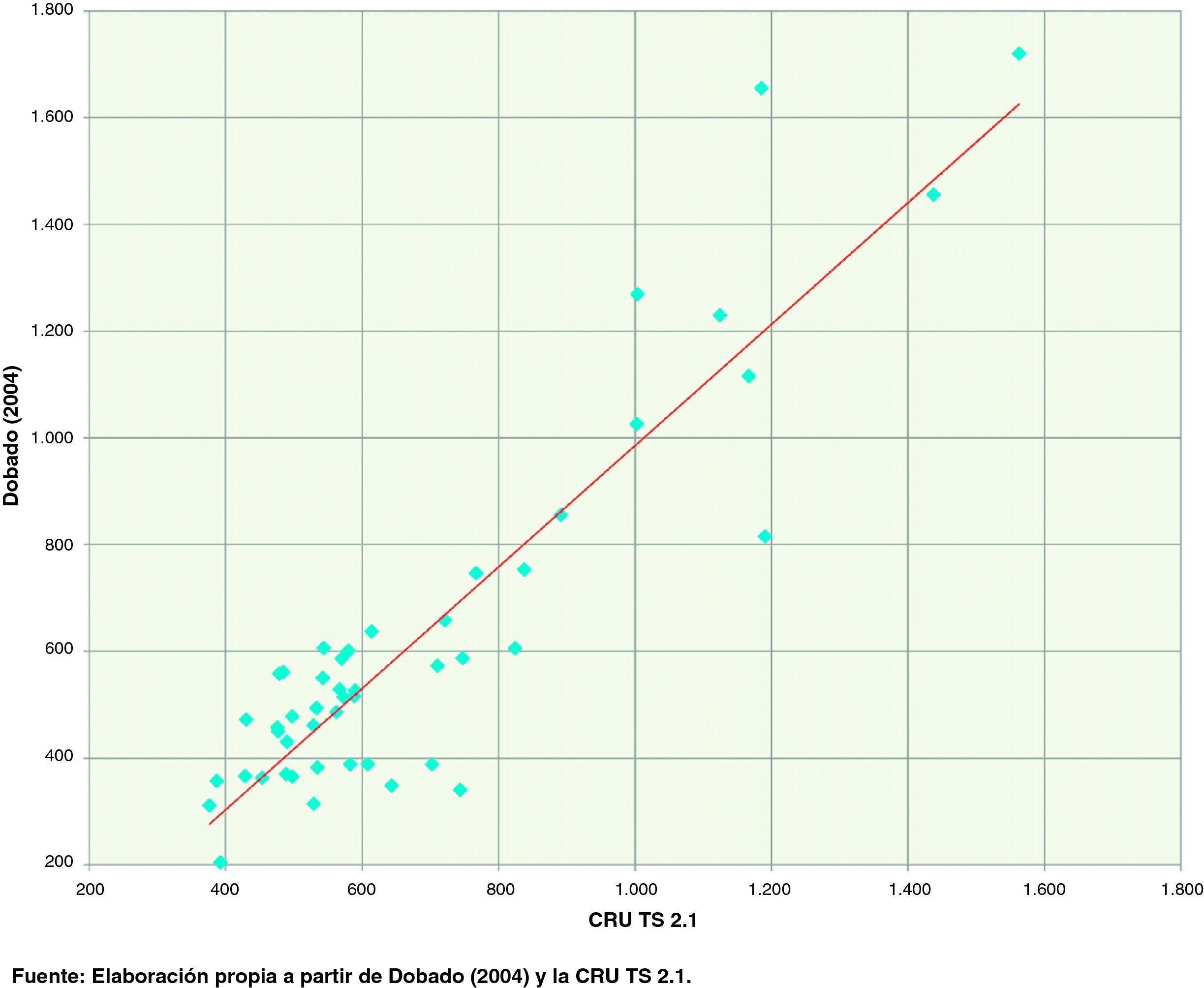
En segundo lugar, examinamos la coherencia en el ámbito regional. Para ello utilizamos los datos de precipitaciones anuales de Dobado González (2004), media 1960–1990, citando como fuente el INM (Dobado González, 2004, p. 117, nota al pie 45) y considerando las 47 provincias peninsulares más Illes Balears19. Obsérvese que este periodo coincide, prácticamente, con el periodo de referencia tomado como base en la CRU TS 2.1, si bien en este caso se mantiene la periodicidad mensual. A partir de la CRU TS 2.1 acumulamos las precipitaciones anualmente para el periodo 1960–1990 y calculamos el promedio de los datos anuales para dicho periodo. La comparación entre los dos conjuntos de datos arrojó un coeficiente de correlación 0,908 y se ofrece en la figura 7.

La consistencia entre ambas variables es elevada, pero menor que en el caso de la comparación vía series temporales. Tomando como base los valores de Dobado González (2004), encontramos 2 casos en los que la CRU TS 2.1 ofrece valores de precipitaciones inferiores en un 20%, Cantabria y Guipúzcoa, por este orden; pero por el contrario encontramos 16 casos en los que la CRU TS 2.1 ofrece precipitaciones superiores en un 20% a los datos de Dobado González (2004), de ellos en 7 provincias la discrepancia es superior al 50%, y en una superior al 100%, Lleida.
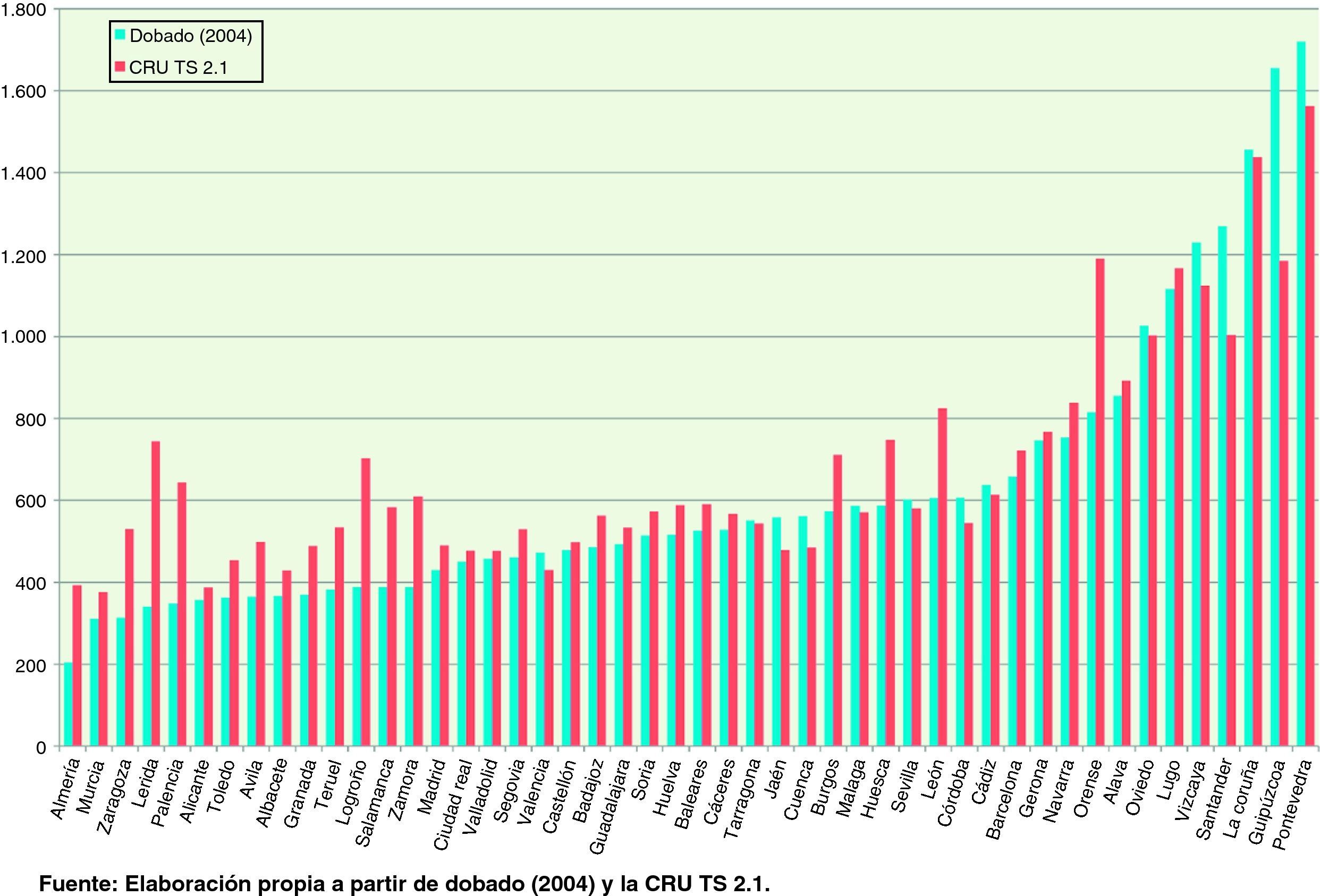
Una forma alternativa de observar ambos conjuntos de datos se ofrece en la figura 8. En ella hemos ordenado de menor a mayor las precipitaciones de Dobado González (2004) y les hemos superpuesto las de la CRU TS 2.1. Se observa como las mayores discrepancias se dan en los extremos de la distribución, por la cola inferior la CRU TS 2.1 parece presentar valores superiores a los ofrecidos por Dobado González (2004), mientras que lo contrario sucede en la cola superior de la distribución, aunque en este caso de forma menos pronunciada. De hecho los datos de la CRU TS 2.1 muestran menor desviación típica que los de Dobado González (2004), 273,3 frente a 342,2, y también menor coeficiente de variación, 0,40 frente a 0,55, ya que la CRU TS 2.1 muestra además mayores precipitaciones medias. El coeficiente de correlación de rangos entre ambas series desciende a 0,752.
 versus CRU TS 2.1.")
Todo ello indica que la relación en el ámbito provincial es elevada, pero parece ser menor que en el caso de las series temporales. Sin duda, el ámbito geográfico importa, ya que como hemos indicado anteriormente es de esperar que la base de datos CRU TS 2.1 presente una menor variabilidad frente a los datos de estaciones directos cuando mayor sea la cobertura geográfica. En cualquier caso en ambas situaciones, series temporales o corte transversal, la CRU TS 2.1 parece presentar un comportamiento menos volátil, al menos en lo que hace referencia a las precipitaciones. Un hecho que parece razonable si se tiene en cuenta que los datos del INM son, en cierta medida, puntuales, mientras que los de la CRU TS 2.1 están sometidos a un proceso de suavizado.
El análisis exploratorio de datos que acabamos de realizar se ha limitado a una sola variable, las precipitaciones, y al periodo más reciente. Piénsese, sin embargo, que las precipitaciones son mucho más difíciles de interpolar que los datos de temperatura, donde el gradiente de altitud juega un claro papel en los modelos climáticos. Por otra parte, el examen de la información de base, mencionado al final del apartado anterior, parece indicar que, tanto para las precipitaciones como para la temperatura, la CRU TS 2.1 ofrece variabilidad, temporal y espacial, que puede ser convenientemente explotada en la explicación de ciertos fenómenos económicos de carácter histórico. Aun así, es conveniente recordar que carecemos de un benchmark de referencia claro, de forma que la comparación de las series aquí presentadas con otros trabajos que han abordado el tema de la homogeneización histórica de series climáticas (Esteban-Parra et al., 1998; Staudt et al., 2007) constituiría una interesante cuestión de investigación.
5ConclusionesEste trabajo ha puesto en un formato accesible para historiadores, geógrafos y economistas una base de datos climática de ámbito histórico y cobertura mundial para su utilización en el tipo de modelos que estos investigadores utilizan, la denominada CRU TS 2.1. Una comparación breve y limitada de las precipitaciones derivadas de esta base de datos muestra una elevada conformidad con los datos directos de estaciones meteorológicas utilizados con más frecuencia por estos investigadores. Sin embargo, tal y como indica la cita de Carreras (2005, p. 46) con la que se iniciaba este trabajo, una mayor comparación entre ambas fuentes de información es no solo posible, sino necesaria. Una elevada coherencia entre las diferentes fuentes de información permitiría extender la información disponible de forma considerable y en un formato regular.
Una cuestión adicional de especial interés, más allá del ámbito de este trabajo, sería examinar hasta qué punto la información estadística española de base podría ser combinada con la grid CRU TS 2.1 para conseguir una mayor resolución espacial, sobre todo en lo que hace referencia a las variables precipitación y temperatura media, que son las más fiables desde un punto de vista de las series temporales y las más requeridas por los investigadores en el campo de las ciencias sociales.
En el ámbito de la Península Ibérica disponemos del Atlas Climático Digital de la Península Ibérica de Ninyerola et al. (2005), una grid climatológica de alta densidad (cuadrícula de 200 m de lado) basada en el periodo 1950–1999 para las variables precipitación, temperatura media, mínima y máxima, y que previsiblemente podría ser utilizada para aumentar la resolución espacial de la CRU TS 2.1, a pesar de la diferente metodología de elaboración. Así por ejemplo, las grids de 1 km se están volviendo cada vez más populares, impulsadas por el interés de la Agencia Europea del Medio Ambiente (http://www.eea.europa.eu/es) en la integración de las estadísticas demográficas y socioeconómicas con las estadísticas medioambientales y de usos del suelo, por lo que sería interesante examinar hasta que resolución podríamos descender razonablemente con este tipo de información auxiliar.
En particular las recopilaciones del Servicio Meteorológico Nacional (1943), González Quijano (1946), Lorente (1961, 1968), Almarza Mata et al. (1996); los trabajos de homogeneización de Esteban-Parra et al. (1998), Staudt (2007), Esteban-Parra y Castro-Díez (2007)20, o el listado de fuentes primarias de Carreras (2005, p. 47), convenientemente geo-referenciadas y depuradas, junto con los trabajos recientes en un contexto de SIG realizados por Pons (1996), Ninyerola et al. (2000, 2007a, 2007b) y Pons y Ninyerola (2008) podrían ser utilizados para aumentar las resolución espacial de la CRU TS 2.1, y quizá también su ámbito temporal hacia el pasado. La propia web del CRU ofrece ciertas indicaciones de cómo hacerlo21, aunque se trataría, sin duda, de una tarea ardua y laboriosa, que requeriría investigadores acostumbrados al manejo de los Sistemas de Información Geográfica.
FinanciaciónSe agradece el apoyo financiero del Ministerio Español de Ciencia y Tecnología, proyecto SEC2008-03813/ECON, y del programa de investigación Fundación BBVA-Ivie.
El autor agradece a Héctor García la ayuda prestada en el manejo informático de la información y a Isidro Cantarino sus comentarios a una versión preliminar de este trabajo. Las sugerencias de tres evaluadores anónimos contribuyeron a mejorar la versión inicial del artículo.
Los ficheros de distribución de la base de datos son del formato PC-Axis (http://www.ine.es/prodyser/pcaxis/pcaxis.htm) y se estructuran en tres ficheros que cubren los valores medios de las 9 variables climáticas consideradas para todo el periodo temporal, 1901:01 a 2002:12, para cada uno de los 3 ámbitos geográficos considerados:
- (i)
Península y España (CRU_TS_2.1_España.px),
- (ii)
Comunidades autónomas (CRU_TS_2.1_CCAA.px), y
- (iii)
Provincias (CRU_TS_2.1_Provincias.px).
Dichos ficheros están disponibles en la web del Instituto Valenciano de Investigaciones Económicas (Ivie, http://www.ivie.es/), y su visualización requiere la instalación del programa PC-Axis.
Adicionalmente, si se dispone del programa PX-Map instalado en el sistema (http://www.ine.es/prodyser/pcaxis/pcaxis.htm#4), añadiendo los ficheros de mapas de CCAA y Provincias (Mapas.zip), disponibles en el mismo lugar que los ficheros de datos, es posible crear mapas con las variables climáticas para estos ámbitos regionales.
Información sobre los valores máximo y mínimo de cada ámbito geográfico, así como sobre los datos de estaciones, e información adicional sobre el proceso de transformación o resultados intermedios pueden solicitarse al autor, Francisco.J.Goerlich@uv.es.
Los datos originales pueden obtenerse de la web del CGIAR-CSIhttp://www.cgiar-csi.org/data/climate/item/52-cru-ts-21-climate-database.
Información y resultados mencionados en el texto, pero no mostrados en el trabajo o disponibles en la base de datos, están accesibles a través del autor. Todos los enlaces de este trabajo son correctos a fecha de diciembre de 2010. Los mapas y figuras se aprecian mucho mejor en la versión electrónica en color del mismo, que en su traslación al papel impreso en blanco y negro.
El esfuerzo es similar al reciente énfasis en la armonización de estadísticas económicas que permitan realizar comparaciones a nivel mundial, como las llevadas a cabo por el Center for International Comparisons de la Universidad de Pennsylvania (CICUP; http://pwt.econ.upenn.edu/), conocidas como la Penn World Table (PWT; http://pwt.econ.upenn.edu/php_site/pwt_index.php), cuya última versión es la PWT 6.3 (Heston et al., 2009).
Véase el listado de fuentes secundarias en Carreras (2005, p. 49).
Aunque la idea de convertir los datos socioeconómicos a una rejilla cartográfica pudiera parecer algo estrambótica, hace tiempo que existen grids de población de cobertura mundial, como LandScanTM del Oak Ridge National Laboratory (ORNL, http://www.ornl.gov/) o la Gridded Population of the World (GPWv3) del Center for International Earth Science Information Network (CIESIN, http://beta.sedac.ciesin.columbia.edu/gpw/) en la Universidad de Columbia (Balk y Yetman, 2004). En el ámbito europeo la European Enviroment Agency (EEA) dispone de una grid poblacional para Europa construida a partir de los datos de Corine Land Cover (CLC) para el año 2001 y con 1 Hectárea de resolución, (http://www.eea.europa.eu/data-and-maps/data/population-density-disaggregated-with-corine-land-cover-2000-2, Gallego, 2010) y Eurostat patrocina actualmente el proyecto EESnet GEOSTAT del European Forum for Geostatistics (EFGS, http://www.efgs.ssb.no/) para la elaboración de una grid europea a partir de los censos de 2011 que vaya más allá de la población.
La conversión de datos de actividad económica a una grid independiente de las fronteras actuales está todavía en la infancia, pero ha pasado de la ciencia ficción a ser un proyecto en marcha que ha recibido la atención de importantes autores interesados en la medición económica. De hecho, el proyecto G-Econ (http://gecon.yale.edu/) del profesor Nordhaus (2006, 2008) tiene como objetivo el desarrollo de una base de datos económico-geofísica, de ámbito mundial y en formato grid, que conforme una nueva métrica: el producto celda bruto (Gross Cell Product, GCP) frente al producto interior bruto (Gross Domestic Product, GDP). Dicho proyecto ya ha dado sus primeros frutos (Nordhaus y Chen, 2009), aunque todo indica que los problemas de datos son sustanciales (Füssel, 2008, 2009). En cualquier caso, dado el reciente debate sobre la importancia relativa de la geografía y las instituciones en la determinación de los patrones de renta per cápita, y el acceso al desarrollo por parte de las economías en un contexto espacio-temporal (Sachs et al., 2000; Acemoglu et al., 2001, 2002; Sachs, 2003), esta línea de investigación continuará con toda probabilidad en el futuro.
La resolución espacial de esta grid fue posteriormente aumentada hasta los 10’ por New et al. (2002), y es conocida como CRU CL 2.0.
Estos autores también aumentaron la resolución espacial para Europa hasta los 10’, dado el mayor número de observaciones de estaciones en esta área (CRU TS 1.2).
En enero de 2010 el CRU hizo pública la versión 3.0 de la CRU TS 3.0, actualizada hasta 2006, y cuyo formato de distribución es diferente del de la CRU TS 2.1. Esta nueva versión puede descargarse en formato raster ASCII de ESRITM, lo que dada la periodicidad temporal significa manipular 1272 ficheros tipo grid por cada variable.
Además de todas estas variables, es posible construir otras variables climáticas derivadas a partir de relaciones empíricas. La web del CRU ofrece cierta información al respecto: http://www.cru.uea.ac.uk/∼timm/grid/faq.html.
Es decir, el atribuible al comportamiento humano o cambio climático en la terminología del IPCC.
Existe en climatología una tendencia a considerar como «valores normales» a los promedios de periodos de 30 años, si bien no todos los autores están de acuerdo con esta práctica (Sanz Donaire, 2008, p. 745, nota al pie 32).
Para una crítica a la utilización de esta base de datos en un análisis causal de series temporales, donde la densidad de estaciones de base es limitada, puede verse Patz et al. (2002).
Esta información se ofrece, con la misma resolución y estructura que los datos originales de las variables climáticas, para las variables: TMP, DTR, PRE, WET, VAP y CLD. Para TMX y TMN los valores coinciden con los de DTR y para FRS no se ofrece información sobre estaciones en la web de donde se obtuvieron los datos (CGIAR-CSI), si bien es posible utilizar los datos de estacionas para TMP o DTR como proxy (comunicación personal de Antonio Trabuco del Consortium for Spatial Information y encargado de la CRU TS 2.1).
La base de datos original proporciona rutinas específicas en Fortran para la lectura y manipulación de los datos en sistemas Unix, dado el tamaño de los ficheros que hay que manejar.
Se excluyen los océanos y la Antártida.
Estas bases de datos utilizan versiones anteriores a la CRU TS 2.1, están disponibles a partir de la web del Climate Research Unit (http://www.cru.uea.ac.uk/cru/data/hrg/) y se las conoce con el acrónimo CRU CY 1.0, 1.1, 2.0 y 3.0.
En el caso de que una celda pertenezca a más de un país esta se asigna al que mayor superficie de la misma ocupa.
Excluyendo Ceuta y Melilla, cuya coherencia climática con el resto de la península es más que dudosa.
A partir del año 1986 se indica en Carreras (2005, p. 71) que desaparece el decimal en la fuente, y por tanto solo disponemos de valores enteros.
Los datos fueron amablemente suministrados por Rafael Dobado a través de Vicente Pinilla.
Estos autores disponen además de intentos de homogeneización histórica de variables climáticas más atrás en el tiempo que pueden resultar de interés para historiadores económicos: Rodrigo et al. (1998) y Rodrigo et al. (1999, 2000).